` 三元组的形式存储。其中,TTL 为该映射关系的生存周期,典型值为 20 分钟,超过该时间,该条目将被丢弃。
+
+ARP 的工作原理将分两种场景讨论:
+
+1. **同一局域网内的 MAC 寻址**;
+2. **从一个局域网到另一个局域网中的网络设备的寻址**。
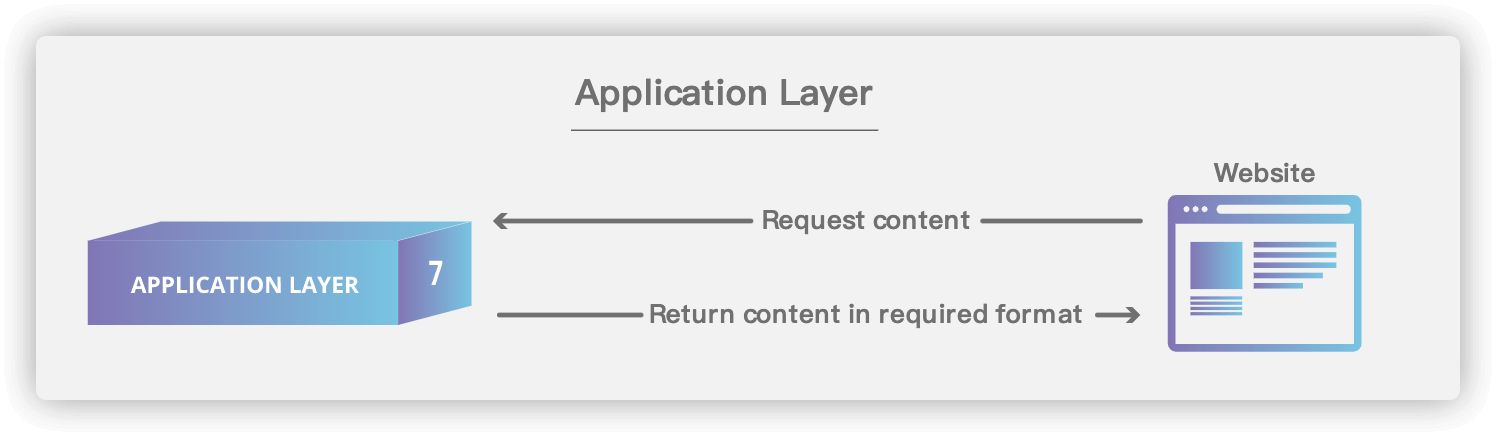
+
+### 同一局域网内的 MAC 寻址
+
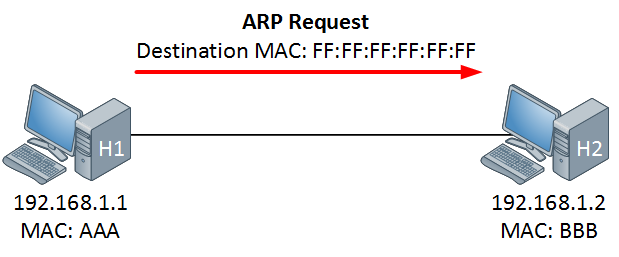
+假设当前有如下场景:IP 地址为 `137.196.7.23` 的主机 A,想要给同一局域网内的 IP 地址为 `137.196.7.14` 主机 B,发送 IP 数据报文。
+
+> 再次强调,当主机发送 IP 数据报文时(网络层),仅知道目的地的 IP 地址,并不清楚目的地的 MAC 地址,而 ARP 协议就是解决这一问题的。
+
+为了达成这一目标,主机 A 将不得不通过 ARP 协议来获取主机 B 的 MAC 地址,并将 IP 报文封装成链路层帧,发送到下一跳上。在该局域网内,关于此将按照时间顺序,依次发生如下事件:
+
+1. 主机 A 检索自己的 ARP 表,发现 ARP 表中并无主机 B 的 IP 地址对应的映射条目,也就无从知道主机 B 的 MAC 地址。
+
+2. 主机 A 将构造一个 ARP 查询分组,并将其广播到所在的局域网中。
+
+ ARP 分组是一种特殊报文,ARP 分组有两类,一种是查询分组,另一种是响应分组,它们具有相同的格式,均包含了发送和接收的 IP 地址、发送和接收的 MAC 地址。当然了,查询分组中,发送的 IP 地址,即为主机 A 的 IP 地址,接收的 IP 地址即为主机 B 的 IP 地址,发送的 MAC 地址也是主机 A 的 MAC 地址,但接收的 MAC 地址绝不会是主机 B 的 MAC 地址(因为这正是我们要问询的!),而是一个特殊值——`FF-FF-FF-FF-FF-FF`,之前说过,该 MAC 地址是广播地址,也就是说,查询分组将广播给该局域网内的所有设备。
+
+3. 主机 A 构造的查询分组将在该局域网内广播,理论上,每一个设备都会收到该分组,并检查查询分组的接收 IP 地址是否为自己的 IP 地址,如果是,说明查询分组已经到达了主机 B,否则,该查询分组对当前设备无效,丢弃之。
+
+4. 主机 B 收到了查询分组之后,验证是对自己的问询,接着构造一个 ARP 响应分组,该分组的目的地只有一个——主机 A,发送给主机 A。同时,主机 B 提取查询分组中的 IP 地址和 MAC 地址信息,在自己的 ARP 表中构造一条主机 A 的 IP-MAC 映射记录。
+
+ ARP 响应分组具有和 ARP 查询分组相同的构造,不同的是,发送和接受的 IP 地址恰恰相反,发送的 MAC 地址为发送者本身,目标 MAC 地址为查询分组的发送者,也就是说,ARP 响应分组只有一个目的地,而非广播。
+
+5. 主机 A 终将收到主机 B 的响应分组,提取出该分组中的 IP 地址和 MAC 地址后,构造映射信息,加入到自己的 ARP 表中。
+
+
+
+在整个过程中,有几点需要补充说明的是:
+
+1. 主机 A 想要给主机 B 发送 IP 数据报,如果主机 B 的 IP-MAC 映射信息已经存在于主机 A 的 ARP 表中,那么主机 A 无需广播,只需提取 MAC 地址并构造链路层帧发送即可。
+2. ARP 表中的映射信息是有生存周期的,典型值为 20 分钟。
+3. 目标主机接收到了问询主机构造的问询报文后,将先把问询主机的 IP-MAC 映射存进自己的 ARP 表中,这样才能获取到响应的目标 MAC 地址,顺利的发送响应分组。
+
+总结来说,ARP 协议是一个**广播问询,单播响应**协议。
+
+### 不同局域网内的 MAC 寻址
+
+更复杂的情况是,发送主机 A 和接收主机 B 不在同一个子网中,假设一个一般场景,两台主机所在的子网由一台路由器联通。这里需要注意的是,一般情况下,我们说网络设备都有一个 IP 地址和一个 MAC 地址,这里说的网络设备,更严谨的说法应该是一个接口。路由器作为互联设备,具有多个接口,每个接口同样也应该具备不重复的 IP 地址和 MAC 地址。因此,在讨论 ARP 表时,路由器的多个接口都各自维护一个 ARP 表,而非一个路由器只维护一个 ARP 表。
+
+接下来,回顾同一子网内的 MAC 寻址,如果主机 A 发送一个广播问询分组,那么 A 所在的子网内所有设备(接口)都将会捕获该分组,因为该分组的目的 IP 与发送主机 A 的 IP 在同一个子网中。但是当目的 IP 与 A 不在同一子网时,A 所在子网内将不会有设备成功接收该分组。那么,主机 A 应该发送怎样的查询分组呢?整个过程按照时间顺序发生的事件如下:
+
+1. 主机 A 查询 ARP 表,期望寻找到目标路由器的本子网接口的 MAC 地址。
+
+ 目标路由器指的是,根据目的主机 B 的 IP 地址,分析出 B 所在的子网,能够把报文转发到 B 所在子网的那个路由器。
+
+2. 主机 A 未能找到目标路由器的本子网接口的 MAC 地址,将采用 ARP 协议,问询到该 MAC 地址,由于目标接口与主机 A 在同一个子网内,该过程与同一局域网内的 MAC 寻址相同。
+
+3. 主机 A 获取到目标接口的 MAC 地址,先构造 IP 数据报,其中源 IP 是 A 的 IP 地址,目的 IP 地址是 B 的 IP 地址,再构造链路层帧,其中源 MAC 地址是 A 的 MAC 地址,目的 MAC 地址是**本子网内与路由器连接的接口的 MAC 地址**。主机 A 将把这个链路层帧,以单播的方式,发送给目标接口。
+
+4. 目标接口接收到了主机 A 发过来的链路层帧,解析,根据目的 IP 地址,查询转发表,将该 IP 数据报转发到与主机 B 所在子网相连的接口上。
+
+ 到此,该帧已经从主机 A 所在的子网,转移到了主机 B 所在的子网了。
+
+5. 路由器接口查询 ARP 表,期望寻找到主机 B 的 MAC 地址。
+
+6. 路由器接口如未能找到主机 B 的 MAC 地址,将采用 ARP 协议,广播问询,单播响应,获取到主机 B 的 MAC 地址。
+
+7. 路由器接口将对 IP 数据报重新封装成链路层帧,目标 MAC 地址为主机 B 的 MAC 地址,单播发送,直到目的地。
+
+
+
+
diff --git "a/docs/cs-basics/network/\350\260\242\345\270\214\344\273\201\350\200\201\345\270\210\347\232\204\343\200\212\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\343\200\213\345\206\205\345\256\271\346\200\273\347\273\223.md" b/docs/cs-basics/network/computer-network-xiexiren-summary.md
similarity index 52%
rename from "docs/cs-basics/network/\350\260\242\345\270\214\344\273\201\350\200\201\345\270\210\347\232\204\343\200\212\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\343\200\213\345\206\205\345\256\271\346\200\273\347\273\223.md"
rename to docs/cs-basics/network/computer-network-xiexiren-summary.md
index df0b07537fd..4fe3b930f2c 100644
--- "a/docs/cs-basics/network/\350\260\242\345\270\214\344\273\201\350\200\201\345\270\210\347\232\204\343\200\212\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\343\200\213\345\206\205\345\256\271\346\200\273\347\273\223.md"
+++ b/docs/cs-basics/network/computer-network-xiexiren-summary.md
@@ -1,95 +1,75 @@
---
-title: 谢希仁老师的《计算机网络》内容总结
+title: 《计算机网络》(谢希仁)内容总结
+description: 基于《计算机网络》教材的学习笔记,梳理术语与分层模型等核心知识点,便于期末复习与面试巩固。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络,谢希仁,术语,分层模型,链路,主机,教材总结
---
+这篇笔记来自我大二学习计算机网络时的整理,大部分内容参考谢希仁老师的[《计算机网络》第七版](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)。
-本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的《计算机网络》这本书。
+计算机网络教材内容很散:术语、分层、链路、路由、运输层、应用层都要串起来看。为了复习起来更顺,我对原来的笔记做了一次重构,并补充了一些示意图。
-为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
+这篇文章主要回答几个问题:
-
+1. 计算机网络里常见基础术语分别是什么意思?
+2. OSI、TCP/IP 分层模型分别如何理解?
+3. 链路层、网络层、运输层、应用层各自解决什么问题?
+4. 复习《计算机网络》这本书时,哪些概念最容易混淆?
-
-
-
-
-- [1. 计算机网络概述](#1-计算机网络概述)
- - [1.1. 基本术语](#11-基本术语)
- - [1.2. 重要知识点总结](#12-重要知识点总结)
-- [2. 物理层(Physical Layer)](#2-物理层physical-layer)
- - [2.1. 基本术语](#21-基本术语)
- - [2.2. 重要知识点总结](#22-重要知识点总结)
- - [2.3. 补充](#23-补充)
- - [2.3.1. 物理层主要做啥?](#231-物理层主要做啥)
- - [2.3.2. 几种常用的信道复用技术](#232-几种常用的信道复用技术)
- - [2.3.3. 几种常用的宽带接入技术,主要是 ADSL 和 FTTx](#233-几种常用的宽带接入技术主要是-adsl-和-fttx)
-- [3. 数据链路层(Data Link Layer)](#3-数据链路层data-link-layer)
- - [3.1. 基本术语](#31-基本术语)
- - [3.2. 重要知识点总结](#32-重要知识点总结)
- - [3.3. 补充](#33-补充)
-- [4. 网络层(Network Layer)](#4-网络层network-layer)
- - [4.1. 基本术语](#41-基本术语)
- - [4.2. 重要知识点总结](#42-重要知识点总结)
-- [5. 传输层(Transport Layer)](#5-传输层transport-layer)
- - [5.1. 基本术语](#51-基本术语)
- - [5.2. 重要知识点总结](#52-重要知识点总结)
- - [5.3. 补充(重要)](#53-补充重要)
-- [6. 应用层(Application Layer)](#6-应用层application-layer)
- - [6.1. 基本术语](#61-基本术语)
- - [6.2. 重要知识点总结](#62-重要知识点总结)
- - [6.3. 补充(重要)](#63-补充重要)
-
-
+
+相关问题:[如何评价谢希仁的计算机网络(第七版)? - 知乎](https://www.zhihu.com/question/327872966) 。
## 1. 计算机网络概述
### 1.1. 基本术语
-1. **结点 (node)** :网络中的结点可以是计算机,集线器,交换机或路由器等。
-2. **链路(link )** : 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
-3. **主机(host)** :连接在因特网上的计算机。
-4. **ISP(Internet Service Provider)** :因特网服务提供者(提供商)。
+1. **结点(node)**:网络中的结点可以是计算机,集线器,交换机或路由器等。
+2. **链路(link)**:从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
+3. **主机(host)**:连接在因特网上的计算机。
+4. **ISP(Internet Service Provider)**:因特网服务提供者(提供商)。
-
+ 
-5. **IXP(Internet eXchange Point)** : 互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
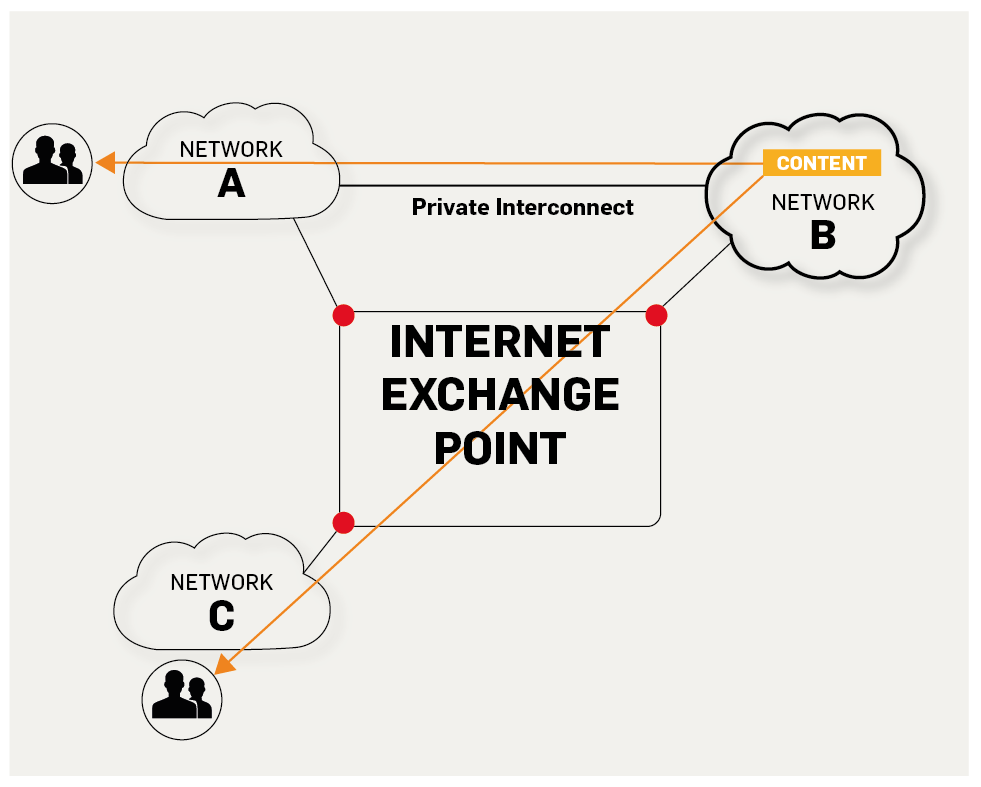
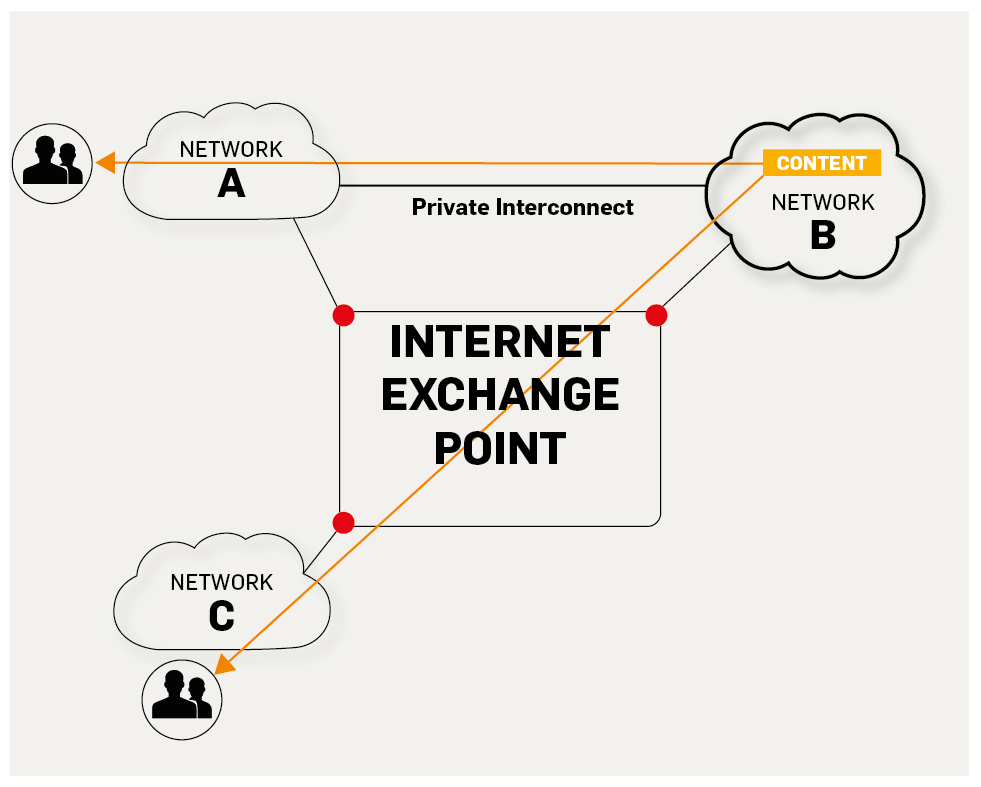
+5. **IXP(Internet eXchange Point)**:互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
-
+ 
-https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive
+ https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive
-6. **RFC(Request For Comments)** :意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
-7. **广域网 WAN(Wide Area Network)** :任务是通过长距离运送主机发送的数据。
+6. **RFC(Request For Comments)**:意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
+7. **广域网 WAN(Wide Area Network)**:任务是通过长距离运送主机发送的数据。
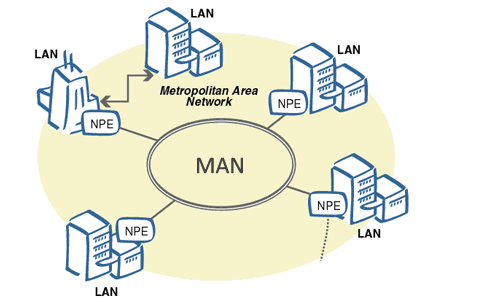
8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
-9. **局域网 LAN(Local Area Network)** : 学校或企业大多拥有多个互连的局域网。
+9. **局域网 LAN(Local Area Network)**:学校或企业大多拥有多个互连的局域网。
-
+ 
-http://conexionesmanwman.blogspot.com/
+ http://conexionesmanwman.blogspot.com/
-10. **个人区域网 PAN(Personal Area Network)** :在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
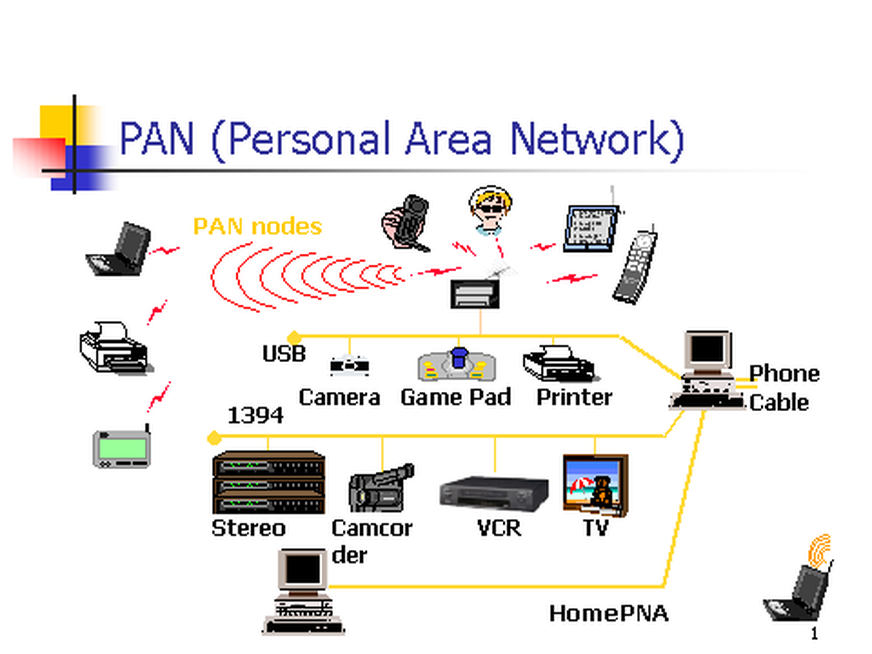
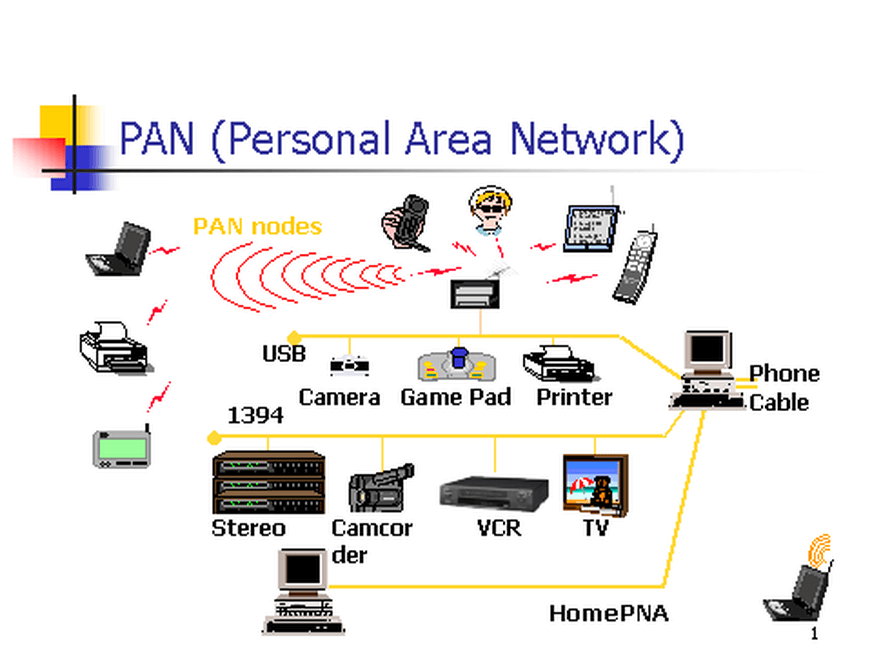
+10. **个人区域网 PAN(Personal Area Network)**:在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络。
-
+ 
-https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/
+ https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/
-12. **分组(packet )** :因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
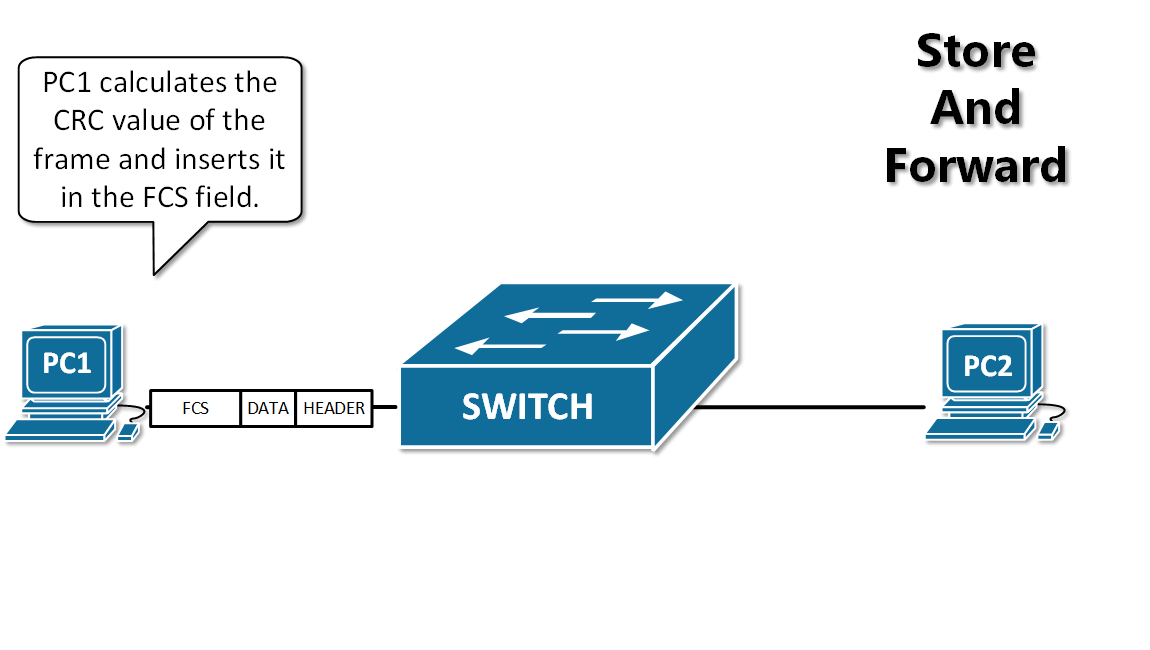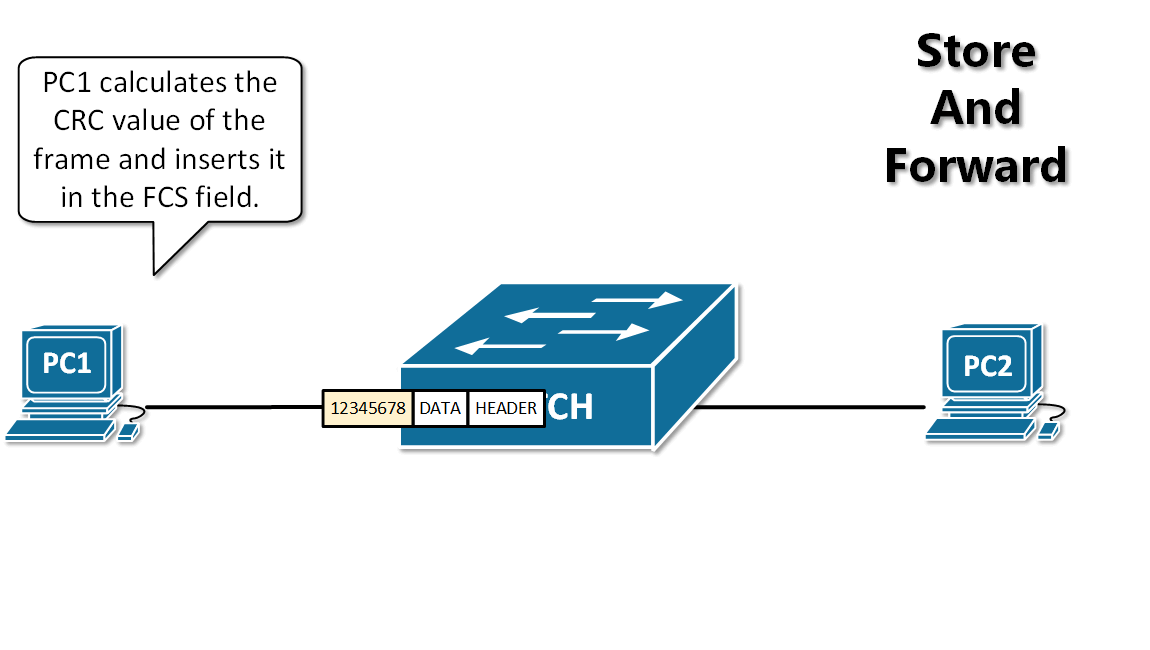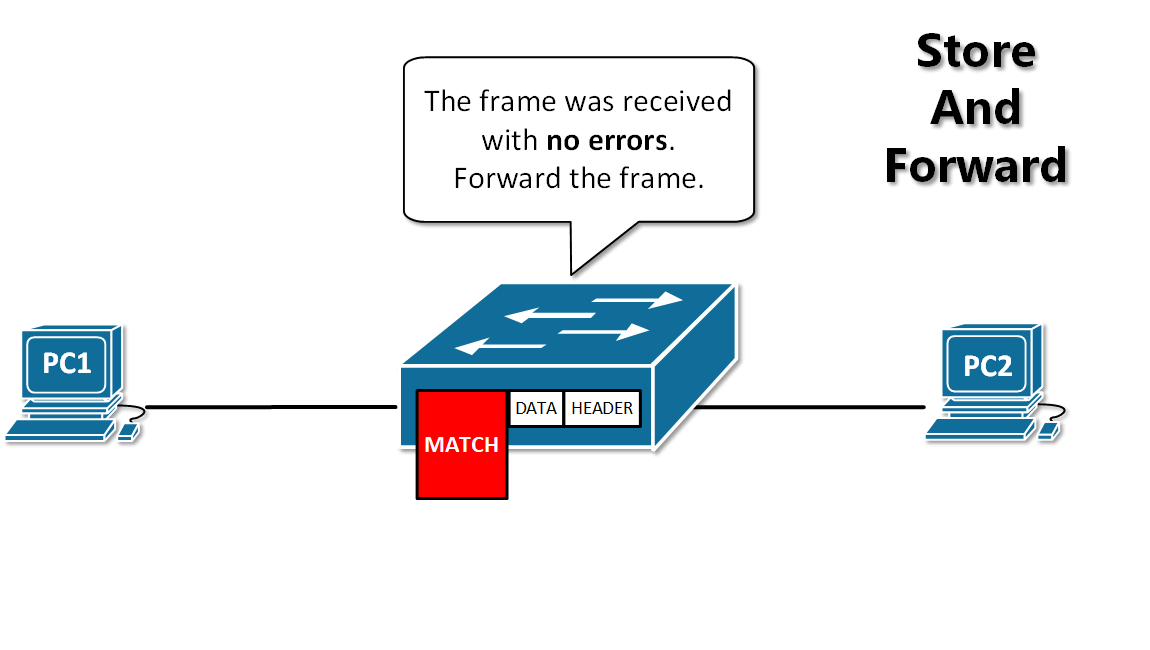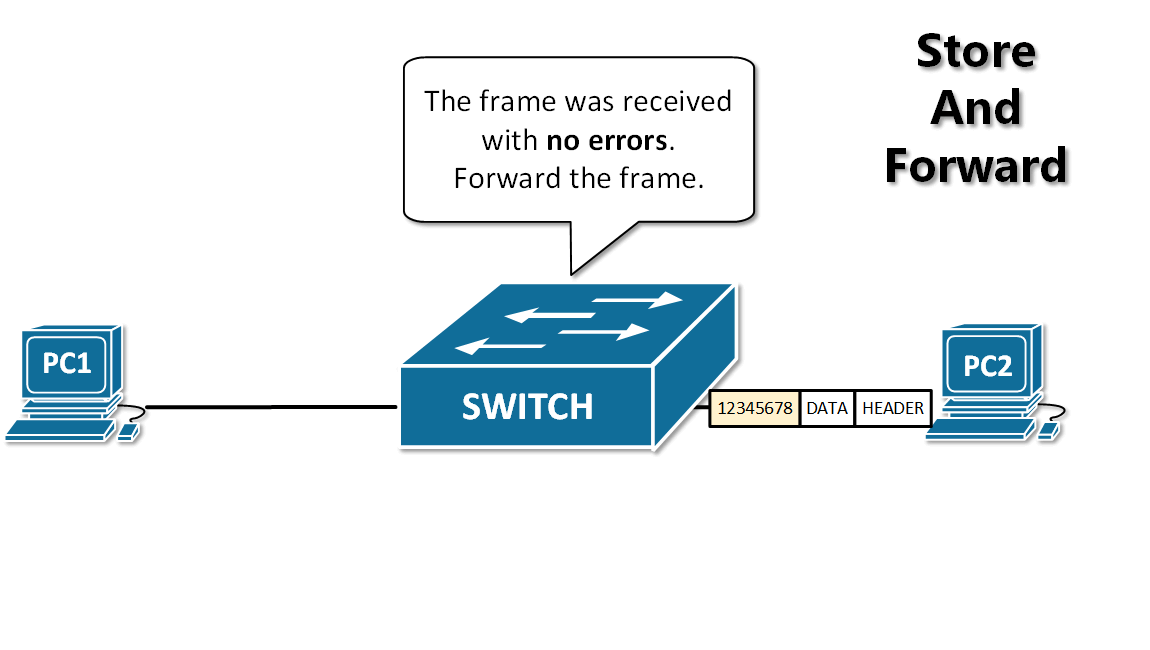
-13. **存储转发(store and forward )** :路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
+11. **分组(packet)**:因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
+12. **存储转发(store and forward)**:路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
-
+ 
-14. **带宽(bandwidth)** :在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
-15. **吞吐量(throughput )** :表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
+13. **带宽(bandwidth)**:在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
+14. **吞吐量(throughput)**:表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
### 1.2. 重要知识点总结
1. **计算机网络(简称网络)把许多计算机连接在一起,而互联网把许多网络连接在一起,是网络的网络。**
2. 小写字母 i 开头的 internet(互联网)是通用名词,它泛指由多个计算机网络相互连接而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。大写字母 I 开头的 Internet(互联网)是专用名词,它指全球最大的,开放的,由众多网络相互连接而成的特定的互联网,并采用 TCP/IP 协议作为通信规则,其前身为 ARPANET。Internet 的推荐译名为因特网,现在一般流行称为互联网。
-3. 路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据端的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
+3. 路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据段的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
4. 互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由器组成核心部分,其作用是提供连通性和交换。
5. 计算机通信是计算机中进程(即运行着的程序)之间的通信。计算机网络采用的通信方式是客户-服务器方式(C/S 方式)和对等连接方式(P2P 方式)。
6. 客户和服务器都是指通信中所涉及的应用进程。客户是服务请求方,服务器是服务提供方。
@@ -98,44 +78,44 @@ tag:
9. 网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
10. **五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是 TCP 和 UDP 协议,网络层最重要的协议是 IP 协议。**
-
+
下面的内容会介绍计算机网络的五层体系结构:**物理层+数据链路层+网络层(网际层)+运输层+应用层**。
## 2. 物理层(Physical Layer)
-
+
### 2.1. 基本术语
-1. **数据(data)** :运送消息的实体。
-2. **信号(signal)** :数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
-3. **码元( code)** :在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
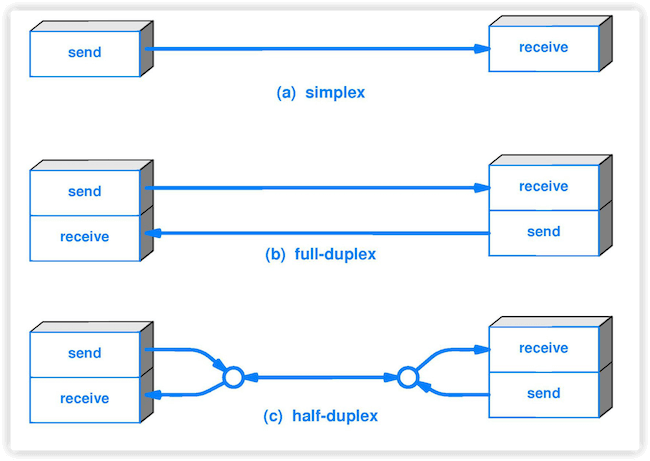
-4. **单工(simplex )** : 只能有一个方向的通信而没有反方向的交互。
-5. **半双工(half duplex )** :通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
-6. **全双工(full duplex)** : 通信的双方可以同时发送和接收信息。
+1. **数据(data)**:运送消息的实体。
+2. **信号(signal)**:数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
+3. **码元(code)**:在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
+4. **单工(simplex)**:只能有一个方向的通信而没有反方向的交互。
+5. **半双工(half duplex)**:通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
+6. **全双工(full duplex)**:通信的双方可以同时发送和接收信息。
-
+ 
7. **失真**:失去真实性,主要是指接受到的信号和发送的信号不同,有磨损和衰减。影响失真程度的因素:1.码元传输速率 2.信号传输距离 3.噪声干扰 4.传输媒体质量
-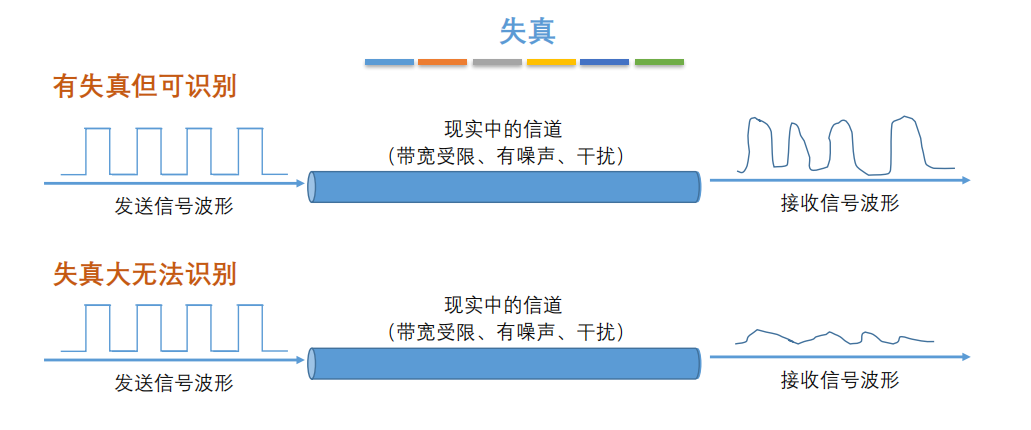
+ 
-8. **奈氏准则** : 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
-9. **香农定理** :在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
-10. **基带信号(baseband signal)** : 来自信源的信号。指没有经过调制的数字信号或模拟信号。
-11. **带通(频带)信号(bandpass signal)** :把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
-12. **调制(modulation )** : 对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
-13. **信噪比(signal-to-noise ratio )** : 指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
-14. **信道复用(channel multiplexing )** :指多个用户共享同一个信道。(并不一定是同时)。
+8. **奈氏准则**:在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
+9. **香农定理**:在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
+10. **基带信号(baseband signal)**:来自信源的信号。指没有经过调制的数字信号或模拟信号。
+11. **带通(频带)信号(bandpass signal)**:把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
+12. **调制(modulation)**:对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
+13. **信噪比(signal-to-noise ratio)**:指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
+14. **信道复用(channel multiplexing)**:指多个用户共享同一个信道。(并不一定是同时)。
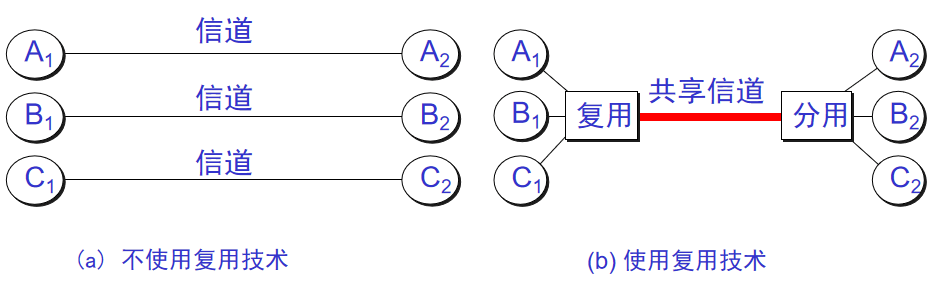
-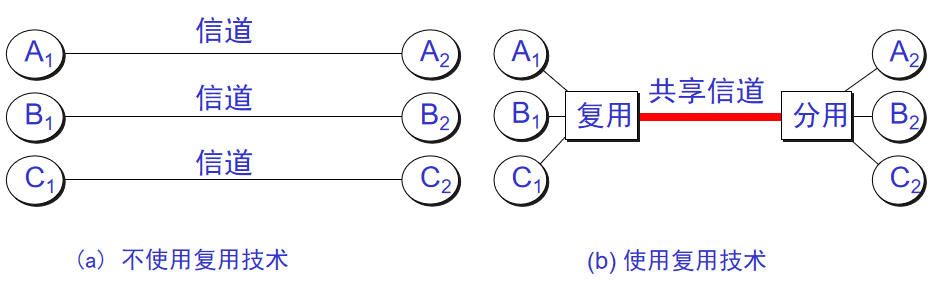
+ 
-15. **比特率(bit rate )** :单位时间(每秒)内传送的比特数。
-16. **波特率(baud rate)** :单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
-17. **复用(multiplexing)** :共享信道的方法。
-18. **ADSL(Asymmetric Digital Subscriber Line )** :非对称数字用户线。
-19. **光纤同轴混合网(HFC 网)** :在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
+15. **比特率(bit rate)**:单位时间(每秒)内传送的比特数。
+16. **波特率(baud rate)**:单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
+17. **复用(multiplexing)**:共享信道的方法。
+18. **ADSL(Asymmetric Digital Subscriber Line)**:非对称数字用户线。
+19. **光纤同轴混合网(HFC 网)**:在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
### 2.2. 重要知识点总结
@@ -159,11 +139,11 @@ tag:
#### 2.3.2. 几种常用的信道复用技术
-1. **频分复用(FDM)** :所有用户在同样的时间占用不同的带宽资源。
-2. **时分复用(TDM)** :所有用户在不同的时间占用同样的频带宽度(分时不分频)。
-3. **统计时分复用 (Statistic TDM)** :改进的时分复用,能够明显提高信道的利用率。
-4. **码分复用(CDM)** : 用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
-5. **波分复用( WDM)** :波分复用就是光的频分复用。
+1. **频分复用(FDM)**:所有用户在同样的时间占用不同的带宽资源。
+2. **时分复用(TDM)**:所有用户在不同的时间占用同样的频带宽度(分时不分频)。
+3. **统计时分复用(Statistic TDM)**:改进的时分复用,能够明显提高信道的利用率。
+4. **码分复用(CDM)**:用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
+5. **波分复用(WDM)**:波分复用就是光的频分复用。
#### 2.3.3. 几种常用的宽带接入技术,主要是 ADSL 和 FTTx
@@ -171,24 +151,24 @@ tag:
## 3. 数据链路层(Data Link Layer)
-
+
### 3.1. 基本术语
-1. **链路(link)** :一个结点到相邻结点的一段物理链路。
-2. **数据链路(data link)** :把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
-3. **循环冗余检验 CRC(Cyclic Redundancy Check)** :为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
-4. **帧(frame)** :一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
-5. **MTU(Maximum Transfer Uint )** :最大传送单元。帧的数据部分的的长度上限。
-6. **误码率 BER(Bit Error Rate )** :在一段时间内,传输错误的比特占所传输比特总数的比率。
-7. **PPP(Point-to-Point Protocol )** :点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
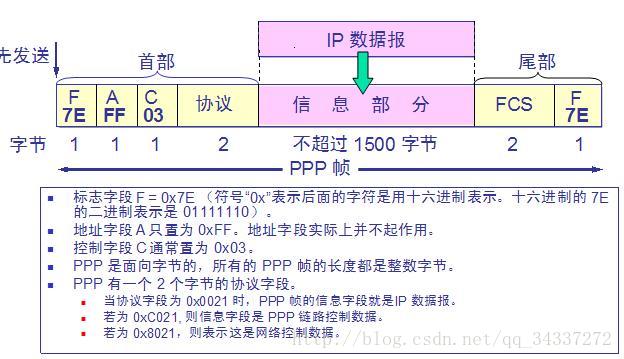
- 
-8. **MAC 地址(Media Access Control 或者 Medium Access Control)** :意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
+1. **链路(link)**:一个结点到相邻结点的一段物理链路。
+2. **数据链路(data link)**:把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
+3. **循环冗余检验 CRC(Cyclic Redundancy Check)**:为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
+4. **帧(frame)**:一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
+5. **MTU(Maximum Transfer Uint)**:最大传送单元。帧的数据部分的长度上限。
+6. **误码率 BER(Bit Error Rate)**:在一段时间内,传输错误的比特占所传输比特总数的比率。
+7. **PPP(Point-to-Point Protocol)**:点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
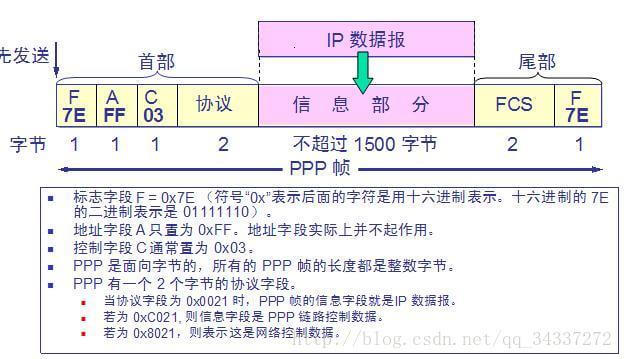
+ 
+8. **MAC 地址(Media Access Control 或者 Medium Access Control)**:意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
-
+ 
-9. **网桥(bridge)** :一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
-10. **交换机(switch )** :广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
+9. **网桥(bridge)**:一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
+10. **交换机(switch)**:广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
### 3.2. 重要知识点总结
@@ -214,22 +194,22 @@ tag:
## 4. 网络层(Network Layer)
-
+
### 4.1. 基本术语
1. **虚电路(Virtual Circuit)** : 在两个终端设备的逻辑或物理端口之间,通过建立的双向的透明传输通道。虚电路表示这只是一条逻辑上的连接,分组都沿着这条逻辑连接按照存储转发方式传送,而并不是真正建立了一条物理连接。
-2. **IP(Internet Protocol )** : 网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一,是 TCP/IP 体系结构网际层的核心。配套的有 ARP,RARP,ICMP,IGMP。
+2. **IP(Internet Protocol)**:网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一,是 TCP/IP 体系结构网际层的核心。配套的有 ARP,RARP,ICMP,IGMP。
3. **ARP(Address Resolution Protocol)** : 地址解析协议。地址解析协议 ARP 把 IP 地址解析为硬件地址。
-4. **ICMP(Internet Control Message Protocol )** :网际控制报文协议 (ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
-5. **子网掩码(subnet mask )** :它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
-6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
-7. **默认路由(default route)** :当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
-8. **路由选择算法(Virtual Circuit)** :路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
+4. **ICMP(Internet Control Message Protocol)**:网际控制报文协议(ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
+5. **子网掩码(subnet mask)**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
+6. **CIDR(Classless Inter-Domain Routing)**:无分类域间路由选择(特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
+7. **默认路由(default route)**:当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
+8. **路由选择算法(Routing Algorithm)**:路由选择协议的核心部分。因特网采用自适应的、分层次的路由选择协议。
### 4.2. 重要知识点总结
-1. **TCP/IP 协议中的网络层向上只提供简单灵活的,无连接的,尽最大努力交付的数据报服务。网络层不提供服务质量的承诺,不保证分组交付的时限所传送的分组可能出错,丢失,重复和失序。进程之间通信的可靠性由运输层负责**
+1. **TCP/IP 协议中的网络层向上只提供简单灵活的,无连接的,尽最大努力交付的数据报服务。网络层不提供服务质量的承诺,不保证分组交付的时限,所传送的分组可能出错、丢失、重复和失序。进程之间通信的可靠性由运输层负责**
2. 在互联网的交付有两种,一是在本网络直接交付不用经过路由器,另一种是和其他网络的间接交付,至少经过一个路由器,但最后一次一定是直接交付
3. 分类的 IP 地址由网络号字段(指明网络)和主机号字段(指明主机)组成。网络号字段最前面的类别指明 IP 地址的类别。IP 地址是一种分等级的地址结构。IP 地址管理机构分配 IP 地址时只分配网络号,主机号由得到该网络号的单位自行分配。路由器根据目的主机所连接的网络号来转发分组。一个路由器至少连接到两个网络,所以一个路由器至少应当有两个不同的 IP 地址
4. IP 数据报分为首部和数据两部分。首部的前一部分是固定长度,共 20 字节,是所有 IP 数据包必须具有的(源地址,目的地址,总长度等重要地段都固定在首部)。一些长度可变的可选字段固定在首部的后面。IP 首部中的生存时间给出了 IP 数据报在互联网中所能经过的最大路由器数。可防止 IP 数据报在互联网中无限制的兜圈子。
@@ -242,22 +222,22 @@ tag:
## 5. 传输层(Transport Layer)
-
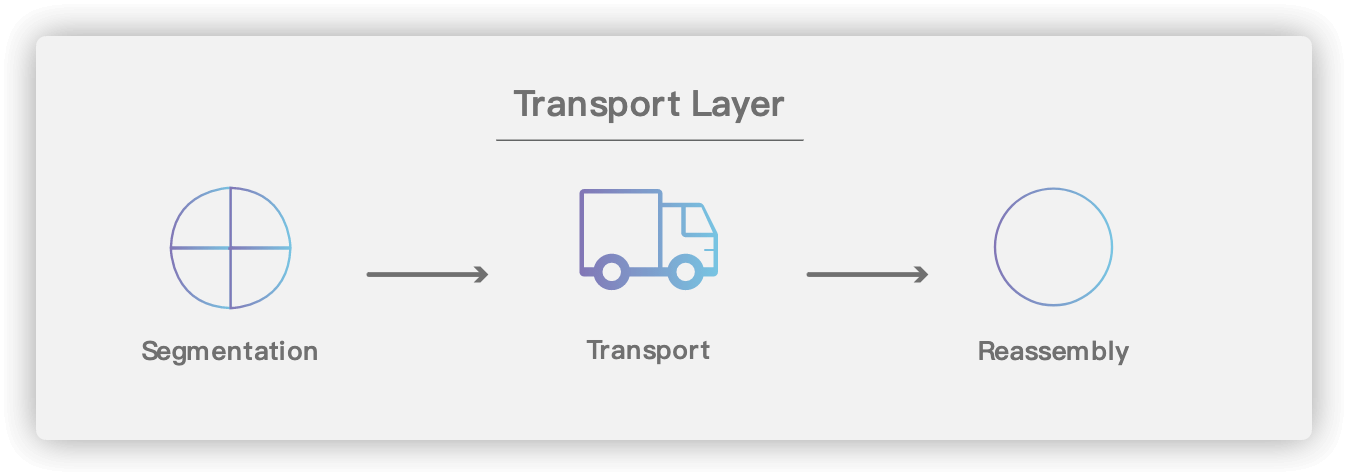
+
### 5.1. 基本术语
-1. **进程(process)** :指计算机中正在运行的程序实体。
-2. **应用进程互相通信** :一台主机的进程和另一台主机中的一个进程交换数据的过程(另外注意通信真正的端点不是主机而是主机中的进程,也就是说端到端的通信是应用进程之间的通信)。
-3. **传输层的复用与分用** :复用指发送方不同的进程都可以通过同一个运输层协议传送数据。分用指接收方的运输层在剥去报文的首部后能把这些数据正确的交付到目的应用进程。
-4. **TCP(Transmission Control Protocol)** :传输控制协议。
-5. **UDP(User Datagram Protocol)** :用户数据报协议。
+1. **进程(process)**:指计算机中正在运行的程序实体。
+2. **应用进程互相通信**:一台主机的进程和另一台主机中的一个进程交换数据的过程(另外注意通信真正的端点不是主机而是主机中的进程,也就是说端到端的通信是应用进程之间的通信)。
+3. **传输层的复用与分用**:复用指发送方不同的进程都可以通过同一个运输层协议传送数据。分用指接收方的运输层在剥去报文的首部后能把这些数据正确的交付到目的应用进程。
+4. **TCP(Transmission Control Protocol)**:传输控制协议。
+5. **UDP(User Datagram Protocol)**:用户数据报协议。
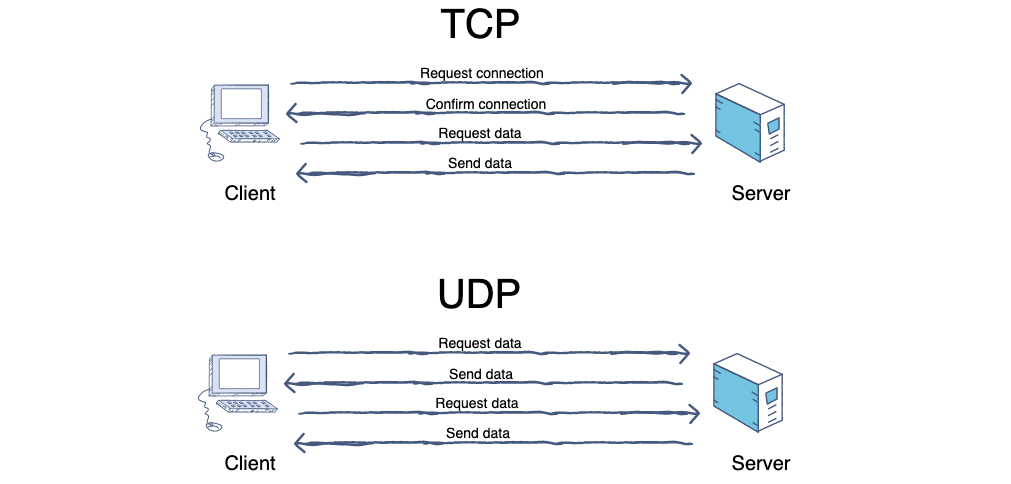
-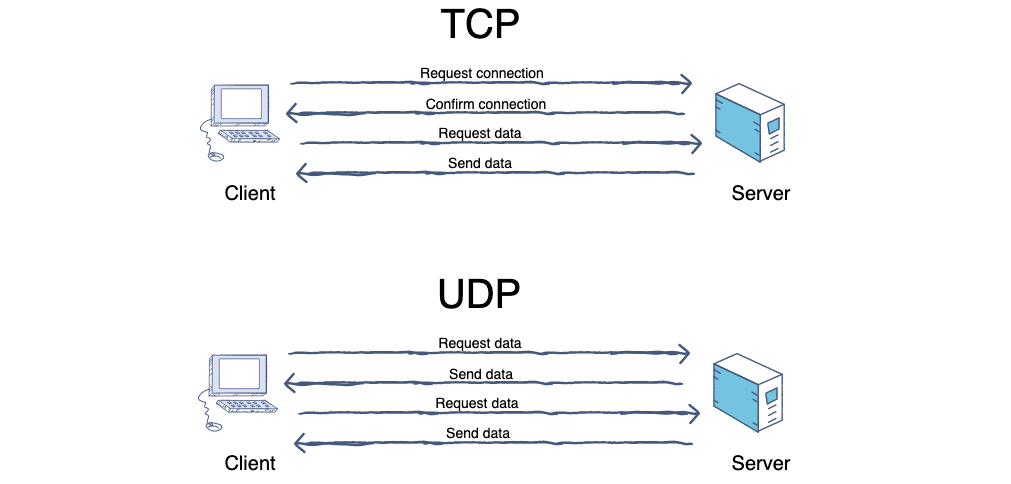
+ 
-6. **端口(port)** :端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
-7. **停止等待协议(stop-and-wait)** :指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
-8. **流量控制** : 就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。
-9. **拥塞控制** :防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
+6. **端口(port)**:端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
+7. **停止等待协议(stop-and-wait)**:指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
+8. **流量控制**:就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。
+9. **拥塞控制**:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
### 5.2. 重要知识点总结
@@ -274,7 +254,7 @@ tag:
11. 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
12. 为了提高传输效率,发送方可以不使用低效率的停止等待协议,而是采用流水线传输。流水线传输就是发送方可连续发送多个分组,不必每发完一个分组就停下来等待对方确认。这样可使信道上一直有数据不间断的在传送。这种传输方式可以明显提高信道利用率。
13. 停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求 ARQ。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。连续 ARQ 协议可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
-14. TCP 报文段的前 20 个字节是固定的,后面有 4n 字节是根据需要增加的选项。因此,TCP 首部的最小长度是 20 字节。
+14. TCP 报文段的前 20 个字节是固定的,其后有 40 字节长度的可选字段。如果加入可选字段后首部长度不是 4 的整数倍字节,需要在再在之后用 0 填充。因此,TCP 首部的长度取值为 20+4n 字节,最长为 60 字节。
15. **TCP 使用滑动窗口机制。发送窗口里面的序号表示允许发送的序号。发送窗口后沿的后面部分表示已发送且已收到确认,而发送窗口前沿的前面部分表示不允许发送。发送窗口后沿的变化情况有两种可能,即不动(没有收到新的确认)和前移(收到了新的确认)。发送窗口的前沿通常是不断向前移动的。一般来说,我们总是希望数据传输更快一些。但如果发送方把数据发送的过快,接收方就可能来不及接收,这就会造成数据的丢失。所谓流量控制就是让发送方的发送速率不要太快,要让接收方来得及接收。**
16. 在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
17. **为了进行拥塞控制,TCP 发送方要维持一个拥塞窗口 cwnd 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。**
@@ -295,48 +275,46 @@ tag:
## 6. 应用层(Application Layer)
-
+
### 6.1. 基本术语
-1. **域名系统(DNS)** :域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
+1. **域名系统(DNS)**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
-
+ 
-https://www.seobility.net/en/wiki/HTTP_headers
+ https://www.seobility.net/en/wiki/HTTP_headers
-2. **文件传输协议(FTP)** :FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
+2. **文件传输协议(FTP)**:FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:“下载”(Download)和“上传”(Upload)。 “下载”文件就是从远程主机拷贝文件至自己的计算机上;“上传”文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
-
+ 
-3. **简单文件传输协议(TFTP)** :TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
-4. **远程终端协议(TELNET)** :Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
-5. **万维网(WWW)** :WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
+3. **简单文件传输协议(TFTP)**:TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
+4. **远程终端协议(TELNET)**:Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
+5. **万维网(WWW)**:WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,“环球网”等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
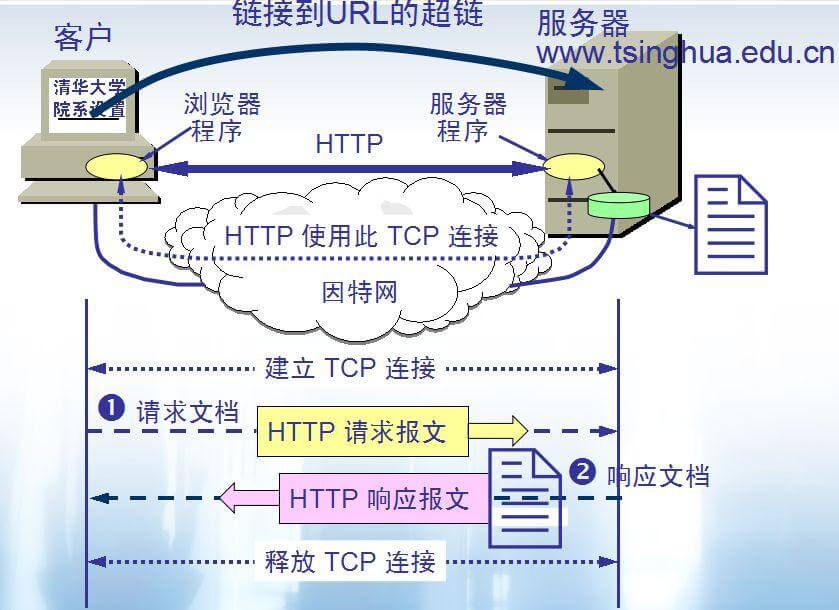
6. **万维网的大致工作工程:**
-
+ 
-7. **统一资源定位符(URL)** :统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
-8. **超文本传输协议(HTTP)** :超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
+7. **统一资源定位符(URL)**:统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
+8. **超文本传输协议(HTTP)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
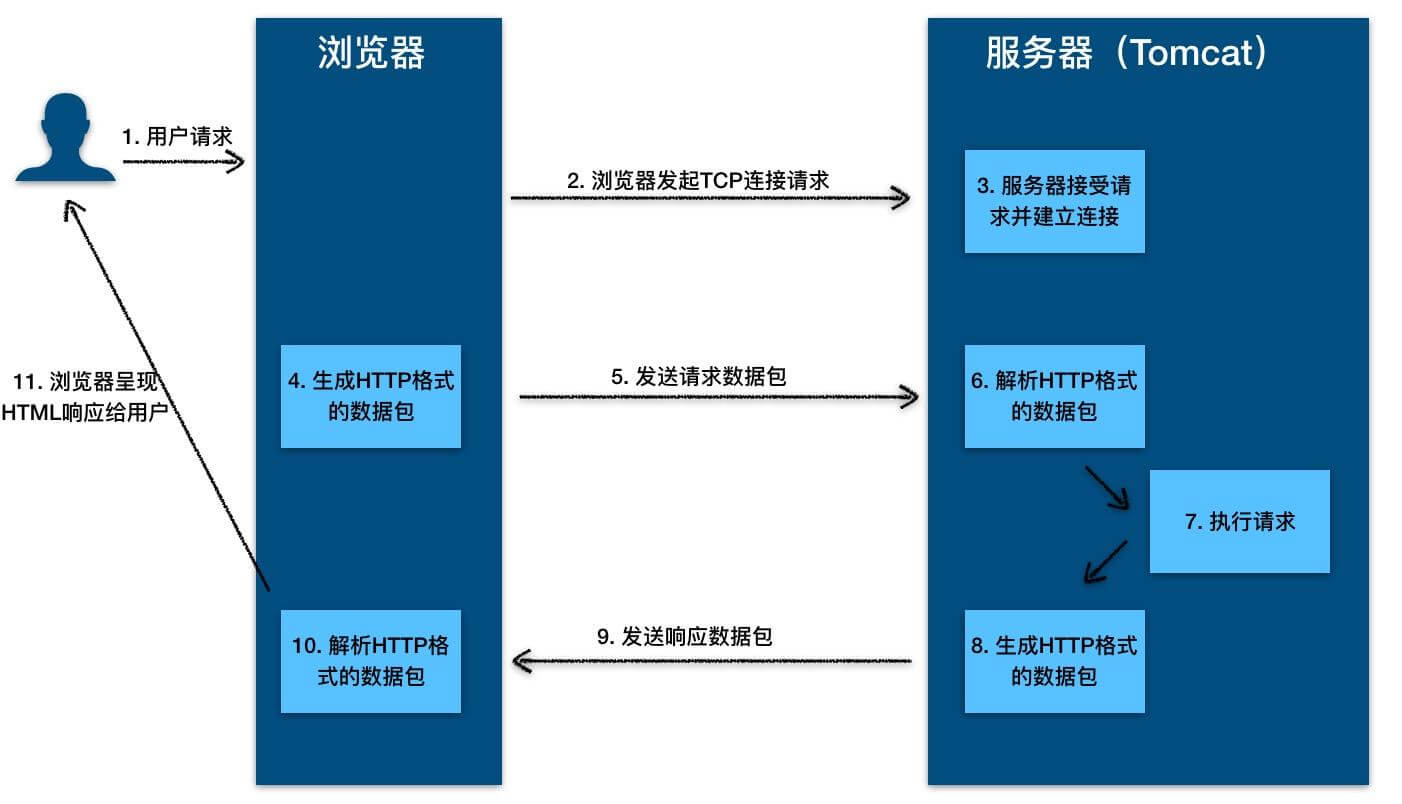
-HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
+ HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
-
+ 
-10. **代理服务器(Proxy Server)** : 代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
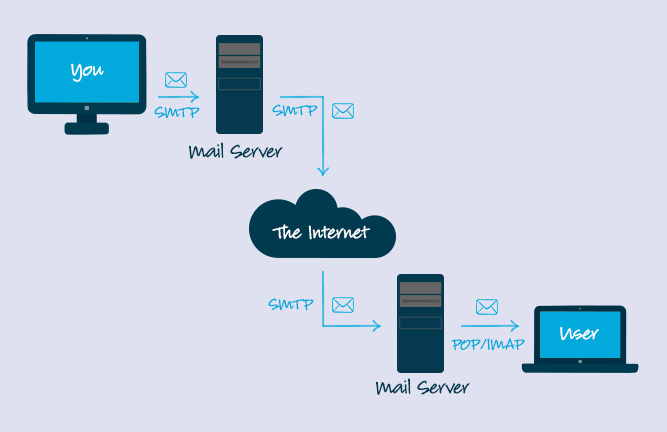
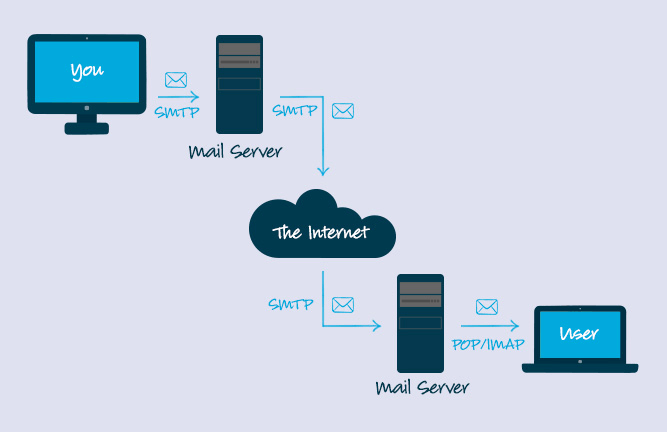
-11. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
+9. **代理服务器(Proxy Server)**:代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
+10. **简单邮件传输协议(SMTP)**:SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
-
+ 
-https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/
+
https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/
-11. **搜索引擎** :搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
+11. **搜索引擎**:搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
-
-
-12. **垂直搜索引擎** :垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
+12. **垂直搜索引擎**:垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
-14. **目录索引** :目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
+14. **目录索引**:目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
### 6.2. 重要知识点总结
@@ -353,3 +331,5 @@ HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格
2. 域名系统-从域名解析出 IP 地址
3. 访问一个网站大致的过程
4. 系统调用和应用编程接口概念
+
+
diff --git a/docs/cs-basics/network/dns.md b/docs/cs-basics/network/dns.md
new file mode 100644
index 00000000000..1f60f52e1e9
--- /dev/null
+++ b/docs/cs-basics/network/dns.md
@@ -0,0 +1,134 @@
+---
+title: DNS 域名系统详解(应用层)
+description: 详解 DNS 的层次结构与解析流程,覆盖递归/迭代、缓存与权威服务器,明确应用层端口与性能优化要点。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: DNS,域名解析,递归查询,迭代查询,缓存,权威DNS,端口53,UDP
+---
+
+在浏览器地址栏输入域名之后,真正发起 HTTP 请求之前,通常要先经过 DNS 解析。
+
+DNS 要解决的是**域名和 IP 地址的映射问题**。它看起来只是“把域名翻译成 IP”,但背后涉及本地缓存、递归查询、迭代查询、权威服务器、根服务器、UDP/TCP 切换等一整套机制。
+
+这篇文章主要回答几个问题:
+
+1. DNS 为什么需要分层设计?
+2. 一次完整的域名解析通常会经过哪些步骤?
+3. 递归查询和迭代查询有什么区别?
+4. DNS 为什么通常基于 UDP,什么情况下会改用 TCP?
+
+
+
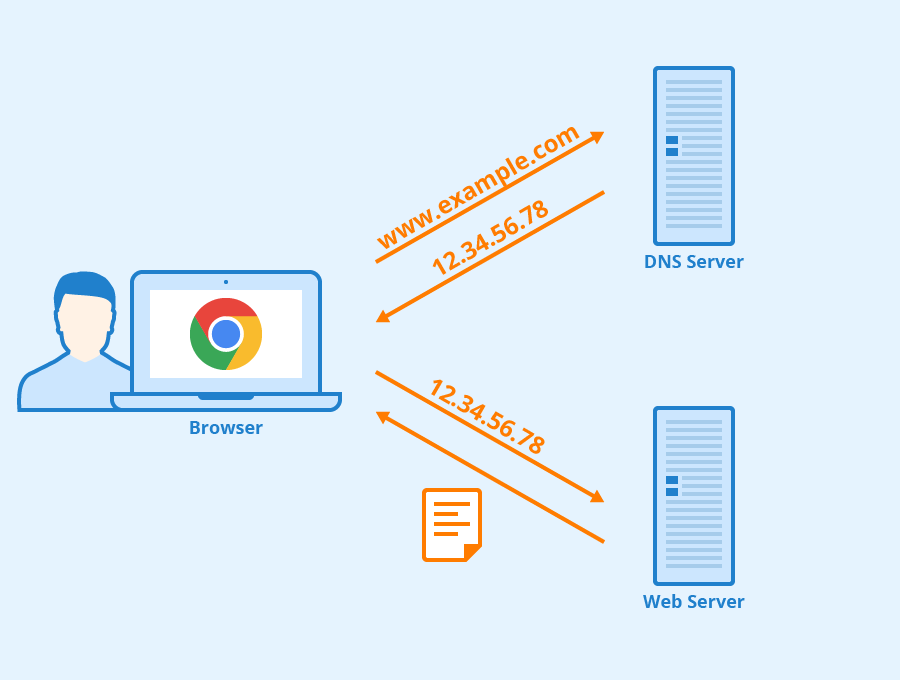
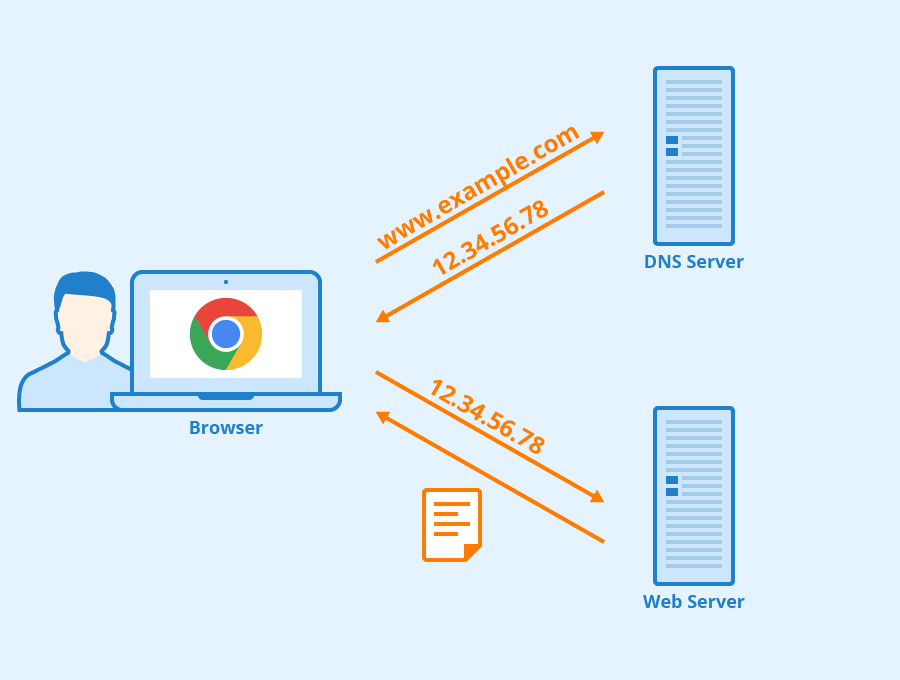
+在实际使用中,有一种情况下,浏览器是可以不必动用 DNS 就可以获知域名和 IP 地址的映射的。浏览器在本地会维护一个 `hosts` 列表,一般来说浏览器要先查看要访问的域名是否在 `hosts` 列表中,如果有的话,直接提取对应的 IP 地址记录,就好了。如果本地 `hosts` 列表内没有域名-IP 对应记录的话,那么 DNS 就闪亮登场了。
+
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,通常基于 UDP 协议,端口为 53**。当响应数据超过 UDP 报文长度限制(512 字节,EDNS0 可扩展至更大)或进行区域传送(Zone Transfer)时,会改用 TCP 协议以保证数据完整性。
+
+
+
+## DNS 服务器
+
+DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
+
+- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
+- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如 `com`、`org`、`net` 和 `edu` 等。国家也有自己的顶级域,如 `uk`、`fr` 和 `ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
+- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
+- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构。
+
+**世界上真的只有 13 台根服务器吗?** 这是一个流传已久的技术误解。如果你在网上搜索,仍能看到许多陈旧文章宣称“全球仅有 13 台根服务器,且全部由美国控制”。
+
+**事实并非如此。**
+
+最初在设计 DNS(域名系统)架构时,受限于早期 IPv4 数据包的大小限制(UDP 报文需控制在 512 字节以内),预留给根服务器地址的空间确实只够容纳 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。这 13 个地址分别被命名为 `a.root-servers.net` 到 `m.root-servers.net`。
+
+虽然**逻辑上**只有 13 个 IP 地址,但随着互联网规模的爆发,物理上的“单一服务器”早已无法承载全球的查询压力。为了提升 DNS 的可靠性、安全性和响应速度,技术人员引入了 **IP 任播(Anycast)** 技术。
+
+通过任播技术,每一个逻辑 IP 地址背后都可以对应成百上千台分布在全球各地的物理服务器。当你发起查询请求时,互联网路由协议(BGP)会自动将请求引导至地理位置或网络路径上离你**最近**的那台物理实例。
+
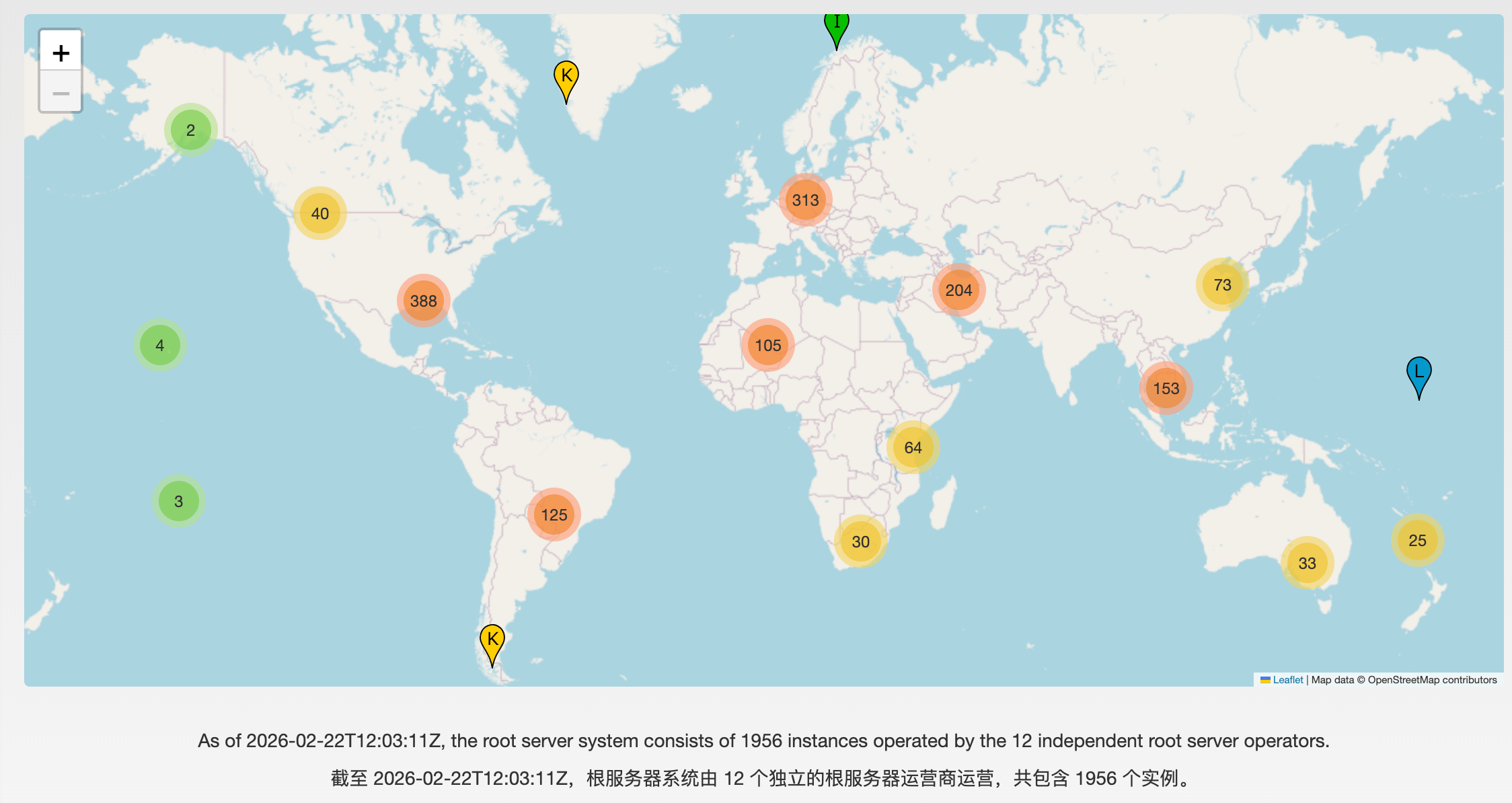
+截止到 2023 年底,全球根服务器物理实例总数已超过 1700 台。根据 **[Root-Servers.org](https://root-servers.org/)** 的最新实时监测数据,到 **2026 年,全球根服务器物理实例已突破 1900+ 台**,并正向 2000 台大关迈进。
+
+
+
+## DNS 工作流程
+
+以下图为例,介绍 DNS 的查询解析过程。DNS 的查询解析过程分为两种模式:
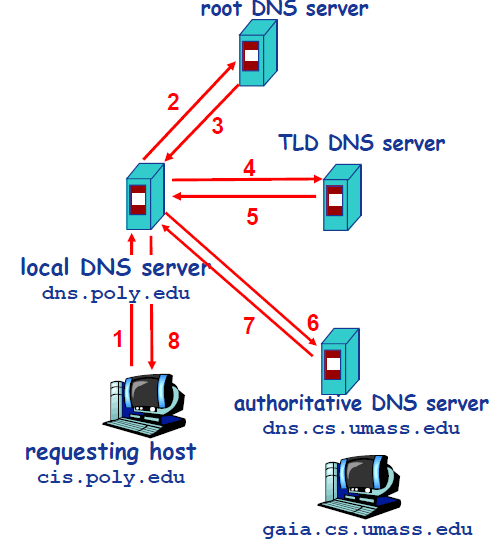
+
+- **迭代**
+- **递归**
+
+下图是实践中常采用的方式,从请求主机到本地 DNS 服务器的查询是递归的,其余的查询时迭代的。
+
+
+
+现在,主机 `cis.poly.edu` 想知道 `gaia.cs.umass.edu` 的 IP 地址。假设主机 `cis.poly.edu` 的本地 DNS 服务器为 `dns.poly.edu`,并且 `gaia.cs.umass.edu` 的权威 DNS 服务器为 `dns.cs.umass.edu`。
+
+1. 首先,主机 `cis.poly.edu` 向本地 DNS 服务器 `dns.poly.edu` 发送一个 DNS 请求,该查询报文包含被转换的域名 `gaia.cs.umass.edu`。
+2. 本地 DNS 服务器 `dns.poly.edu` 检查本机缓存,发现并无记录,也不知道 `gaia.cs.umass.edu` 的 IP 地址该在何处,不得不向根服务器发送请求。
+3. 根服务器注意到请求报文中含有 `edu` 顶级域,因此告诉本地 DNS,你可以向 `edu` 的 TLD DNS 发送请求,因为目标域名的 IP 地址很可能在那里。
+4. 本地 DNS 获取到了 `edu` 的 TLD DNS 服务器地址,向其发送请求,询问 `gaia.cs.umass.edu` 的 IP 地址。
+5. `edu` 的 TLD DNS 服务器仍不清楚请求域名的 IP 地址,但是它注意到该域名有 `umass.edu` 前缀,因此返回告知本地 DNS,`umass.edu` 的权威服务器可能记录了目标域名的 IP 地址。
+6. 这一次,本地 DNS 将请求发送给权威 DNS 服务器 `dns.cs.umass.edu`。
+7. 终于,由于 `gaia.cs.umass.edu` 向权威 DNS 服务器备案过,在这里有它的 IP 地址记录,权威 DNS 成功地将 IP 地址返回给本地 DNS。
+8. 最后,本地 DNS 获取到了目标域名的 IP 地址,将其返回给请求主机。
+
+除了迭代式查询,还有一种递归式查询如下图,具体过程和上述类似,只是顺序有所不同。
+
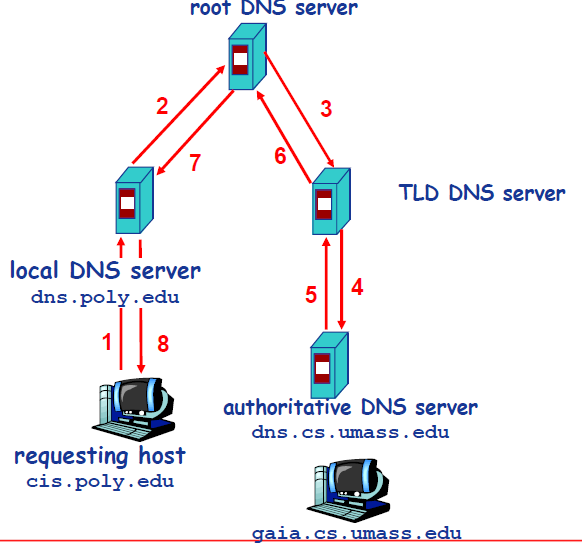
+
+
+另外,DNS 的缓存位于本地 DNS 服务器。由于全世界的根服务器甚少,只有 600 多台,分为 13 组,且顶级域的数量也在一个可数的范围内,因此本地 DNS 通常已经缓存了很多 TLD DNS 服务器,所以在实际查找过程中,无需访问根服务器。根服务器通常是被跳过的,不请求的。这样可以提高 DNS 查询的效率和速度,减少对根服务器和 TLD 服务器的负担。
+
+## DNS 报文格式
+
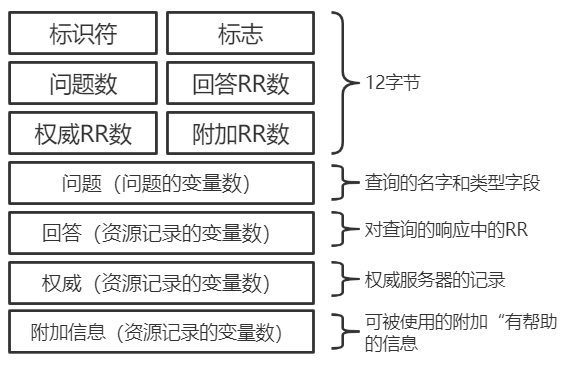
+DNS 的报文格式如下图所示:
+
+
+
+DNS 报文分为查询和回答报文,两种形式的报文结构相同。
+
+- 标识符。16 比特,用于标识该查询。这个标识符会被复制到对查询的回答报文中,以便让客户用它来匹配发送的请求和接收到的回答。
+- 标志。1 比特的“查询/回答”标识位,`0` 表示查询报文,`1` 表示回答报文;1 比特的“权威的”标志位(当某 DNS 服务器是所请求名字的权威 DNS 服务器时,且是回答报文,使用“权威的”标志);1 比特的“希望递归”标志位,显式地要求执行递归查询;1 比特的“递归可用”标志位,用于回答报文中,表示 DNS 服务器支持递归查询。
+- 问题数、回答 RR 数、权威 RR 数、附加 RR 数。分别指示了后面 4 类数据区域出现的数量。
+- 问题区域。包含正在被查询的主机名字,以及正被询问的问题类型。
+- 回答区域。包含了对最初请求的名字的资源记录。**在回答报文的回答区域中可以包含多条 RR,因此一个主机名能够有多个 IP 地址。**
+- 权威区域。包含了其他权威服务器的记录。
+- 附加区域。包含了其他有帮助的记录。
+
+## DNS 记录
+
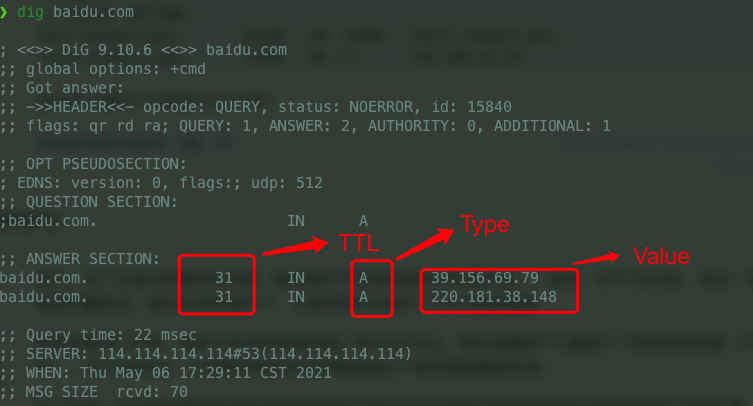
+DNS 服务器在响应查询时,需要查询自己的数据库,数据库中的条目被称为 **资源记录(Resource Record,RR)**。RR 提供了主机名到 IP 地址的映射。RR 是一个包含了 `Name`、`Value`、`Type`、`TTL` 四个字段的四元组。
+
+
+
+`TTL` 是该记录的生存时间,它决定了资源记录应当从缓存中删除的时间。
+
+`Name` 和 `Value` 字段的取值取决于 `Type`:
+
+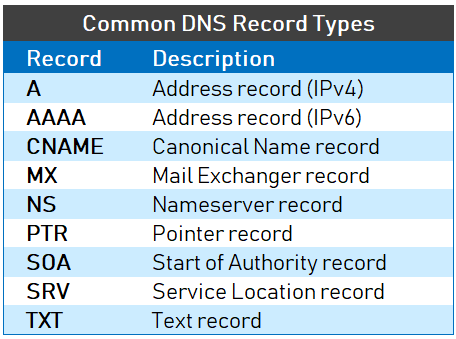
+
+- 如果 `Type=A`,则 `Name` 是主机名信息,`Value` 是该主机名对应的 IP 地址。这样的 RR 记录了一条主机名到 IP 地址的映射。
+- 如果 `Type=AAAA`(与 `A` 记录非常相似),唯一的区别是 A 记录使用的是 IPv4,而 `AAAA` 记录使用的是 IPv6。
+- 如果 `Type=CNAME`(Canonical Name Record,真实名称记录),则 `Value` 是别名为 `Name` 的主机对应的规范主机名。`Value` 值才是规范主机名。`CNAME` 记录将一个主机名映射到另一个主机名。`CNAME` 记录用于为现有的 `A` 记录创建别名。下文有示例。
+- 如果 `Type=NS`,则 `Name` 是个域,而 `Value` 是个知道如何获得该域中主机 IP 地址的权威 DNS 服务器的主机名。通常这样的 RR 是由 TLD 服务器发布的。
+- 如果 `Type=MX`,则 `Value` 是个别名为 `Name` 的邮件服务器的规范主机名。既然有了 `MX` 记录,那么邮件服务器可以和其他服务器使用相同的别名。为了获得邮件服务器的规范主机名,需要请求 `MX` 记录;为了获得其他服务器的规范主机名,需要请求 `CNAME` 记录。
+
+`CNAME` 记录总是指向另一则域名,而非 IP 地址。假设有下述 DNS zone:
+
+```plain
+NAME TYPE VALUE
+--------------------------------------------------
+bar.example.com. CNAME foo.example.com.
+foo.example.com. A 192.0.2.23
+```
+
+当用户查询 `bar.example.com` 的时候,DNS Server 实际返回的是 `foo.example.com` 的 IP 地址。
+
+## 参考
+
+- DNS 服务器类型:
+- DNS Message Resource Record Field Formats:
+- Understanding Different Types of Record in DNS Server:
+
+
diff --git a/docs/cs-basics/network/http-status-codes.md b/docs/cs-basics/network/http-status-codes.md
new file mode 100644
index 00000000000..935c4c7d0b4
--- /dev/null
+++ b/docs/cs-basics/network/http-status-codes.md
@@ -0,0 +1,90 @@
+---
+title: HTTP 常见状态码总结(应用层)
+description: 汇总常见 HTTP 状态码含义与使用场景,强调 201/204 等易混淆点,提升接口设计与调试效率。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP 状态码,2xx,3xx,4xx,5xx,重定向,错误码,201 Created,204 No Content
+---
+
+HTTP 状态码是服务端返回给客户端的处理结果摘要。看到一个状态码,基本就能判断请求是成功、重定向、客户端出错,还是服务端出错。
+
+状态码看起来只是数字,但很多码很容易混淆:比如 301 和 302、401 和 403、500 和 502、201 和 204。
+
+这篇文章主要回答几个问题:
+
+1. 1xx、2xx、3xx、4xx、5xx 分别代表什么类型的结果?
+2. 常见成功状态码如 200、201、204 有什么区别?
+3. 常见客户端错误如 400、401、403、404 应该怎么理解?
+4. 常见服务端错误如 500、502、503、504 通常意味着什么?
+
+
+
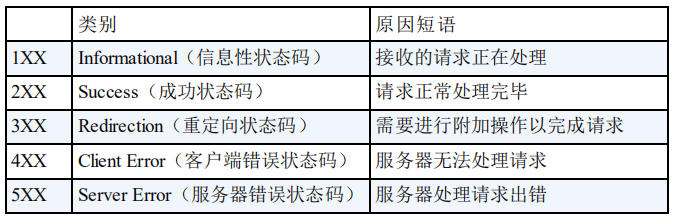
+### 1xx Informational(信息性状态码)
+
+相比于其他类别状态码来说,1xx 你平时你大概率不会碰到,所以这里直接跳过。
+
+### 2xx Success(成功状态码)
+
+- **200 OK**:请求被成功处理。例如,发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
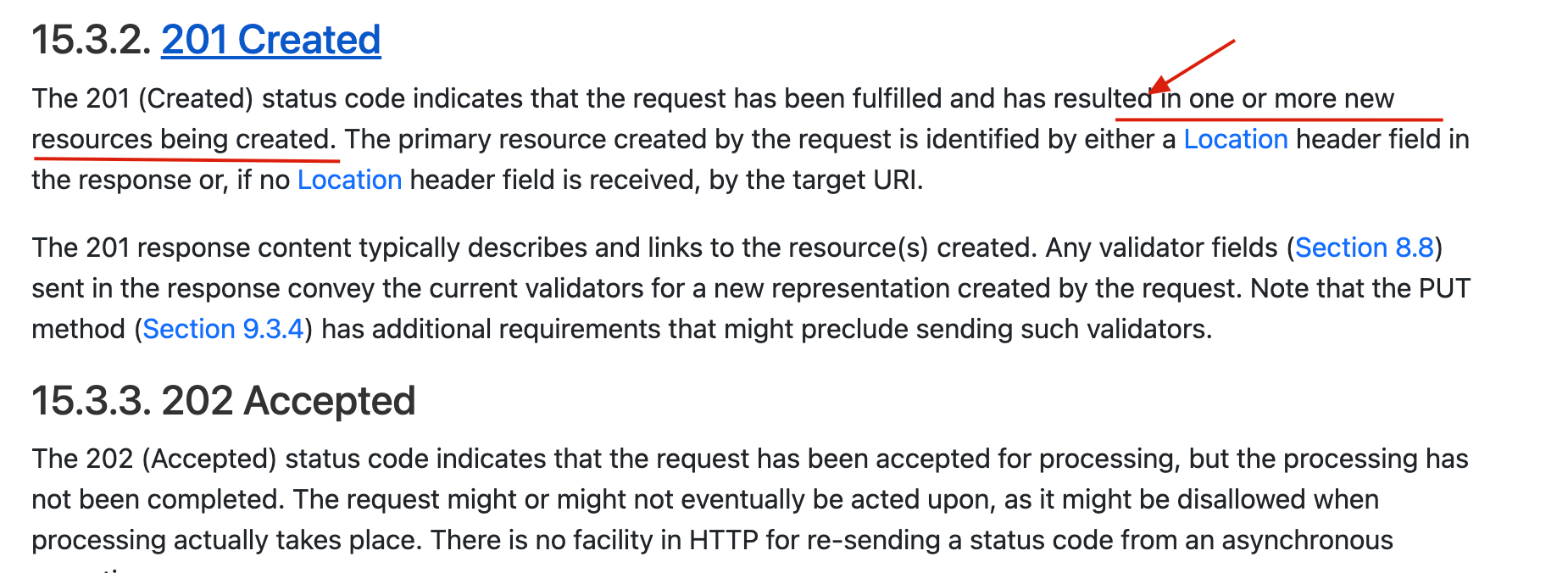
+- **201 Created**:请求被成功处理并且在服务端创建了~~一个新的资源~~。例如,通过 POST 请求创建一个新的用户。
+- **202 Accepted**:服务端已经接收到了请求,但是还未处理。例如,发送一个需要服务端花费较长时间处理的请求(如报告生成、Excel 导出),服务端接收了请求但尚未处理完毕。
+- **204 No Content**:服务端已经成功处理了请求,但是没有返回任何内容。例如,发送请求删除一个用户,服务器成功处理了删除操作但没有返回任何内容。
+
+🐛 修正(参见:[issue#2458](https://github.com/Snailclimb/JavaGuide/issues/2458)):201 Created 状态码更准确点来说是创建一个或多个新的资源,可以参考:。
+
+
+
+这里格外提一下 204 状态码,平时学习/工作中见到的次数并不多。
+
+[HTTP RFC 2616 对 204 状态码的描述](https://tools.ietf.org/html/rfc2616#section-10.2.5)如下:
+
+> The server has fulfilled the request but does not need to return an
+> entity-body, and might want to return updated metainformation. The
+> response MAY include new or updated metainformation in the form of
+> entity-headers, which if present SHOULD be associated with the
+> requested variant.
+>
+> If the client is a user agent, it SHOULD NOT change its document view
+> from that which caused the request to be sent. This response is
+> primarily intended to allow input for actions to take place without
+> causing a change to the user agent's active document view, although
+> any new or updated metainformation SHOULD be applied to the document
+> currently in the user agent's active view.
+>
+> The 204 response MUST NOT include a message-body, and thus is always
+> terminated by the first empty line after the header fields.
+
+简单来说,204 状态码描述的是我们向服务端发送 HTTP 请求之后,只关注处理结果是否成功的场景。也就是说我们需要的就是一个结果:true/false。
+
+举个例子:你要追一个女孩子,你问女孩子:“我能追你吗?”,女孩子回答:“好!”。我们把这个女孩子当做是服务端就很好理解 204 状态码了。
+
+### 3xx Redirection(重定向状态码)
+
+- **301 Moved Permanently**:资源被永久重定向了。比如你的网站的网址更换了。
+- **302 Found**:资源被临时重定向了。比如你的网站的某些资源被暂时转移到另外一个网址。
+
+### 4xx Client Error(客户端错误状态码)
+
+- **400 Bad Request**:发送的 HTTP 请求存在问题。比如请求参数不合法、请求方法错误。
+- **401 Unauthorized**:未认证却请求需要认证之后才能访问的资源。
+- **403 Forbidden**:直接拒绝 HTTP 请求,不处理。一般用来针对非法请求。
+- **404 Not Found**:你请求的资源未在服务端找到。比如你请求某个用户的信息,服务端并没有找到指定的用户。
+- **409 Conflict**:表示请求的资源与服务端当前的状态存在冲突,请求无法被处理。
+
+### 5xx Server Error(服务端错误状态码)
+
+- **500 Internal Server Error**:服务端出问题了(通常是服务端出 Bug 了)。比如你服务端处理请求的时候突然抛出异常,但是异常并未在服务端被正确处理。
+- **502 Bad Gateway**:我们的网关将请求转发到服务端,但是服务端返回的却是一个错误的响应。
+
+### 参考
+
+-
+-
+-
+-
+
+
diff --git a/docs/cs-basics/network/http-vs-https.md b/docs/cs-basics/network/http-vs-https.md
new file mode 100644
index 00000000000..3ab2334610b
--- /dev/null
+++ b/docs/cs-basics/network/http-vs-https.md
@@ -0,0 +1,160 @@
+---
+title: HTTP vs HTTPS:区别在哪里、HTTPS 为什么更安全(应用层)
+description: 对比 HTTP 与 HTTPS 的协议与安全机制,解析 SSL/TLS 工作原理与握手流程,明确应用层安全落地细节。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP,HTTPS,SSL,TLS,加密,认证,端口,安全性,握手流程
+---
+
+HTTP 能传输网页内容,但默认是明文传输。请求和响应如果在网络中被监听、篡改或冒充,HTTP 本身没有足够的保护能力。
+
+HTTPS 不是一个全新的应用层协议,而是在 HTTP 和 TCP 之间加入 TLS/SSL,用加密、身份认证和完整性校验来保护通信过程。
+
+这篇文章主要回答几个问题:
+
+1. HTTP 和 HTTPS 的核心区别是什么?
+2. HTTPS 如何防止窃听、篡改和冒充?
+3. SSL/TLS 握手大致做了哪些事情?
+4. 为什么使用 HTTPS 后,证书、混合内容和性能优化仍然需要关注?
+
+## HTTP 协议
+
+### HTTP 协议介绍
+
+HTTP 协议,全称超文本传输协议(Hypertext Transfer Protocol)。顾名思义,HTTP 协议就是用来规范超文本的传输,超文本,也就是网络上的包括文本在内的各式各样的消息,具体来说,主要是来规范浏览器和服务器端的行为的。
+
+并且,HTTP 是一个无状态(stateless)协议,也就是说服务器不维护任何有关客户端过去所发请求的消息。这其实是一种懒政,有状态协议会更加复杂,需要维护状态(历史信息),而且如果客户或服务器失效,会产生状态的不一致,解决这种不一致的代价更高。
+
+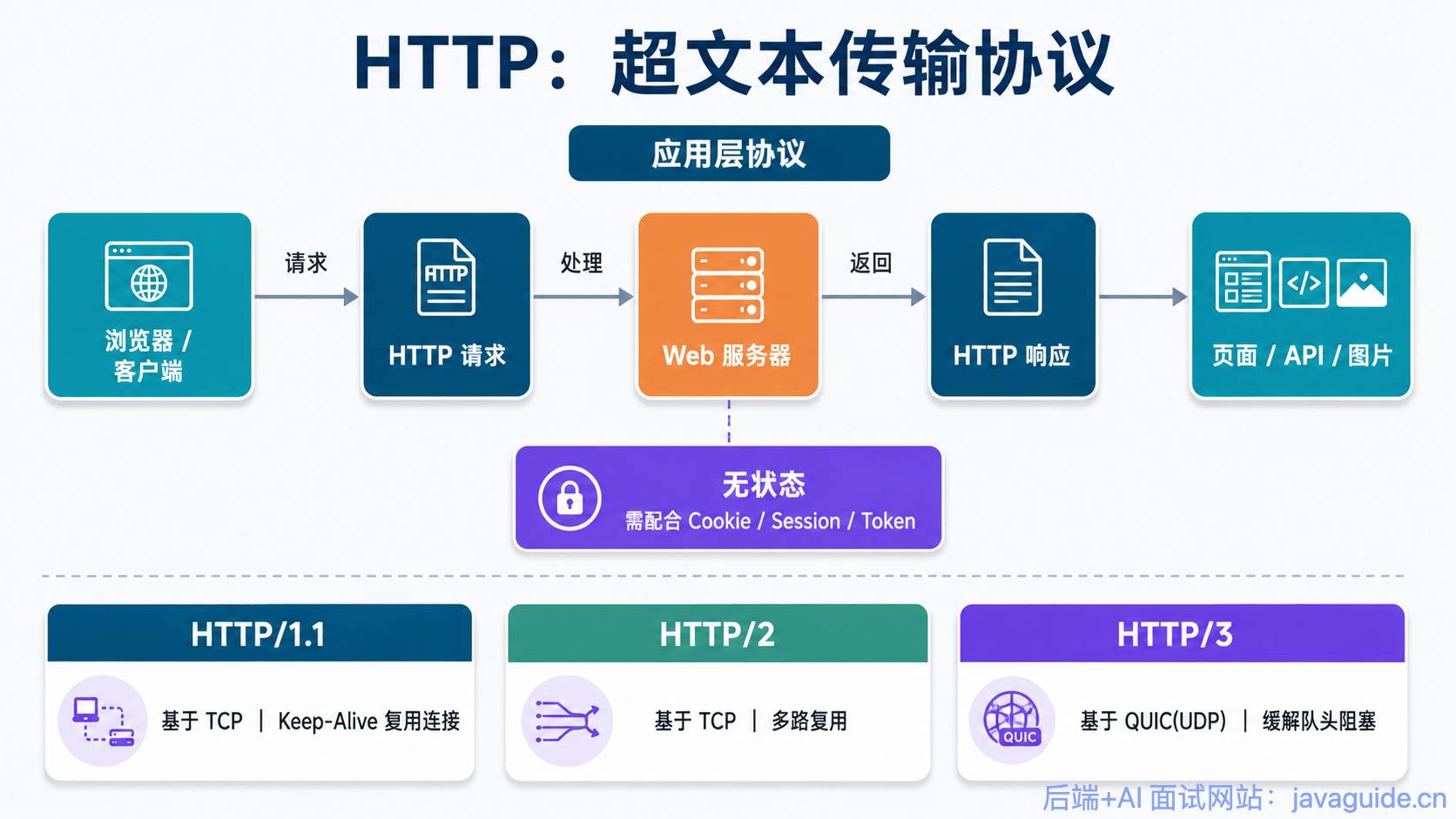
+
+### HTTP 协议通信过程
+
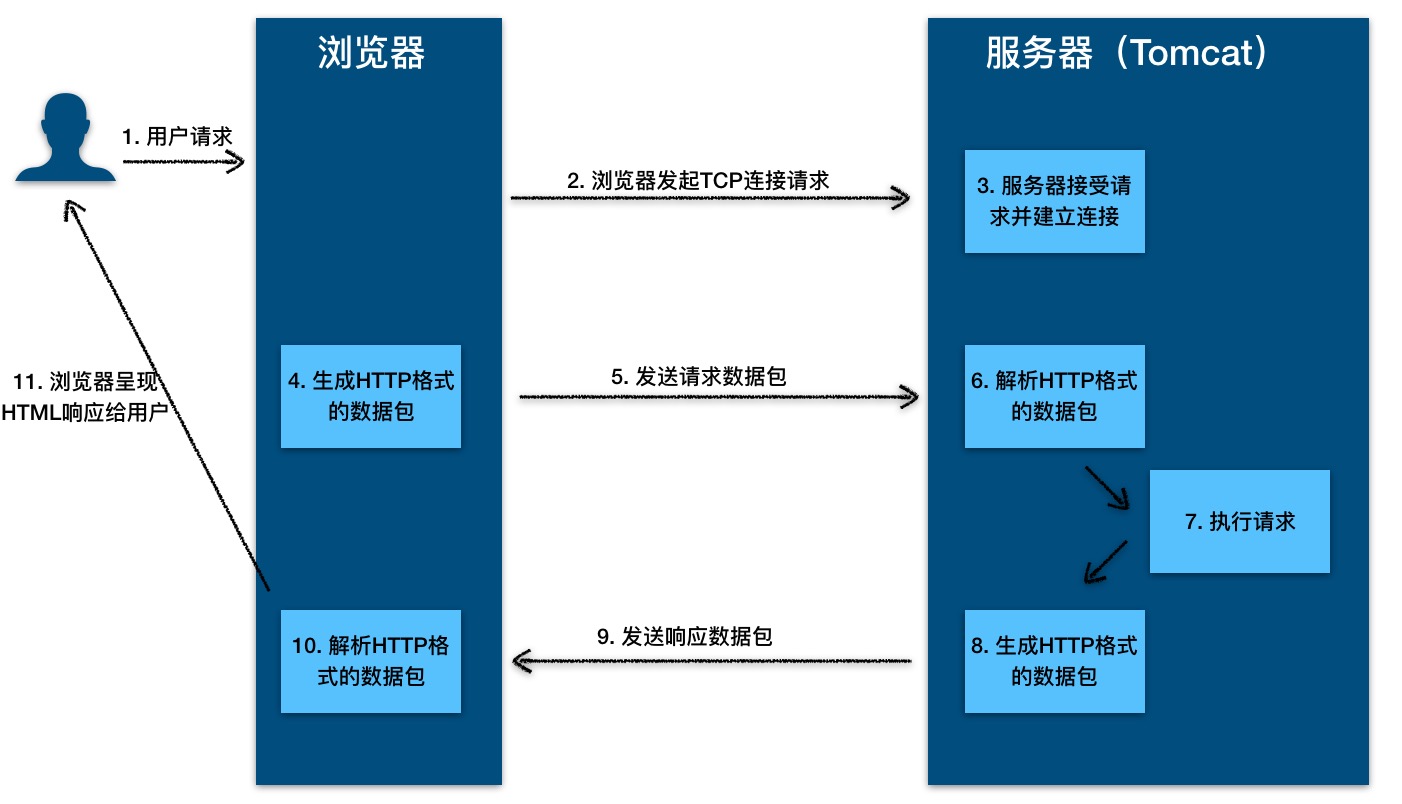
+HTTP 是应用层协议,它以 TCP(传输层)作为底层协议,默认端口为 80。通信过程主要如下:
+
+1. 服务器在 80 端口等待客户的请求。
+2. 浏览器发起到服务器的 TCP 连接(创建套接字 Socket)。
+3. 服务器接收来自浏览器的 TCP 连接。
+4. 浏览器(HTTP 客户端)与 Web 服务器(HTTP 服务器)交换 HTTP 消息。
+5. 关闭 TCP 连接。
+
+### HTTP 协议优点
+
+扩展性强、速度快、跨平台支持性好。
+
+## HTTPS 协议
+
+### HTTPS 协议介绍
+
+HTTPS 协议(Hyper Text Transfer Protocol Secure),是 HTTP 的加强安全版本。HTTPS 是基于 HTTP 的,也是用 TCP 作为底层协议,并额外使用 SSL/TLS 协议用作加密和安全认证。默认端口号是 443。
+
+HTTPS 中,TLS 握手完成后,通信数据使用对称加密算法(如 AES-128-GCM 或 AES-256-GCM)保护,密钥通过非对称加密(如 RSA-2048/4096 或 ECDH)在握手阶段协商生成。早期 SSL 使用的 40 比特密钥因强度不足已被废弃,现代 TLS 要求对称密钥至少 128 比特。
+
+### HTTPS 协议优点
+
+保密性好、信任度高。
+
+## HTTPS 的核心—SSL/TLS 协议
+
+HTTPS 之所以能达到较高的安全性要求,就是结合 SSL/TLS 和 TCP 协议,对通信数据进行加密,解决了 HTTP 数据透明的问题。接下来重点介绍 SSL/TLS 的工作原理。
+
+### SSL 和 TLS 的区别?
+
+**SSL 和 TLS 没有太大的区别。**
+
+SSL 指安全套接层协议(Secure Sockets Layer),首次发布于 1996 年(SSL 3.0)。SSL 1.0 从未面世,SSL 2.0 则具有较大的缺陷(DROWN 缺陷——Decrypting RSA with Obsolete and Weakened eNcryption)。很快,在 1999 年,SSL 3.0 进一步升级,**新版本被命名为 TLS 1.0**。因此,TLS 是基于 SSL 之上的,但由于习惯叫法,通常把 HTTPS 中的核心加密协议混称为 SSL/TLS。目前 SSL 已完全废弃,TLS 1.2 和 TLS 1.3 是现代 HTTPS 的实际标准。
+
+### SSL/TLS 的工作原理
+
+#### 非对称加密
+
+SSL/TLS 的核心要素是**非对称加密**。非对称加密采用两个密钥:一个公钥,一个私钥。在通信时,私钥仅由解密者保存,公钥由任何一个想与解密者通信的发送者(加密者)所知。可以设想一个场景:
+
+> 在某个自助邮局,每个通信信道都是一个邮箱,每一个邮箱所有者都在旁边立了一个牌子,上面挂着一把钥匙:这是我的公钥,发送者请将信件放入我的邮箱,并用公钥锁好。
+>
+> 但是公钥只能加锁,并不能解锁。解锁只能由邮箱的所有者——因为只有他保存着私钥。
+>
+> 这样,通信信息就不会被其他人截获了,这依赖于私钥的保密性。
+
+
+
+非对称加密的公钥和私钥需要采用一种复杂的数学机制生成(密码学认为,为了较高的安全性,尽量不要自己创造加密方案)。公私钥对的生成算法依赖于单向陷门函数。
+
+> 单向函数:已知单向函数 f,给定任意一个输入 x,易计算输出 y=f(x);而给定一个输出 y,假设存在 f(x)=y,很难根据 f 来计算出 x。
+>
+> 单向陷门函数:一个较弱的单向函数。已知单向陷门函数 f,陷门 h,给定任意一个输入 x,易计算出输出 y=f(x;h);而给定一个输出 y,假设存在 f(x;h)=y,很难根据 f 来计算出 x,但可以根据 f 和 h 来推导出 x。
+
+
+
+上图就是一个单向函数(不是单项陷门函数),假设有一个绝世秘籍,任何知道了这个秘籍的人都可以把苹果汁榨成苹果,那么这个秘籍就是“陷门”了吧。
+
+在这里,函数 f 的计算方法相当于公钥,陷门 h 相当于私钥。公钥 f 是公开的,任何人对已有输入,都可以用 f 加密,而要想根据加密信息还原出原信息,必须要有私钥才行。
+
+#### 对称加密
+
+使用 SSL/TLS 进行通信的双方需要使用非对称加密方案来通信,但是非对称加密设计了较为复杂的数学算法,在实际通信过程中,计算的代价较高,效率太低,因此,SSL/TLS 实际对消息的加密使用的是对称加密。
+
+> 对称加密:通信双方共享唯一密钥 k,加解密算法已知,加密方利用密钥 k 加密,解密方利用密钥 k 解密,保密性依赖于密钥 k 的保密性。
+
+
+
+对称加密的密钥生成代价比公私钥对的生成代价低得多。那么有的人会问:为什么 SSL/TLS 还需要使用非对称加密呢?因为对称加密的保密性完全依赖于密钥的保密性。在双方通信之前,需要商量一个用于对称加密的密钥。网络通信的信道是不安全的,传输报文对任何人是可见的,密钥的交换肯定不能直接在网络信道中传输。因此,使用非对称加密对对称加密的密钥进行加密,保护该密钥不在网络信道中被窃听。这样,通信双方只需要一次非对称加密,交换对称加密的密钥,在之后的信息通信中,使用绝对安全的密钥对信息进行对称加密,即可保证传输消息的保密性。
+
+#### 公钥传输的信赖性
+
+SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐患。设想下面的场景:
+
+> 客户端 C 和服务器 S 想要使用 SSL/TLS 通信,由上述 SSL/TLS 通信原理,C 需要先知道 S 的公钥,而 S 公钥的唯一获取途径,就是把 S 公钥在网络信道中传输。要注意网络信道通信中有几个前提:
+>
+> 1. 任何人都可以捕获通信包
+> 2. 通信包的保密性由发送者设计
+> 3. 保密算法设计方案默认为公开,而(解密)密钥默认是安全的
+>
+> 因此,假设 S 公钥不做加密,在信道中传输,那么很有可能存在一个攻击者 A,发送给 C 一个诈包,假装是 S 公钥,其实是诱饵服务器 AS 的公钥。当 C 收获了 AS 的公钥(却以为是 S 的公钥),C 后续就会使用 AS 公钥对数据进行加密,并在公开信道传输,那么 A 将捕获这些加密包,用 AS 的私钥解密,就截获了 C 本要给 S 发送的内容,而 C 和 S 二人全然不知。
+>
+> 同样的,S 公钥即使做加密,也难以避免这种信任性问题,C 被 AS 拐跑了!
+
+
+
+为了公钥传输的信赖性问题,第三方机构应运而生——证书颁发机构(CA,Certificate Authority)。CA 默认是受信任的第三方。CA 会给各个服务器颁发证书,证书存储在服务器上,并附有 CA 的**电子签名**(见下节)。
+
+当客户端(浏览器)向服务器发送 HTTPS 请求时,一定要先获取目标服务器的证书,并根据证书上的信息,检验证书的合法性。一旦客户端检测到证书非法,就会发生错误。客户端获取了服务器的证书后,由于证书的信任性是由第三方信赖机构认证的,而证书上又包含着服务器的公钥信息,客户端就可以放心的信任证书上的公钥就是目标服务器的公钥。
+
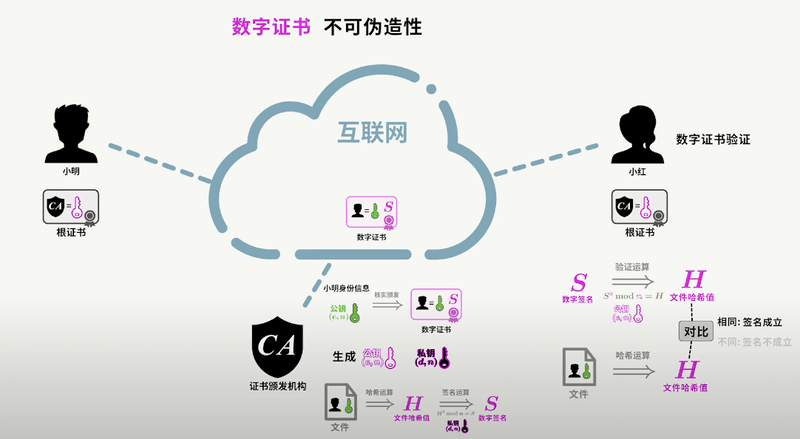
+#### 数字签名
+
+好,到这一小节,已经是 SSL/TLS 的尾声了。上一小节提到了数字签名,数字签名要解决的问题,是防止证书被伪造。第三方信赖机构 CA 之所以能被信赖,就是 **靠数字签名技术** 。
+
+数字签名,是 CA 在给服务器颁发证书时,使用散列+加密的组合技术,在证书上盖个章,以此来提供验伪的功能。具体行为如下:
+
+> CA 知道服务器的公钥,对证书采用散列技术生成一个摘要。CA 使用 CA 私钥对该摘要进行加密,并附在证书下方,发送给服务器。
+>
+> 现在服务器将该证书发送给客户端,客户端需要验证该证书的身份。客户端找到第三方机构 CA,获知 CA 的公钥,并用 CA 公钥对证书的签名进行解密,获得了 CA 生成的摘要。
+>
+> 客户端对证书数据(包含服务器的公钥)做相同的散列处理,得到摘要,并将该摘要与之前从签名中解码出的摘要做对比,如果相同,则身份验证成功;否则验证失败。
+
+
+
+总结来说,带有证书的公钥传输机制如下:
+
+1. 设有服务器 S,客户端 C,和第三方信赖机构 CA。
+2. S 信任 CA,CA 是知道 S 公钥的,CA 向 S 颁发证书。并附上 CA 私钥对消息摘要的加密签名。
+3. S 获得 CA 颁发的证书,将该证书传递给 C。
+4. C 获得 S 的证书,信任 CA 并知晓 CA 公钥,使用 CA 公钥对 S 证书上的签名解密,同时对消息进行散列处理,得到摘要。比较摘要,验证 S 证书的真实性。
+5. 如果 C 验证 S 证书是真实的,则信任 S 的公钥(在 S 证书中)。
+
+
+
+对于数字签名,我这里讲的比较简单,如果你没有搞清楚的话,强烈推荐你看看[数字签名及数字证书原理](https://www.bilibili.com/video/BV18N411X7ty/)这个视频,这是我看过最清晰的讲解。
+
+
+
+## 总结
+
+- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
+- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
+- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
+
+
diff --git a/docs/cs-basics/network/http1.0-vs-http1.1.md b/docs/cs-basics/network/http1.0-vs-http1.1.md
new file mode 100644
index 00000000000..a16a1eae27a
--- /dev/null
+++ b/docs/cs-basics/network/http1.0-vs-http1.1.md
@@ -0,0 +1,179 @@
+---
+title: HTTP 1.0 vs HTTP 1.1:长连接、缓存、Host 头等核心差异(应用层)
+description: 细致对比 HTTP/1.0 与 HTTP/1.1 的协议差异,涵盖长连接、管道化、缓存与状态码增强等关键变更与实践影响。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP/1.0,HTTP/1.1,长连接,管道化,缓存,状态码,Host,带宽优化
+---
+
+HTTP/1.0 和 HTTP/1.1 名字只差一个小版本,但它们在连接复用、缓存、Host 头、状态码和带宽优化上都有明显差异。
+
+这些差异不是单纯的协议细节,它们直接影响浏览器如何发请求、服务器如何复用连接、缓存如何生效,以及虚拟主机如何工作。
+
+这篇文章主要回答几个问题:
+
+1. HTTP/1.1 相比 HTTP/1.0 新增了哪些常见状态码?
+2. HTTP/1.0 和 HTTP/1.1 的缓存机制有什么差异?
+3. HTTP/1.1 为什么默认支持长连接?
+4. Host 头和带宽优化分别解决了什么问题?
+
+开始之前,先简单回顾一下 HTTP 协议:
+
+
+
+## 响应状态码
+
+HTTP/1.0 仅定义了 16 种状态码。HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
+
+## 缓存处理
+
+缓存技术通过避免用户与源服务器的频繁交互,节约了大量的网络带宽,降低了用户接收信息的延迟。
+
+### HTTP/1.0
+
+HTTP/1.0 提供的缓存机制非常简单。服务器端使用 `Expires` 标签来标志(时间)一个响应体,在 `Expires` 标志时间内的请求,都会获得该响应体缓存。服务器端在初次返回给客户端的响应体中,有一个 `Last-Modified` 标签,该标签标记了被请求资源在服务器端的最后一次修改。在请求头中,使用 `If-Modified-Since` 标签,该标签标志一个时间,意为客户端向服务器进行问询:“该时间之后,我要请求的资源是否有被修改过?”通常情况下,请求头中的 `If-Modified-Since` 的值即为上一次获得该资源时,响应体中的 `Last-Modified` 的值。
+
+如果服务器接收到了请求头,并判断`If-Modified-Since`时间后,资源确实没有修改过,则返回给客户端一个 `304 Not Modified` 响应头,表示“缓冲可用,你从浏览器里拿吧!”。
+
+如果服务器判断 `If-Modified-Since` 时间后,资源被修改过,则返回给客户端一个 `200 OK` 的响应体,并附带全新的资源内容,表示“你要的我已经改过的,给你一份新的”。
+
+
+
+
+
+### HTTP/1.1
+
+HTTP/1.1 的缓存机制在 HTTP/1.0 的基础上,大大增加了灵活性和扩展性。基本工作原理和 HTTP/1.0 保持不变,而是增加了更多细致的特性。其中,请求头中最常见的特性就是 `Cache-Control`,详见 MDN Web 文档 [Cache-Control](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control)。
+
+## 连接方式
+
+**HTTP/1.0 默认使用短连接** ,也就是说,客户端和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如 JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 TCP 连接,这样就会导致有大量的“握手报文”和“挥手报文”占用了带宽。
+
+**为了解决 HTTP/1.0 存在的资源浪费的问题,HTTP/1.1 优化为默认长连接模式。** 采用长连接模式的请求报文会通知服务端:“我向你请求连接,并且连接成功建立后,请不要关闭”。因此,该 TCP 连接将持续打开,为后续的客户端-服务端的数据交互服务。也就是说在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。
+
+如果 TCP 连接一直保持的话也是对资源的浪费,因此,一些服务器软件(如 Apache)还会支持超时时间选项。在超时时间之内没有新的请求到达,TCP 连接才会被关闭。
+
+有必要说明的是,HTTP/1.0 仍提供了长连接选项,即在请求头中加入 `Connection: Keep-Alive`。同样的,在 HTTP/1.1 中,如果不希望使用长连接选项,也可以在请求头中加入 `Connection: close`,这样会通知服务器端:“我不需要长连接,连接成功后即可关闭”。
+
+**HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。**
+
+**实现长连接需要客户端和服务端都支持长连接。**
+
+## Host 头处理
+
+域名系统(DNS)允许多个主机名绑定到同一个 IP 地址上,但是 HTTP/1.0 并没有考虑这个问题。假设我们有一个资源 URL 是 `http://example1.org/home.html`,HTTP/1.0 的请求报文中,将会请求的是 `GET /home.html HTTP/1.0`,也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
+
+因此,HTTP/1.1 在请求头中加入了 `Host` 字段。加入 `Host` 字段的报文头部将会是:
+
+```plain
+GET /home.html HTTP/1.1
+Host: example1.org
+```
+
+这样,服务器端就可以确定客户端想要请求的真正的网址了。
+
+## 带宽优化
+
+### 范围请求
+
+HTTP/1.1 引入了范围请求(range request)机制,以避免带宽的浪费。当客户端想请求一个文件的一部分,或者需要继续下载一个已经下载了部分但被终止的文件,HTTP/1.1 可以在请求中加入 `Range` 头部,以请求(并只能请求字节型数据)数据的一部分。服务器端可以忽略 `Range` 头部,也可以返回若干 `Range` 响应。
+
+`206 (Partial Content)` 状态码的主要作用是确保客户端和代理服务器能正确识别部分内容响应,避免将其误认为完整资源并错误地缓存。这对于正确处理范围请求和缓存管理非常重要。
+
+一个典型的 HTTP/1.1 范围请求示例:
+
+```http
+# 获取一个文件的前 1024 个字节
+GET /z4d4kWk.jpg HTTP/1.1
+Host: i.imgur.com
+Range: bytes=0-1023
+```
+
+`206 Partial Content` 响应:
+
+```http
+HTTP/1.1 206 Partial Content
+Content-Range: bytes 0-1023/146515
+Content-Length: 1024
+…
+(二进制内容)
+```
+
+简单解释一下 HTTP 范围响应头部中的字段:
+
+- **`Content-Range` 头部**:指示返回数据在整个资源中的位置,包括起始和结束字节以及资源的总长度。例如,`Content-Range: bytes 0-1023/146515` 表示服务器端返回了第 0 到 1023 字节的数据(共 1024 字节),而整个资源的总长度是 146,515 字节。
+- **`Content-Length` 头部**:指示此次响应中实际传输的字节数。例如,`Content-Length: 1024` 表示服务器端传输了 1024 字节的数据。
+
+`Range` 请求头不仅可以请求单个字节范围,还可以一次性请求多个范围。这种方式被称为“多重范围请求”(multiple range requests)。
+
+客户端想要获取资源的第 0 到 499 字节以及第 1000 到 1499 字节:
+
+```http
+GET /path/to/resource HTTP/1.1
+Host: example.com
+Range: bytes=0-499,1000-1499
+```
+
+服务器端返回多个字节范围,每个范围的内容以分隔符分开:
+
+```http
+HTTP/1.1 206 Partial Content
+Content-Type: multipart/byteranges; boundary=3d6b6a416f9b5
+Content-Length: 376
+
+--3d6b6a416f9b5
+Content-Type: application/octet-stream
+Content-Range: bytes 0-99/2000
+
+(第 0 到 99 字节的数据块)
+
+--3d6b6a416f9b5
+Content-Type: application/octet-stream
+Content-Range: bytes 500-599/2000
+
+(第 500 到 599 字节的数据块)
+
+--3d6b6a416f9b5
+Content-Type: application/octet-stream
+Content-Range: bytes 1000-1099/2000
+
+(第 1000 到 1099 字节的数据块)
+
+--3d6b6a416f9b5--
+```
+
+### 状态码 100
+
+HTTP/1.1 中新加入了状态码 `100`。该状态码的使用场景为,存在某些较大的文件请求,服务器可能不愿意响应这种请求,此时状态码 `100` 可以作为指示请求是否会被正常响应,过程如下图:
+
+
+
+
+
+然而在 HTTP/1.0 中,并没有 `100 (Continue)` 状态码,要想触发这一机制,可以发送一个 `Expect` 头部,其中包含一个 `100-continue` 的值。
+
+### 压缩
+
+许多格式的数据在传输时都会做预压缩处理。数据的压缩可以大幅优化带宽的利用。然而,HTTP/1.0 对数据压缩的选项提供的不多,不支持压缩细节的选择,也无法区分端到端(end-to-end)压缩或者是逐跳(hop-by-hop)压缩。
+
+HTTP/1.1 则对内容编码(content-codings)和传输编码(transfer-codings)做了区分。内容编码总是端到端的,传输编码总是逐跳的。
+
+HTTP/1.0 包含了 `Content-Encoding` 头部,对消息进行端到端编码。HTTP/1.1 加入了 `Transfer-Encoding` 头部,可以对消息进行逐跳传输编码。HTTP/1.1 还加入了 `Accept-Encoding` 头部,是客户端用来指示它能处理什么样的内容编码。
+
+## 总结
+
+1. **连接方式**:HTTP/1.0 为短连接,HTTP/1.1 支持长连接。
+2. **状态响应码**:HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
+3. **缓存处理**:在 HTTP/1.0 中主要使用 header 里的 `If-Modified-Since`、`Expires` 来作为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略,例如 `Entity Tag`、`If-Unmodified-Since`、`If-Match`、`If-None-Match` 等更多可供选择的缓存头来控制缓存策略。
+4. **带宽优化及网络连接的使用**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能。HTTP/1.1 则在请求头引入了 `Range` 头域,它允许只请求资源的某个部分,即返回码是 `206 (Partial Content)`,这样就方便了开发者自由选择以便于充分利用带宽和连接。
+5. **Host 头处理**:HTTP/1.1 在请求头中加入了 `Host` 字段。
+
+## 参考资料
+
+[Key differences between HTTP/1.0 and HTTP/1.1](http://www.ra.ethz.ch/cdstore/www8/data/2136/pdf/pd1.pdf)
+
+
diff --git a/docs/cs-basics/network/https-rsa-vs-ecdhe.md b/docs/cs-basics/network/https-rsa-vs-ecdhe.md
new file mode 100644
index 00000000000..ce9c549a041
--- /dev/null
+++ b/docs/cs-basics/network/https-rsa-vs-ecdhe.md
@@ -0,0 +1,442 @@
+---
+title: HTTPS 握手里的 RSA 和 ECDHE,到底差在哪?(应用层)
+description: 对比 TLS 握手中 RSA 密钥交换与 ECDHE 密钥交换的核心差异,讲清前向安全、密码套件命名、TLS 1.3 变化及面试要点。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTPS,RSA,ECDHE,TLS,握手,前向安全,密钥交换,密码套件,TLS 1.3,PreMasterSecret
+---
+
+很多人第一次学 HTTPS,脑子里会留下一个很粗的印象:
+
+**HTTPS = HTTP + 加密,加密 = RSA。 所以,HTTPS = RSA 加密。**
+
+这个理解不是凭空来的。早期很多 HTTPS 部署确实大量使用 RSA 相关的密码套件,很多入门讲解也喜欢拿 RSA 举例。
+
+但严格说,HTTPS 从来不等于 RSA 加密。即使在 TLS 1.0、TLS 1.1 时代,RSA 也只是可选方案之一,协议里还存在 DHE 这类密钥交换方式。到了 TLS 1.3,静态 RSA 密钥交换已经被移除,RSA 更多出现在证书签名、身份认证这类位置。
+
+所以,这篇文章真正要对比的不是“RSA 和 ECDHE 谁更高级”。
+
+**RSA 握手里,会话密钥材料是客户端生成后加密发给服务端;ECDHE 握手里,会话密钥材料不是直接传过去的,而是客户端和服务端各自算出来的。**
+
+这篇文章主要回答几个问题:
+
+1. HTTPS 为什么不等于 RSA 加密?
+2. RSA 握手和 ECDHE 握手的会话密钥材料分别是怎么来的?
+3. ECDHE 为什么能提供前向安全性?
+4. TLS 1.3 为什么移除静态 RSA 密钥交换?
+
+把这些问题讲清楚了,`PreMasterSecret`、`Server Key Exchange`、前向安全、TLS 1.3 为什么移除静态 RSA,后面都能顺着理解。
+
+
+
+## TLS 握手的两个核心问题
+
+HTTPS 仍然基于 HTTP,也仍然依赖 TCP。区别在于,HTTP 报文不会直接裸跑在 TCP 之上,而是先经过 TLS 完成身份认证、密钥协商和加密保护。
+
+握手完成后,真正保护业务数据的通常是 AES-GCM 这类对称加密算法,而不是拿 RSA 去加密完整的请求和响应。
+
+这里有两个问题。
+
+**第一个问题:浏览器和服务器需要协商出一份会话密钥。**
+
+后面传输 HTTP 请求、Cookie、响应体时,就用这份会话密钥做对称加密。对称加密更适合处理大量数据;非对称加密计算成本高,一般不拿来直接加密完整网页内容。
+
+**第二个问题:浏览器需要确认对面真的是目标网站。**
+
+如果只是“服务器发一个公钥给浏览器”,那中间人也可以发自己的公钥。浏览器以为那是目标网站的公钥,后面就把秘密信息加密给了攻击者。证书、CA、数字签名解决的是这件事:证明这个公钥确实和这个域名绑定,而不是路上某个人塞进来的。
+
+RSA 握手和 ECDHE 握手都会面对这两个问题。只是它们解决“会话密钥怎么来”的方式不同。
+
+## RSA 握手:密钥材料加密发送
+
+### 完整握手流程
+
+先看 TLS 1.2 里的 RSA 密钥交换。
+
+浏览器先发 `ClientHello`。这里面会带上客户端支持的 TLS 版本、支持的密码套件、一个随机数 `Client Random`。
+
+服务器收到之后,回 `ServerHello`,选定 TLS 版本和密码套件,也给出一个随机数 `Server Random`,然后把自己的证书发给客户端。
+
+到这里,客户端拿到了服务器证书。它会验证证书链、域名、有效期、签名这些信息。证书验证通过后,客户端就从证书里取出服务器的 RSA 公钥。
+
+接下来是关键步骤:客户端生成一个新的随机值,也就是 `PreMasterSecret`。在 TLS 1.2 的 RSA 密钥交换里,这个值是 **48 字节**。客户端会用服务器证书里的 RSA 公钥加密 `PreMasterSecret`,再把加密结果放进 `Client Key Exchange` 发给服务器。
+
+服务器收到后,用自己的 RSA 私钥解密,拿到同一份 `PreMasterSecret`。
+
+这时,客户端和服务端手里都有三份材料:
+
+```text
+Client Random
+Server Random
+PreMasterSecret
+```
+
+双方再根据这三份材料派生出 `Master Secret`,后续的会话密钥也会从这里继续派生出来。真正传 HTTP 请求和响应时,用的是这些派生出来的对称密钥。
+
+用一句话压缩:
+
+**RSA 握手的会话密钥材料,是客户端生成后“包起来”寄给服务器的。**
+
+这里的“包起来”,靠的就是服务器 RSA 公钥。只有持有对应 RSA 私钥的服务器,才能拆开这个包。
+
+看起来挺合理。客户端生成秘密,服务器私钥解密,双方得到同一份材料,再结合两个随机数派生出后续会话密钥。
+
+但问题也在这里。
+
+### 没有前向安全:长期私钥太值钱
+
+假设攻击者今天抓到了一段 HTTPS 流量,但当时没有服务器私钥,所以看不懂里面的内容。这时他可以先把流量保存下来。
+
+一年后,如果服务器 RSA 私钥泄漏了,会发生什么?
+
+在 RSA 密钥交换里,客户端当年发出的 `PreMasterSecret` 是用服务器 RSA 公钥加密的。如果攻击者完整捕获了握手阶段的明文随机数,也就是 `Client Random`、`Server Random`,同时保存了加密后的 `PreMasterSecret`,再结合后来泄漏的服务器私钥,就可能解开当时的 `PreMasterSecret`,继续派生出那次连接用过的会话密钥。
+
+旧数据就有机会被翻出来。
+
+这里要注意条件:不是“只要私钥泄漏,所有历史流量必然能解”。攻击者至少得拿到足够完整的握手数据和应用数据。如果只有单向片段,或者握手日志不完整,即使有私钥,也未必能把那次会话还原出来。
+
+但从安全设计上看,这个风险已经足够麻烦。长期私钥一旦变成打开历史流量的总钥匙,它的影响就不再只覆盖未来连接,也会波及过去已经发生过的通信。
+
+这里批评的不是 RSA 算法本身“不能用”。RSA 仍然可以用于签名认证,也可以出现在证书体系里。问题出在“用长期不变的服务器私钥去解密历史握手里的密钥材料”。
+
+服务器私钥一旦泄漏,代价太大。
+
+
+
+### 另一个历史包袱:填充预言机攻击
+
+RSA 密钥交换还有一个工程层面的麻烦:`PreMasterSecret` 不是直接裸加密,而是按 RSAES-PKCS1-v1_5 这类格式封装后再加密。
+
+这个细节曾经引出过 Bleichenbacher 这类填充预言机攻击。
+
+它的大致思路是:攻击者不一定要马上拿到服务器私钥,而是反复构造不同的密文发给服务器,观察服务器对“填充错误、版本错误、长度错误”的处理差异。如果服务端在错误码、响应时间、日志行为、连接关闭方式上露出差别,攻击者就可能一点点逼近明文。
+
+这类攻击麻烦的地方在于,它不是单纯的数学问题,而是实现问题。
+
+TLS 1.2 对这类情况做过防御要求:服务端即使解密失败,也不要把具体失败原因暴露出去,而是继续用随机值走完整个流程,避免攻击者通过差异行为判断密文是否接近正确格式。
+
+可规范要求不等于实现可靠。2017 年的 ROBOT 攻击再次说明,一些服务端仍然可能因为细小的行为差异暴露出 RSA 解密 oracle。错误码、耗时、日志、分支路径,只要有一处表现不一致,都可能变成侧信道。
+
+所以,静态 RSA 密钥交换被淘汰,不只是因为它没有前向安全,也因为它把太多风险压到了实现细节上。
+
+### 能否被降级回 RSA?
+
+这里还要补一个容易误解的点。
+
+TLS 1.2 里,客户端会在 `ClientHello` 里带上自己支持的密码套件列表,服务端从里面选一个双方都支持的套件。理论上,如果服务端仍然开放 `TLS_RSA_*` 这类静态 RSA 密钥交换套件,老客户端就可能继续用 RSA 握手。
+
+但这不等于“中间人随便把 ClientHello 里的 ECDHE 删掉,就能让连接悄悄降级到 RSA”。握手最后的 `Finished` 会校验握手 transcript,简单篡改 `ClientHello` 通常会导致校验失败,连接建立不起来。
+
+历史上确实发生过降级相关攻击,比如 FREAK 和 Logjam。它们利用的是当时一些客户端、服务端仍然支持出口级弱密码套件,再结合实现和配置问题,把连接压到更弱的 RSA_EXPORT 或 DHE_EXPORT 路径上,而不是“随便删掉 ECDHE 就能静默成功”。TLS 1.3 在 `ServerHello.random` 里加入降级保护值,也是在提醒我们:协议本身一直在补这类历史攻击面。
+
+真正需要关注的是服务端配置本身:如果已经不需要兼容很老的客户端,就应该关闭静态 RSA 密钥交换套件,只保留支持前向安全的套件。否则,环境里仍然可能存在客户端或错误配置走到 RSA 握手。
+
+这也是排查 TLS 配置时要看密码套件实际协商结果的原因。只看“服务器支持 ECDHE”不够,还要看它是否同时保留了 `TLS_RSA_*` 这类旧套件。
+
+## ECDHE 握手:密钥材料双方协商
+
+### DH 的核心思路
+
+ECDHE 里的 `DHE` 来自 Diffie-Hellman Ephemeral,意思是临时 Diffie-Hellman。前面的 `EC` 是 Elliptic Curve,表示基于椭圆曲线。
+
+别被名字吓住。先不看椭圆曲线,先看 DH 想解决什么问题。
+
+DH 的目标很有意思:通信双方不直接传输共享秘密,却能各自算出同一个共享秘密。
+
+可以粗略理解成这样:
+
+客户端生成一个临时私钥,只留在本地,再算出一个临时公钥发给服务器。服务器也生成一个临时私钥,只留在本地,再算出一个临时公钥发给客户端。
+
+双方交换的都是公钥。攻击者在网络里能看到这些公钥,但看不到双方各自的临时私钥。
+
+接着,客户端用“自己的临时私钥 + 服务器临时公钥”算出共享秘密;服务器用“自己的临时私钥 + 客户端临时公钥”也算出同一个共享秘密。
+
+共享秘密没有在网络上传输过。
+
+ECDHE 只是把这个过程放到椭圆曲线体系里做。椭圆曲线的数学理论更抽象,但在同等安全强度下,它通常能用更短的密钥达到相近的安全级别,运算和传输成本也比传统有限域 DHE 更低。对理解 TLS 握手来说,先记住一句话就够了:
+
+**ECDHE 的会话密钥材料不是某一方生成后发给另一方,而是双方通过临时密钥协商出来的。**
+
+### 完整握手流程
+
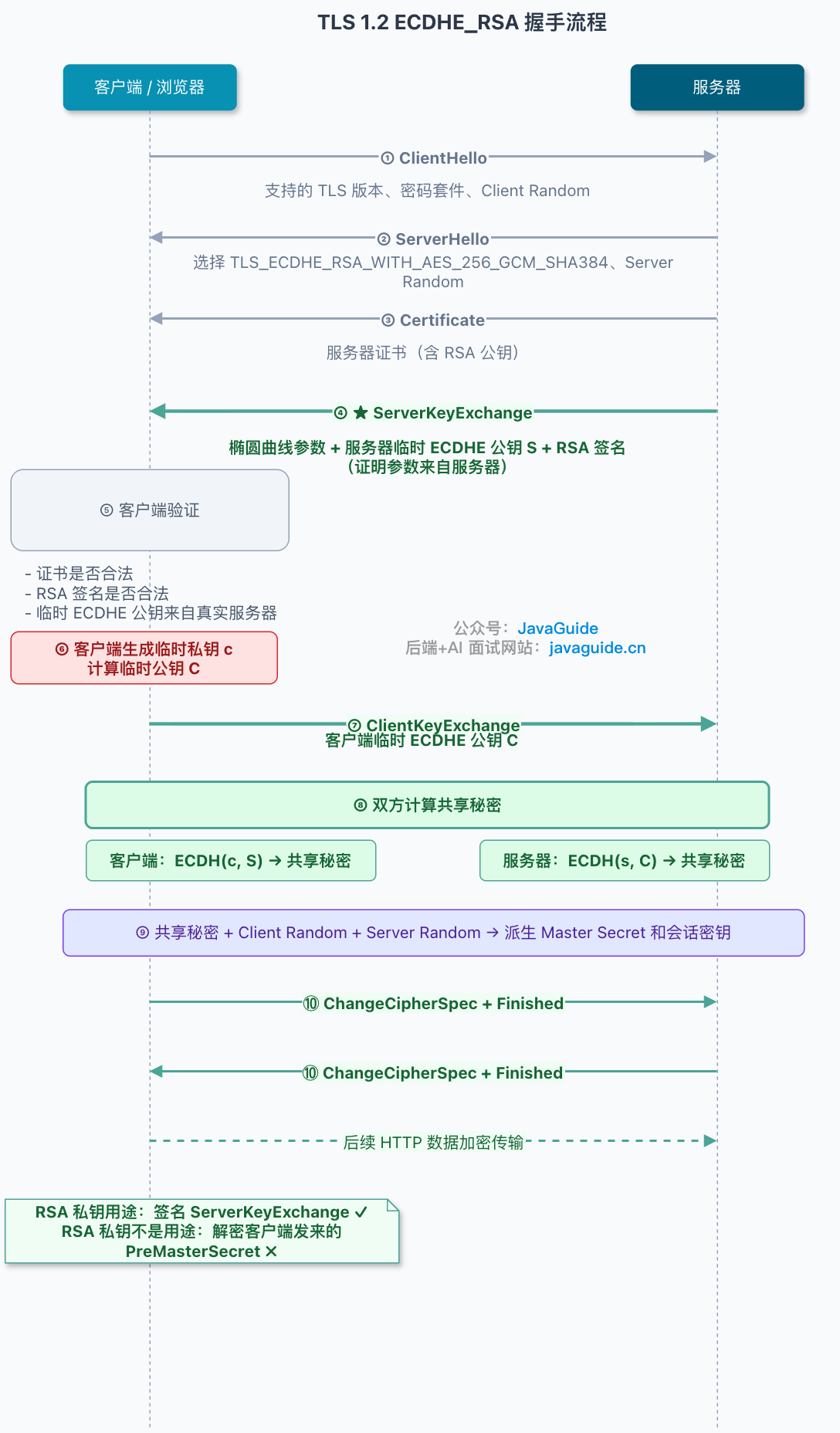
+再看 TLS 1.2 里常见的 `ECDHE_RSA` 握手。
+
+客户端还是先发 `ClientHello`,里面有 TLS 版本、支持的密码套件、`Client Random`。服务器回 `ServerHello`,选择一个密码套件,比如:
+
+```text
+TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
+```
+
+这个密码套件名要拆开看,不能看到 RSA 就以为它还在用 RSA 加密会话密钥。
+
+- `ECDHE` 表示密钥交换方式。
+- `RSA` 表示认证签名方式。
+- `AES_256_GCM` 表示后续记录数据使用 AES,密钥长度 256 位,模式是 GCM。
+- `SHA384` 指定 TLS 1.2 PRF 和 `Finished` 消息使用的哈希算法。
+
+GCM 本身已经提供记录层的完整性保护,所以这里的 `SHA384` 不再表示记录层 MAC,而是主要参与握手阶段的密钥派生和验证。
+
+服务端接着发证书。以 `ECDHE_RSA` 为例,证书里的 RSA 公钥主要用于验证服务端签名,而不是让客户端拿它加密 `PreMasterSecret`。
+
+然后,ECDHE 和 RSA 握手开始分叉。
+
+在 ECDHE 握手里,服务端会发送 `Server Key Exchange`。这个消息里会包含服务端选择的椭圆曲线参数,以及服务端临时 ECDHE 公钥。
+
+**问题来了:客户端怎么知道这份临时 ECDHE 公钥没有被中间人换掉?**
+
+**答案是签名。**
+
+服务端会用证书对应的私钥,对握手参数做签名。客户端收到后,用证书里的公钥验证签名。如果签名验证通过,客户端就能确认:这份临时 ECDHE 公钥确实来自持有证书私钥的服务器,不是路上被人替换的。
+
+随后客户端也生成自己的临时 ECDHE 私钥和公钥,把客户端临时公钥通过 `Client Key Exchange` 发给服务器。
+
+到这一步,双方都有了计算共享秘密需要的材料。
+
+客户端手里有:
+
+```text
+客户端临时私钥
+服务端临时公钥
+Client Random
+Server Random
+```
+
+服务端手里有:
+
+```text
+服务端临时私钥
+客户端临时公钥
+Client Random
+Server Random
+```
+
+两边各自计算出同一个共享秘密,再派生出后续使用的会话密钥。
+
+这里再强调一次:
+
+**ECDHE_RSA 里的 RSA,不是用来加密传输会话密钥的。它负责证明“这份 ECDHE 临时参数确实是服务器发的”。**
+
+这也是很多人看到密码套件名字后最容易误会的地方。
+
+
+
+### 密码套件名怎么读
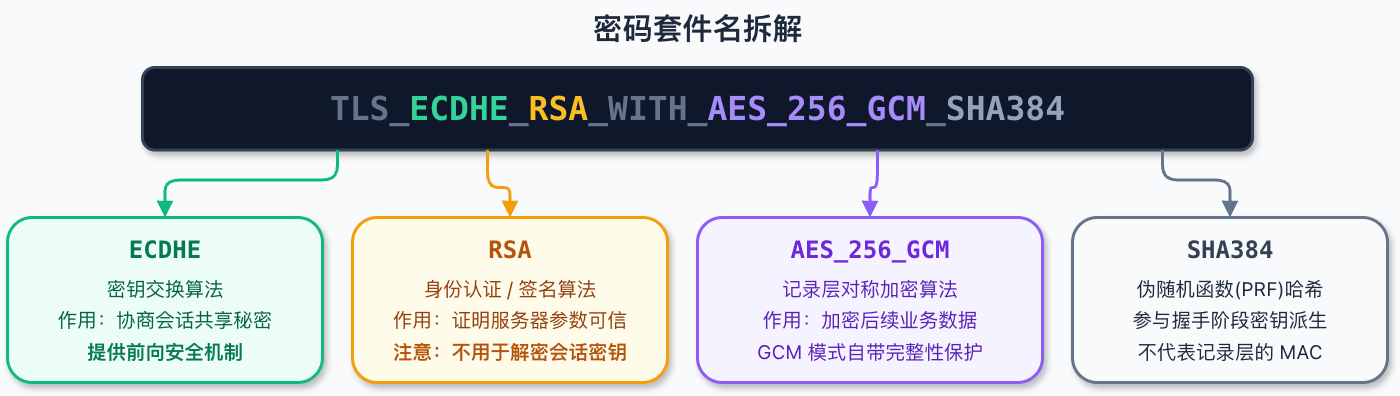
+
+TLS 1.2 的密码套件名字通常可以按这条线拆:
+
+```text
+TLS_密钥交换算法_认证算法_WITH_对称加密算法_哈希算法
+```
+
+例如:
+
+```text
+TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
+```
+
+可以拆成:
+
+```text
+ECDHE:密钥交换
+RSA:身份认证,也就是服务端签名
+AES_128_GCM:后续记录层加密算法
+SHA256:TLS 1.2 PRF 和 Finished 消息使用的哈希算法;如果是 GCM 套件,它不再充当记录层 MAC
+```
+
+再看另一个:
+
+```text
+TLS_RSA_WITH_AES_128_GCM_SHA256
+```
+
+这里的 `RSA` 出现在 `WITH` 前面,而且没有 `ECDHE`,表示密钥交换和身份认证都和 RSA 绑定。这类就是典型的静态 RSA 密钥交换套件。
+
+到了 TLS 1.3,密码套件命名变了,比如:
+
+```text
+TLS_AES_128_GCM_SHA256
+```
+
+你会发现,它不再把密钥交换和认证方式写进密码套件名里。TLS 1.3 把这些信息拆到其他扩展和握手消息中,密码套件名主要描述记录层 AEAD 算法和 HKDF 使用的哈希算法。
+
+所以,看到 TLS 1.3 的 `TLS_AES_128_GCM_SHA256`,不要误以为它“没有密钥交换”。密钥交换还在,只是不用 TLS 1.2 那套命名方式写出来了。
+
+
+
+## 前向安全与性能代价
+
+### ECDHE 为什么有前向安全
+
+关键在 `E`,也就是 `Ephemeral`,临时。
+
+ECDHE 握手里的私钥不是服务器证书那把长期私钥,而是握手过程中使用的临时私钥。连接结束后,正常情况下不应该再依赖这份临时材料。
+
+这带来的结果是:攻击者今天抓包,未来某天拿到了服务器证书私钥,也不能仅靠这把长期私钥还原过去每次握手里的临时共享秘密。因为当时真正参与密钥协商的是那次握手里的 ECDHE 临时私钥,而不是证书私钥。
+
+证书私钥在这里更像“签字笔”,不是“保险柜钥匙”。
+
+RSA 密钥交换里,服务器私钥可以直接打开客户端发来的 `PreMasterSecret`;ECDHE 里,服务器私钥只是给临时参数签名,证明身份。它不直接参与每次连接共享秘密的计算。
+
+这个角色变化,决定了两者在历史流量保护上的差异。
+
+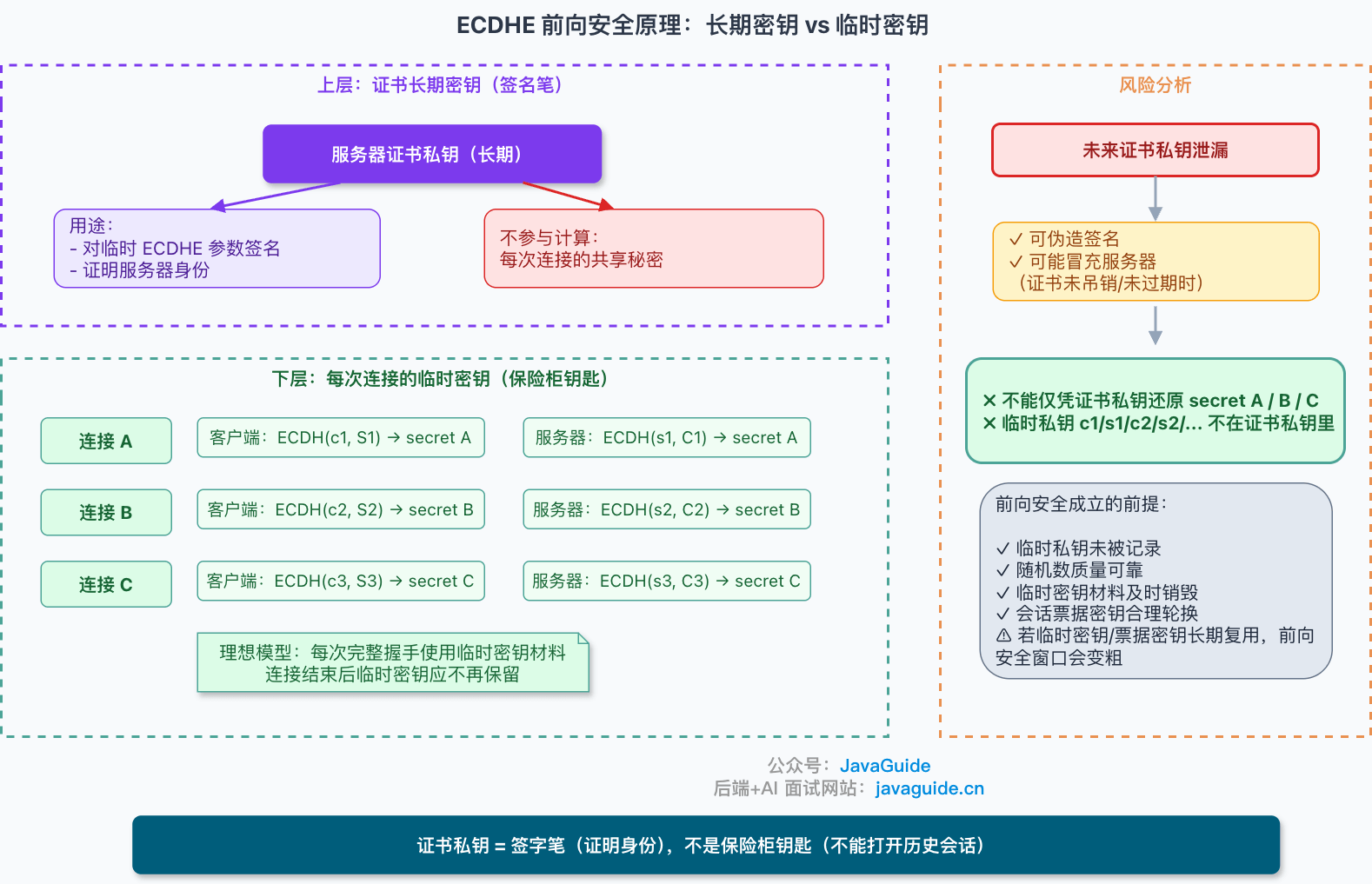
+
+不过,前向安全不是免死金牌。
+
+如果服务端随机数质量很差,临时私钥被日志记录下来,或者实现里出现内存泄漏,ECDHE 也救不了你。工程实现里,为了降低握手成本,部分实现还可能短时间复用临时 DH/ECDH 私密材料:有限域 DH 场景常说“指数复用”,ECDH 场景更常说“临时私钥/标量复用”。如果复用时间过长,前向安全的粒度就会变粗。
+
+还有一类风险来自参数校验。比如服务端没有正确校验客户端发来的椭圆曲线点是否在合法曲线上,就可能给无效曲线攻击留下空间。正常开发者不一定会直接写这层代码,但它提醒我们:密码学协议不只是“选对算法”就结束了,TLS 库实现和配置同样重要。
+
+### 会话恢复的影响
+
+还有一个容易被忽略的点:**会话恢复。**
+
+完整 ECDHE 握手要做临时密钥协商,成本不低。为了减少握手开销,TLS 支持会话恢复。客户端下次访问同一个站点时,可以尝试复用之前协商过的会话状态,避免每次都完整走一遍握手。
+
+问题在于,会话恢复也有自己的安全边界。
+
+以 TLS 1.2 的会话票据为例,服务端会用一把票据加密密钥保护会话状态,客户端后续带着票据回来,服务端解开票据后恢复会话。如果这把票据加密密钥长期不轮换,一旦它泄漏,攻击者就可能解开过去收集到的票据,并进一步还原相关恢复会话的密钥材料。
+
+这时,前向安全的窗口就不再是“一次连接”,而会被拉长到“票据加密密钥的生命周期”。
+
+所以线上配置不能只看“是否启用了 ECDHE”。会话票据密钥怎么生成、怎么轮换、是否在多台机器间共享、泄漏后影响多大,也要算进去。
+
+### 性能不是免费的
+
+ECDHE 带来了前向安全,但它也有成本。
+
+RSA 密钥交换的主路径,是服务端用长期 RSA 私钥解开客户端发来的 `PreMasterSecret`。ECDHE_RSA 则需要完成临时 ECDH 协商,还要对服务端临时参数做签名。
+
+对高并发服务来说,TLS 握手会消耗 CPU,尤其是短连接多、会话恢复命中率低的时候。
+
+这里不能简单写成“ECDHE 一定比 RSA 慢”。实际开销取决于 RSA 密钥长度、椭圆曲线选择、签名算法、TLS 库实现、CPU 指令集、会话恢复命中率等因素。比如 X25519、P-256、RSA 2048、RSA 3072 在不同 CPU 和不同 TLS 库上的表现都不一样。
+
+如果真要判断成本,最靠谱的方法不是引用别人的固定数字,而是在目标机器上压测。至少要区分三件事:
+
+```text
+1. 单次密码学操作耗时
+2. 完整 TLS 握手耗时
+3. 业务请求端到端耗时
+```
+
+第一项可以用 `openssl speed` 粗看数量级,比如测试 RSA、ECDH、X25519 的运算能力;第二项要看 TLS 库和服务端配置;第三项还会受网络、连接复用、应用逻辑影响。
+
+所以线上不会只靠“换成 ECDHE”解决所有问题。更常见的做法是配合 TLS 1.3、会话恢复、合理的证书算法和曲线选择,必要时再用硬件加速。
+
+安全性和性能不是二选一,但也不能假装没有成本。
+
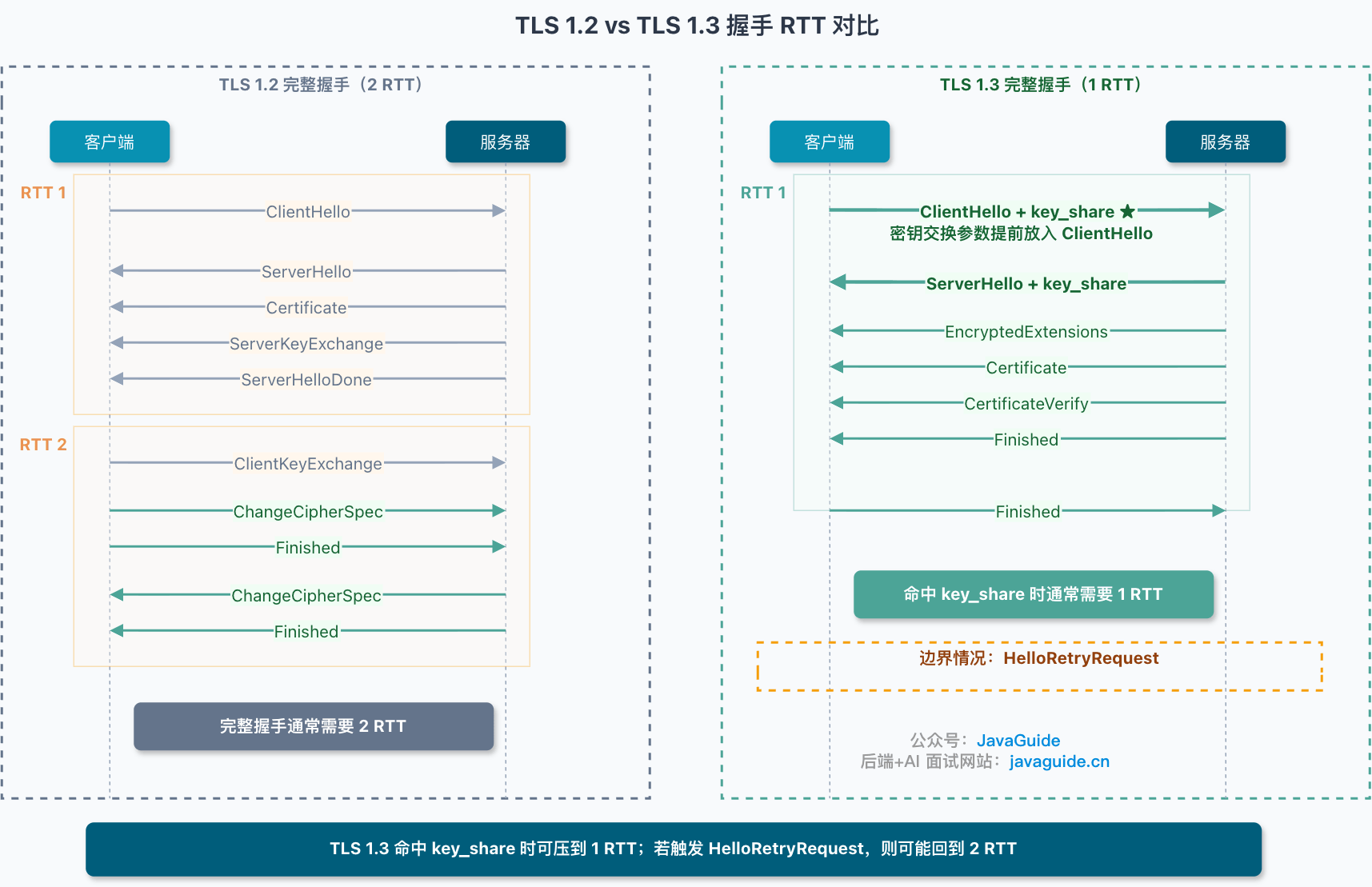
+## TLS 1.3 的变化
+
+如果只看 TLS 1.2,RSA 和 ECDHE 可以作为两种密钥交换方式来对比。
+
+但到了 TLS 1.3,静态 RSA 密钥交换已经被移除,握手结构也改了。
+
+TLS 1.2 完整握手通常需要 2 个 RTT。客户端先发 `ClientHello`,服务端回 `ServerHello`、证书和相关握手消息,客户端再发密钥交换和 `Finished`,服务端最后回 `Finished`。
+
+TLS 1.3 则把密钥交换参数提前放进 `ClientHello` 的 `key_share`。服务端第一轮响应就能返回自己的 `key_share`,完整握手通常压到 1 个 RTT。
+
+2 RTT 变 1 RTT 能省多少毫秒,取决于网络环境。同机房可能只是几毫秒;跨地域、移动网络、高丢包场景下,少一个 RTT 才更容易被感知。
+
+不过,TLS 1.3 也不是任何情况下都稳稳 1 RTT。如果客户端带的 `key_share` 和服务端支持的曲线不匹配,服务端会返回 `HelloRetryRequest`,要求客户端换一组参数再来一次。这时握手可能重新接近 2 RTT。
+
+所以生产环境里,客户端和服务端对常见密钥协商组的支持要尽量对齐,比如 `X25519`、`secp256r1` 这类常见选择。否则 TLS 1.3 的 1 RTT 优势可能打折。
+
+
+
+至于后量子混合密钥交换、0-RTT、PSK-only、mTLS,这些都属于另一条线,本文不展开。
+
+## RSA vs ECDHE 核心差异速查
+
+放到一起看,差异就很清楚了。
+
+| 对比项 | RSA 密钥交换 | ECDHE 密钥交换 |
+| ------------------ | ------------------------------------------------------- | ------------------------------------------------------ |
+| 常见版本背景 | TLS 1.2 及更早版本可见 | TLS 1.2 常见,TLS 1.3 延续临时密钥协商方向 |
+| 会话密钥材料怎么来 | 客户端生成 `PreMasterSecret`,用服务器 RSA 公钥加密发送 | 双方各自生成临时密钥对,通过 ECDHE 算出共享秘密 |
+| 服务器私钥的作用 | 解密客户端发来的 `PreMasterSecret` | 对临时 ECDHE 参数签名,证明参数来自真实服务端 |
+| 网络上传了什么 | 加密后的 `PreMasterSecret` | 双方临时公钥和签名后的参数 |
+| 是否支持前向安全 | 不支持 | 支持,前提是临时密钥正确生成、使用后不再保留 |
+| 私钥泄漏后的影响 | 在握手数据完整捕获的情况下,历史流量可能被解密 | 仅靠证书私钥,通常无法解开历史流量 |
+| 典型问题 | 长期私钥价值过高,存在 PKCS#1 v1.5 填充预言机历史包袱 | 握手有额外计算成本,参数校验和临时密钥管理依赖实现质量 |
+| TLS 1.3 情况 | 静态 RSA 密钥交换已移除 | 临时密钥协商成为主线 |
+
+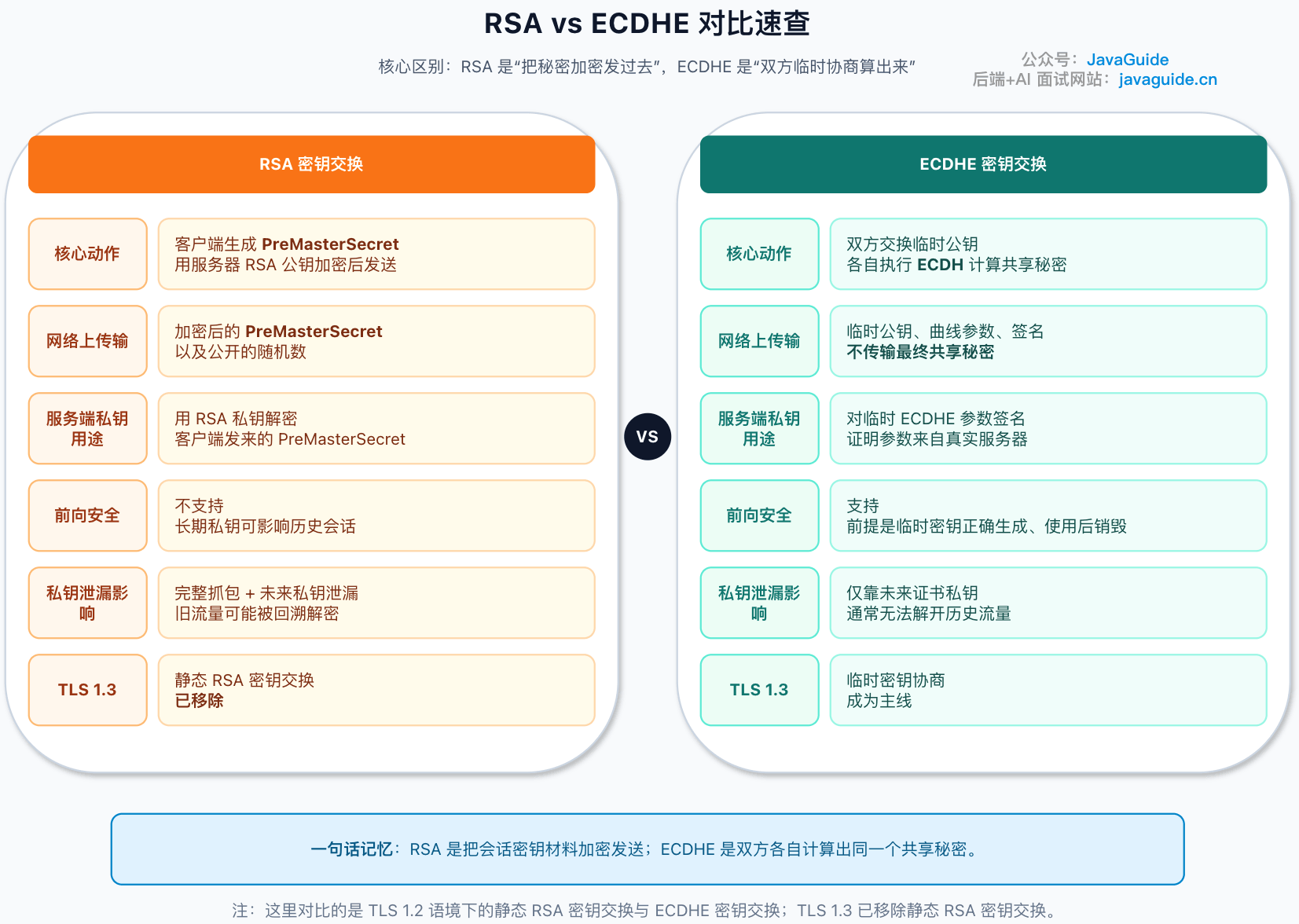
+
+如果你要在面试里快速讲,可以这样说:
+
+**RSA 握手是“客户端生成秘密,用服务器公钥加密发过去”;ECDHE 握手是“双方交换临时公钥,各自算出同一个秘密”。RSA 的服务器私钥能解历史握手材料,所以没有前向安全;ECDHE 的证书私钥只做签名认证,不直接解会话秘密,所以更适合现代 HTTPS。**
+
+这段就够用了。
+
+### 常见误读:ECDHE_RSA 不是两种算法都加密
+
+再单独说一下 `ECDHE_RSA`,因为这个名字太容易让人误读。
+
+很多人看到:
+
+```text
+TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
+```
+
+第一反应是:是不是先做一轮 ECDHE 运算,再做一轮 RSA 加密?
+
+不是。
+
+在这个密码套件里:
+
+密钥交换用 ECDHE;
+身份认证用 RSA 签名;
+后续数据加密用 AES-256-GCM;
+相关哈希使用 SHA384。
+
+这也解释了为什么“HTTPS 还在用 RSA”这句话要小心说。
+
+用 RSA 做证书签名,和用 RSA 做密钥交换,是两件事。
+
+前者在现代 HTTPS 里仍然常见,后者已经不适合作为现代 TLS 的主线。
+
+### RSA 在现代 HTTPS 里的实际角色
+
+学习 HTTPS 握手时,很多入门资料喜欢用一句话概括:
+
+非对称加密交换对称密钥。
+
+这句话在入门阶段有帮助,但不够准确。它更像是在描述早期 RSA 密钥交换的思路。
+
+到了 ECDHE,密钥不是简单“加密后传输”,而是双方协商出来的。到了 TLS 1.3,密钥交换、身份认证、记录层加密的边界更清楚:临时密钥协商负责生成共享秘密,证书负责身份认证,对称加密负责保护后续应用数据。
+
+更准确的说法应该是:
+
+HTTPS 的业务数据通常用对称密钥加密;TLS 握手负责协商这份密钥并验证身份。RSA 可以参与身份认证,也曾经可以参与密钥交换;ECDHE 负责临时密钥协商,能避免历史会话因为未来证书私钥泄漏而直接暴露。
+
+如果把这几件事混在一起,就很容易得出错误结论:看到 RSA 就以为它在加密会话密钥,看到 ECDHE_RSA 就以为两种算法都在做加密。
+
+事实不是这样。
+
+## 用一次完整请求串起来
+
+浏览器访问一个 HTTPS 网站时,TCP 连接先建立起来。接着 TLS 握手开始。
+
+如果是 TLS 1.2 的 RSA 密钥交换,客户端验证证书后,生成 48 字节的 `PreMasterSecret`,用服务器证书里的 RSA 公钥加密发给服务器。服务器用 RSA 私钥解密,双方再结合两个随机数派生会话密钥。
+
+如果是 TLS 1.2 的 ECDHE_RSA,服务器发证书后,还会发 `Server Key Exchange`,里面带着临时 ECDHE 公钥和签名。客户端验证签名后,也生成自己的临时 ECDHE 公钥发回去。双方不传输最终共享秘密,而是各自算出同一个共享秘密,再派生会话密钥。
+
+这两个流程看起来只差了几个握手消息,安全性质却差很多。
+
+RSA 密钥交换的问题是历史包袱太重:长期私钥一旦泄漏,过去保存下来的流量也可能遭殃;再加上 PKCS#1 v1.5 填充预言机这类实现风险,它已经不适合作为现代 TLS 密钥交换方案。
+
+ECDHE 把每次连接的密钥协商换成临时过程,让服务器长期私钥不再成为打开历史流量的钥匙。它也有计算成本,也依赖正确实现和配置,但方向更符合现代 HTTPS 的安全要求。
+
+这篇文章只聚焦一个问题:**RSA 密钥交换和 ECDHE 密钥交换到底差在哪**。如果继续往下讲,还可以展开 TLS 1.3 的 0-RTT、PSK、会话票据轮换、mTLS、证书透明、后量子迁移,这些都值得单独写。
+
+所以,面试里问“RSA 和 ECDHE 握手有什么区别”,不要只回答“一个不支持前向安全,一个支持前向安全”。
+
+真正要讲的是:
+
+**RSA 是把秘密加密送过去;ECDHE 是双方临时协商出来。**
+
+把这句话讲透,后面的 `PreMasterSecret`、`Server Key Exchange`、前向安全、TLS 1.3 为什么移除静态 RSA,就都能顺着讲下去了。
diff --git a/docs/cs-basics/network/images/Cut-Trough-Switching_0.gif b/docs/cs-basics/network/images/Cut-Trough-Switching_0.gif
deleted file mode 100644
index 3c477860cb8..00000000000
Binary files a/docs/cs-basics/network/images/Cut-Trough-Switching_0.gif and /dev/null differ
diff --git a/docs/cs-basics/network/images/arp/arp_different_lan.png b/docs/cs-basics/network/images/arp/arp_different_lan.png
new file mode 100644
index 00000000000..8cfe4445076
Binary files /dev/null and b/docs/cs-basics/network/images/arp/arp_different_lan.png differ
diff --git a/docs/cs-basics/network/images/arp/arp_same_lan.png b/docs/cs-basics/network/images/arp/arp_same_lan.png
new file mode 100644
index 00000000000..9137cb7ed3e
Binary files /dev/null and b/docs/cs-basics/network/images/arp/arp_same_lan.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/HTTP1.0cache1.png b/docs/cs-basics/network/images/http-vs-https/HTTP1.0cache1.png
new file mode 100644
index 00000000000..a57c774d40f
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/HTTP1.0cache1.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/HTTP1.0cache2.png b/docs/cs-basics/network/images/http-vs-https/HTTP1.0cache2.png
new file mode 100644
index 00000000000..f74da56cf96
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/HTTP1.0cache2.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/HTTP1.1continue1.png b/docs/cs-basics/network/images/http-vs-https/HTTP1.1continue1.png
new file mode 100644
index 00000000000..5943d22ce0e
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/HTTP1.1continue1.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/HTTP1.1continue2.png b/docs/cs-basics/network/images/http-vs-https/HTTP1.1continue2.png
new file mode 100644
index 00000000000..5181160087a
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/HTTP1.1continue2.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/OWF.png b/docs/cs-basics/network/images/http-vs-https/OWF.png
new file mode 100644
index 00000000000..426c7e29457
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/OWF.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/attack1.png b/docs/cs-basics/network/images/http-vs-https/attack1.png
new file mode 100644
index 00000000000..fd6e9dff4e9
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/attack1.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/digital-signature.png b/docs/cs-basics/network/images/http-vs-https/digital-signature.png
new file mode 100644
index 00000000000..391b83f3a88
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/digital-signature.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/public-key-cryptography.png b/docs/cs-basics/network/images/http-vs-https/public-key-cryptography.png
new file mode 100644
index 00000000000..a6c4143ff7e
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/public-key-cryptography.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/public-key-transmission.png b/docs/cs-basics/network/images/http-vs-https/public-key-transmission.png
new file mode 100644
index 00000000000..ab49670ec42
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/public-key-transmission.png differ
diff --git a/docs/cs-basics/network/images/http-vs-https/symmetric-encryption.png b/docs/cs-basics/network/images/http-vs-https/symmetric-encryption.png
new file mode 100644
index 00000000000..cc9cfbc0e5d
Binary files /dev/null and b/docs/cs-basics/network/images/http-vs-https/symmetric-encryption.png differ
diff --git a/docs/cs-basics/network/images/isp.png b/docs/cs-basics/network/images/isp.png
deleted file mode 100644
index 8749fb1de44..00000000000
Binary files a/docs/cs-basics/network/images/isp.png and /dev/null differ
diff --git a/docs/cs-basics/network/images/network-model/nerwork-layer-protocol.png b/docs/cs-basics/network/images/network-model/nerwork-layer-protocol.png
new file mode 100644
index 00000000000..a94274cce32
Binary files /dev/null and b/docs/cs-basics/network/images/network-model/nerwork-layer-protocol.png differ
diff --git "a/docs/cs-basics/network/images/\344\274\240\350\276\223\345\261\202.png" "b/docs/cs-basics/network/images/\344\274\240\350\276\223\345\261\202.png"
deleted file mode 100644
index b3b444279f1..00000000000
Binary files "a/docs/cs-basics/network/images/\344\274\240\350\276\223\345\261\202.png" and /dev/null differ
diff --git "a/docs/cs-basics/network/images/\345\272\224\347\224\250\345\261\202.png" "b/docs/cs-basics/network/images/\345\272\224\347\224\250\345\261\202.png"
deleted file mode 100644
index 448bfa86319..00000000000
Binary files "a/docs/cs-basics/network/images/\345\272\224\347\224\250\345\261\202.png" and /dev/null differ
diff --git "a/docs/cs-basics/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png" "b/docs/cs-basics/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png"
deleted file mode 100644
index c941594e365..00000000000
Binary files "a/docs/cs-basics/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png" and /dev/null differ
diff --git "a/docs/cs-basics/network/images/\347\211\251\347\220\206\345\261\202.png" "b/docs/cs-basics/network/images/\347\211\251\347\220\206\345\261\202.png"
deleted file mode 100644
index 447a7b295b0..00000000000
Binary files "a/docs/cs-basics/network/images/\347\211\251\347\220\206\345\261\202.png" and /dev/null differ
diff --git "a/docs/cs-basics/network/images/\347\275\221\347\273\234\345\261\202.png" "b/docs/cs-basics/network/images/\347\275\221\347\273\234\345\261\202.png"
deleted file mode 100644
index 9bb67b9fe6b..00000000000
Binary files "a/docs/cs-basics/network/images/\347\275\221\347\273\234\345\261\202.png" and /dev/null differ
diff --git "a/docs/cs-basics/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png" "b/docs/cs-basics/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png"
deleted file mode 100644
index 75349e78204..00000000000
Binary files "a/docs/cs-basics/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png" and /dev/null differ
diff --git a/docs/cs-basics/network/nat.md b/docs/cs-basics/network/nat.md
new file mode 100644
index 00000000000..657a4e39d5b
--- /dev/null
+++ b/docs/cs-basics/network/nat.md
@@ -0,0 +1,76 @@
+---
+title: NAT 协议详解(网络层)
+description: 解析 NAT 的地址转换与端口映射机制,结合 LAN/WAN 通信与转换表,理解家庭与企业网络的实践细节。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: NAT,地址转换,端口映射,LAN,WAN,连接跟踪,DHCP
+---
+
+很多设备在家用网络、公司内网里使用的都是私有 IP 地址,比如 `192.168.x.x`、`10.x.x.x`。这些地址不能直接在公网中路由,但内网设备依然可以访问互联网。
+
+这背后通常就有 NAT 在工作。NAT 会在内网地址和公网地址之间做转换,让多个内网设备共享一个或少量公网 IP 对外通信。
+
+这篇文章主要回答几个问题:
+
+1. NAT 主要解决什么问题?
+2. NAT 转换表是如何记录内外网地址和端口映射的?
+3. 内网主机访问公网时,源 IP 和端口会发生什么变化?
+4. NAT 会带来哪些限制,比如外部主动访问内网主机为什么更麻烦?
+
+## 应用场景
+
+**NAT 协议(Network Address Translation)** 的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,Local Area Network,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(Wide Area Network,WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
+
+这个场景其实不难理解。随着一个个小型办公室、家庭办公室(Small Office, Home Office, SOHO)的出现,为了管理这些 SOHO,一个个子网被设计出来,从而在整个 Internet 中的主机数量将非常庞大。如果每个主机都有一个“绝对唯一”的 IP 地址,那么 IPv4 地址的表达能力可能很快达到上限($2^{32}$)。因此,实际上,SOHO 子网中的 IP 地址是“相对的”,这在一定程度上也缓解了 IPv4 地址的分配压力。
+
+SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器扮演。路由器的 LAN 一侧管理着一个小子网,而它的 WAN 接口才是真正参与到 Internet 中的接口,也就有一个“绝对唯一的地址”。NAT 协议,正是在 LAN 中的主机在与 LAN 外界通信时,起到了地址转换的关键作用。
+
+## 细节
+
+
+
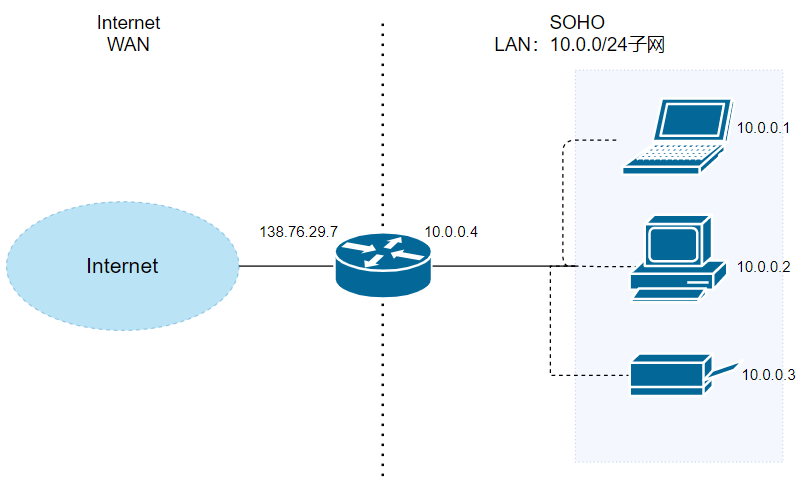
+假设当前场景如上图。中间是一个路由器,它的右侧组织了一个 LAN,网络号为 `10.0.0/24`。LAN 侧接口的 IP 地址为 `10.0.0.4`,并且该子网内有至少三台主机,分别是 `10.0.0.1`、`10.0.0.2` 和 `10.0.0.3`。路由器的左侧连接的是 WAN,WAN 侧接口的 IP 地址为 `138.76.29.7`。
+
+首先,针对以上信息,我们有如下事实需要说明:
+
+1. 路由器右侧子网的网络地址为 `10.0.0.0/24`(网络前缀 24 位,主机号占 8 位),三台主机地址以及路由器的 LAN 侧接口地址,均由 DHCP 协议规定。而且,该 DHCP 运行在路由器内部(路由器自维护一个小 DHCP 服务器),从而为子网内提供 DHCP 服务。
+2. 路由器的 WAN 侧接口地址同样由 DHCP 协议规定,但该地址是路由器从 ISP(网络服务提供商)处获得,也就是该 DHCP 通常运行在路由器所在区域的 DHCP 服务器上。
+
+现在,路由器内部还运行着 NAT 协议,从而为 LAN-WAN 间通信提供地址转换服务。为此,一个很重要的结构是 **NAT 转换表**。为了说明 NAT 的运行细节,假设有以下请求发生:
+
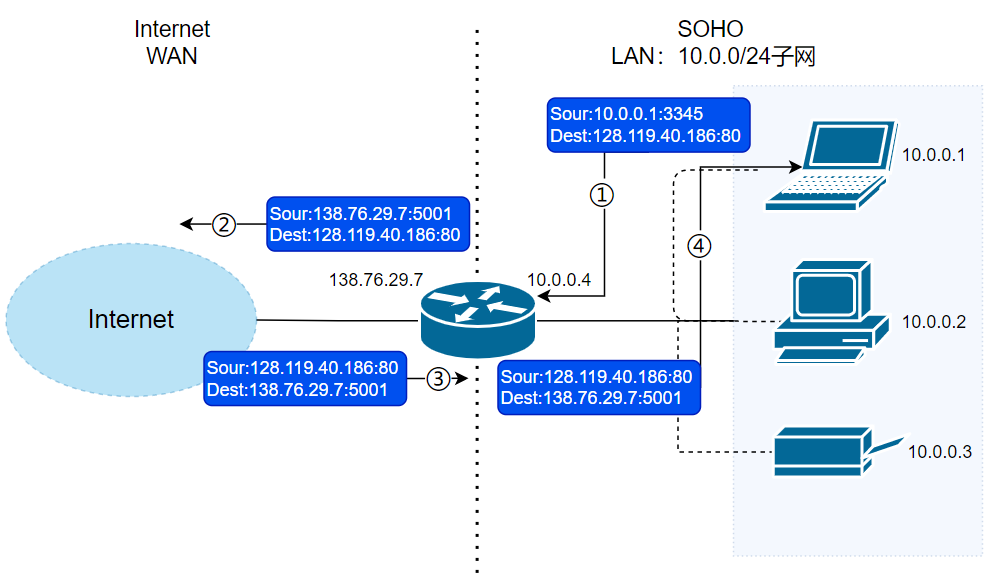
+1. 主机 `10.0.0.1` 向 IP 地址为 `128.119.40.186` 的 Web 服务器(端口 80)发送了 HTTP 请求(如请求页面)。此时,主机 `10.0.0.1` 将随机指派一个端口,如 `3345`,作为本次请求的源端口号,将该请求发送到路由器中(目的地址将是 `128.119.40.186`,但会先到达 `10.0.0.4`)。
+2. `10.0.0.4` 即路由器的 LAN 接口收到 `10.0.0.1` 的请求。路由器将为该请求指派一个新的源端口号,如 `5001`,并将请求报文发送给 WAN 接口 `138.76.29.7`。同时,在 NAT 转换表中记录一条转换记录 **138.76.29.7:5001——10.0.0.1:3345**。
+3. 请求报文到达 WAN 接口,继续向目的主机 `128.119.40.186` 发送。
+
+之后,将会有如下响应发生:
+
+1. 主机 `128.119.40.186` 收到请求,构造响应报文,并将其发送给目的地 `138.76.29.7:5001`。
+2. 响应报文到达路由器的 WAN 接口。路由器查询 NAT 转换表,发现 `138.76.29.7:5001` 在转换表中有记录,从而将其目的地址和目的端口转换成为 `10.0.0.1:3345`,再发送到 `10.0.0.4` 上。
+3. 被转换的响应报文到达路由器的 LAN 接口,继而被转发至目的地 `10.0.0.1`。
+
+
+
+🐛 修正(参见:[issue#2009](https://github.com/Snailclimb/JavaGuide/issues/2009)):上图第四步的 Dest 值应该为 `10.0.0.1:3345` 而不是~~`138.76.29.7:5001`~~,这里笔误了。
+
+## 划重点
+
+针对以上过程,有以下几个重点需要强调:
+
+1. 当请求报文到达路由器,并被指定了新端口号时,由于端口号有 16 位,因此,通常来说,一个路由器管理的 LAN 中的最大主机数 $≈65500$($2^{16}$ 的地址空间),但通常 SOHO 子网内不会有如此多的主机数量。
+2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自 `138.76.29.7:5001` 的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用**,所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
+3. 在报文穿过路由器,发生 NAT 转换时,如果 LAN 主机 IP 已经在 NAT 转换表中注册过了,则不需要路由器新指派端口,而是直接按照转换记录穿过路由器。同理,外部报文发送至内部时也如此。
+
+总结 NAT 协议的特点,有以下几点:
+
+1. NAT 协议通过对 WAN 屏蔽 LAN,有效地缓解了 IPv4 地址分配压力。
+2. LAN 主机 IP 地址的变更,无需通告 WAN。
+3. WAN 的 ISP 变更接口地址时,无需通告 LAN 内主机。
+4. LAN 主机对 WAN 不可见,不可直接寻址,可以保证一定程度的安全性。
+
+然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的**。这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
+
+
diff --git a/docs/cs-basics/network/network-attack-means.md b/docs/cs-basics/network/network-attack-means.md
new file mode 100644
index 00000000000..0f5546229c6
--- /dev/null
+++ b/docs/cs-basics/network/network-attack-means.md
@@ -0,0 +1,483 @@
+---
+title: 网络攻击常见手段总结(安全)
+description: 总结常见 TCP/IP 攻击与防护思路,覆盖 DDoS、IP/ARP 欺骗、中间人等手段,强调工程防护实践。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 网络攻击,DDoS,IP 欺骗,ARP 欺骗,中间人攻击,扫描,防护
+---
+
+> 本文整理完善自[TCP/IP 常见攻击手段 - 暖蓝笔记 - 2021](https://mp.weixin.qq.com/s/AZwWrOlLxRSSi-ywBgZ0fA)这篇文章。
+
+TCP/IP 协议栈追求互联互通,但很多机制在设计之初并没有把今天的攻击规模和对抗强度都考虑进去。
+
+IP 欺骗、SYN Flood、DDoS、ARP 欺骗、DNS 劫持这些攻击,表面上各不相同,本质上都在利用网络协议里的信任假设、资源消耗点或解析链路。
+
+这篇文章主要回答几个问题:
+
+1. TCP/IP 常见攻击手段分别利用了什么机制?
+2. IP 欺骗、SYN Flood、DDoS 等攻击大致是怎么发生的?
+3. 常见网络攻击会造成哪些影响?
+4. 面对这些攻击,通常有哪些基础防御思路?
+
+## IP 欺骗
+
+### IP 是什么?
+
+在网络中,所有的设备都会分配一个地址。这个地址就仿佛小蓝的家地址「**多少号多少室**」,这个号就是分配给整个子网的,「**室**」对应的号码即分配给子网中计算机的,这就是网络中的地址。「号」对应的号码为网络号,「**室**」对应的号码为主机号,这个地址的整体就是 **IP 地址**。
+
+### 通过 IP 地址我们能知道什么?
+
+通过 IP 地址,我们就可以判断访问对象服务器的位置,从而将消息发送到服务器。一般发送者发出的消息首先经过子网的集线器,转发到最近的路由器,然后根据路由位置访问下一个路由器的位置,直到终点。
+
+**IP 头部格式**:
+
+
+
+### IP 欺骗技术是什么?
+
+骗呗,拐骗,诱骗!
+
+IP 欺骗技术就是伪造某台主机的 IP 地址的技术。通过 IP 地址的伪装使得某台主机能够伪装另外的一台主机,而这台主机往往具有某种特权或者被另外的主机所信任。
+
+假设现在有一个合法用户 **(1.1.1.1)** 已经同服务器建立正常的连接,攻击者构造攻击的 TCP 数据,伪装自己的 IP 为 **1.1.1.1**,并向服务器发送一个带有 RST 位的 TCP 数据段。服务器接收到这样的数据后,认为从 **1.1.1.1** 发送的连接有错误,就会清空缓冲区中建立好的连接。
+
+这时,如果合法用户 **1.1.1.1** 再发送合法数据,服务器就已经没有这样的连接了,该用户就必须从新开始建立连接。攻击时,伪造大量的 IP 地址,向目标发送 RST 数据,使服务器不对合法用户服务。虽然 IP 地址欺骗攻击有着相当难度,但我们应该清醒地意识到,这种攻击非常广泛,入侵往往从这种攻击开始。
+
+
+
+### 如何缓解 IP 欺骗?
+
+虽然无法预防 IP 欺骗,但可以采取措施来阻止伪造数据包渗透网络。**入口过滤** 是防范欺骗的一种极为常见的防御措施,如 BCP38(通用最佳实践文档)所示。入口过滤是一种数据包过滤形式,通常在[网络边缘](https://www.cloudflare.com/learning/serverless/glossary/what-is-edge-computing/)设备上实施,用于检查传入的 IP 数据包并确定其源标头。如果这些数据包的源标头与其来源不匹配或者看上去很可疑,则拒绝这些数据包。一些网络还实施出口过滤,检查退出网络的 IP 数据包,确保这些数据包具有合法源标头,以防止网络内部用户使用 IP 欺骗技术发起出站恶意攻击。
+
+## SYN Flood(洪水)
+
+### SYN Flood 是什么?
+
+SYN Flood 是互联网上最原始、最经典的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击之一,旨在耗尽可用服务器资源,致使服务器无法传输合法流量。
+
+SYN Flood 利用了 TCP 协议的三次握手机制,攻击者通常利用工具或者控制僵尸主机向服务器发送海量的变源 IP 地址或变源端口的 TCP SYN 报文,服务器响应了这些报文后就会生成大量的半连接,当系统资源被耗尽后,服务器将无法提供正常的服务。
+增加服务器性能、提供更多的连接能力对于 SYN Flood 的海量报文来说杯水车薪。防御 SYN Flood 的关键在于判断哪些连接请求来自于真实源,屏蔽非真实源的请求以保障正常的业务请求能得到服务。
+
+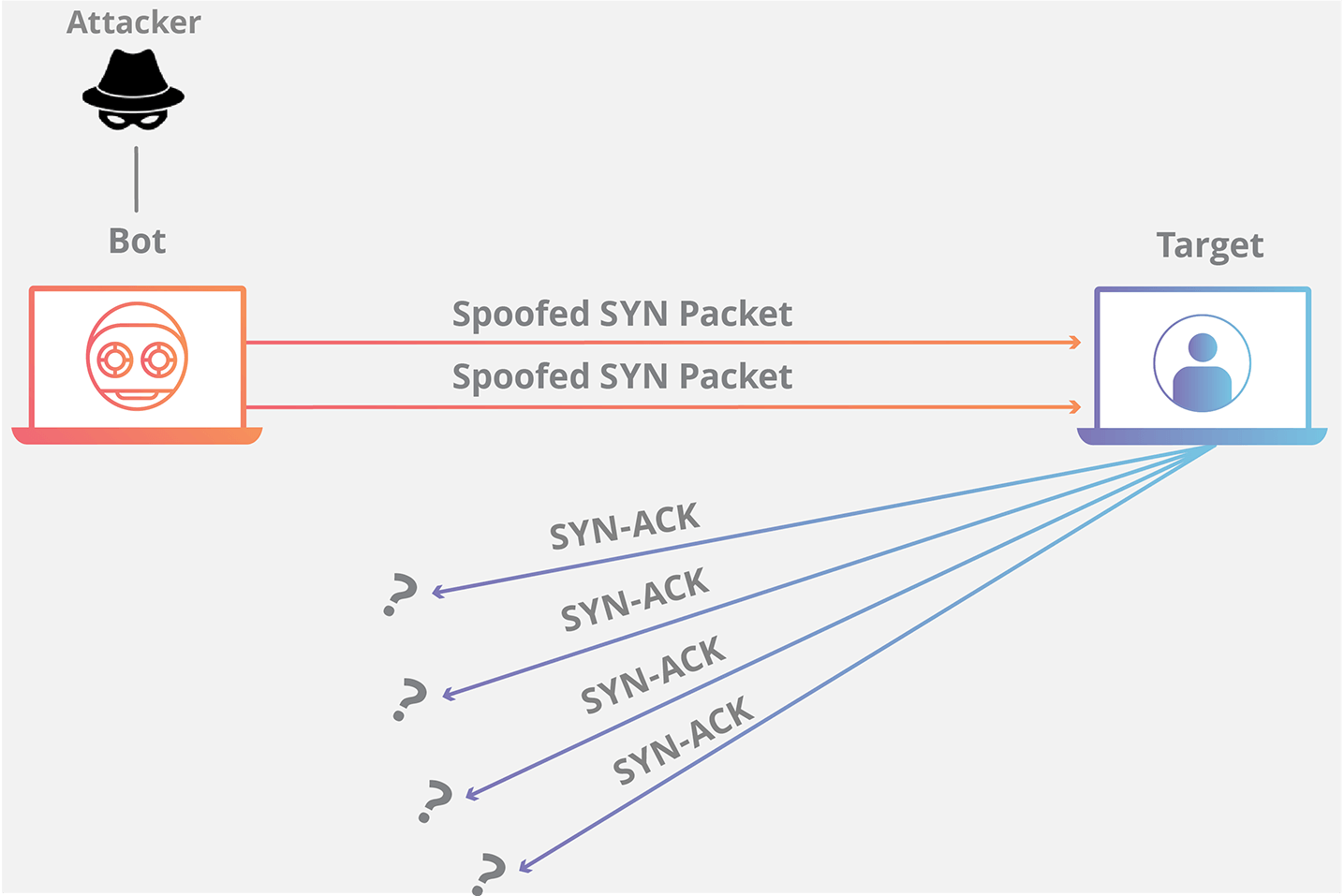
+
+### TCP SYN Flood 攻击原理是什么?
+
+**TCP SYN Flood** 攻击利用的是 **TCP** 的三次握手(**SYN -> SYN/ACK -> ACK**),假设连接发起方是 A,连接接受方是 B,即 B 在某个端口(**Port**)上监听 A 发出的连接请求,过程如下图所示,左边是 A,右边是 B。
+
+
+
+A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收数据的准备;B 收到后反馈 **SYN-ACK**(Synchronization-Acknowledgement) 消息给 A,这个消息的目的有两个:
+
+- 向 A 确认已做好接收数据的准备,
+- 同时要求 A 也做好接收数据的准备,此时 B 已向 A 确认好接收状态,并等待 A 的确认,连接处于**半开状态(Half-Open)**,顾名思义只开了一半;A 收到后再次发送 **ACK** (Acknowledgement) 消息给 B,向 B 确认也做好了接收数据的准备,至此三次握手完成,「**连接**」就建立了,
+
+大家注意到没有,最关键的一点在于双方是否都按对方的要求进入了**可以接收消息**的状态。而这个状态的确认主要是双方将要使用的**消息序号(**SequenceNum),**TCP** 为保证消息按发送顺序抵达接收方的上层应用,需要用**消息序号**来标记消息的发送先后顺序的。
+
+**TCP**是「**双工**」(Duplex)连接,同时支持双向通信,也就是双方同时可向对方发送消息,其中 **SYN** 和 **SYN-ACK** 消息开启了 A→B 的单向通信通道(B 获知了 A 的消息序号);**SYN-ACK** 和 **ACK** 消息开启了 B→A 单向通信通道(A 获知了 B 的消息序号)。
+
+上面讨论的是双方在诚实守信,正常情况下的通信。
+
+但实际情况是,网络可能不稳定会丢包,使握手消息不能抵达对方,也可能是对方故意不按规矩来,故意延迟或不发送握手确认消息。
+
+假设 B 通过某 **TCP** 端口提供服务,B 在收到 A 的 **SYN** 消息时,积极的反馈了 **SYN-ACK** 消息,使连接进入**半开状态**,因为 B 不确定自己发给 A 的 **SYN-ACK** 消息或 A 反馈的 ACK 消息是否会丢在半路,所以会给每个待完成的半开连接都设一个**Timer**,如果超过时间还没有收到 A 的 **ACK** 消息,则重新发送一次 **SYN-ACK** 消息给 A,直到重试超过一定次数时才会放弃。
+
+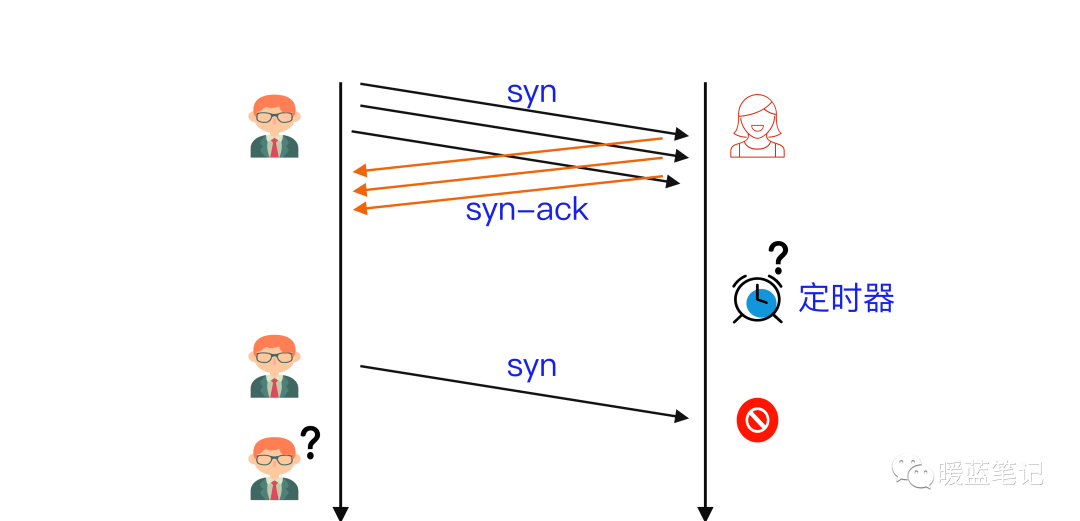
+
+B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接,那么当 B 面临海量的连接 A 时,如上图所示,**SYN Flood** 攻击就形成了。攻击方 A 可以控制肉鸡向 B 发送大量 SYN 消息但不响应 ACK 消息,或者干脆伪造 SYN 消息中的 **Source IP**,使 B 反馈的 **SYN-ACK** 消息石沉大海,导致 B 被大量注定不能完成的半开连接占据,直到资源耗尽,停止响应正常的连接请求。
+
+### SYN Flood 的常见形式有哪些?
+
+恶意用户可通过三种不同方式发起 SYN Flood 攻击:
+
+1. **直接攻击:** 不伪造 IP 地址的 SYN 洪水攻击称为直接攻击。在此类攻击中,攻击者完全不屏蔽其 IP 地址。由于攻击者使用具有真实 IP 地址的单一源设备发起攻击,因此很容易发现并清理攻击者。为使目标机器呈现半开状态,黑客将阻止个人机器对服务器的 SYN-ACK 数据包做出响应。为此,通常采用以下两种方式实现:部署防火墙规则,阻止除 SYN 数据包以外的各类传出数据包;或者,对传入的所有 SYN-ACK 数据包进行过滤,防止其到达恶意用户机器。实际上,这种方法很少使用(即便使用过也不多见),因为此类攻击相当容易缓解 – 只需阻止每个恶意系统的 IP 地址。哪怕攻击者使用僵尸网络(如 [Mirai 僵尸网络](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/)),通常也不会刻意屏蔽受感染设备的 IP。
+2. **欺骗攻击:** 恶意用户还可以伪造其发送的各个 SYN 数据包的 IP 地址,以便阻止缓解措施并加大身份暴露难度。虽然数据包可能经过伪装,但还是可以通过这些数据包追根溯源。此类检测工作很难开展,但并非不可实现;特别是,如果 Internet 服务提供商 (ISP) 愿意提供帮助,则更容易实现。
+3. **分布式攻击(DDoS):** 如果使用僵尸网络发起攻击,则追溯攻击源头的可能性很低。随着混淆级别的攀升,攻击者可能还会命令每台分布式设备伪造其发送数据包的 IP 地址。哪怕攻击者使用僵尸网络(如 Mirai 僵尸网络),通常也不会刻意屏蔽受感染设备的 IP。
+
+### 如何缓解 SYN Flood?
+
+#### 扩展积压工作队列
+
+目标设备安装的每个操作系统都允许具有一定数量的半开连接。若要响应大量 SYN 数据包,一种方法是增加操作系统允许的最大半开连接数目。为成功扩展最大积压工作,系统必须额外预留内存资源以处理各类新请求。如果系统没有足够的内存,无法应对增加的积压工作队列规模,将对系统性能产生负面影响,但仍然好过拒绝服务。
+
+#### 回收最先创建的 TCP 半开连接
+
+另一种缓解策略是在填充积压工作后覆盖最先创建的半开连接。这项策略要求完全建立合法连接的时间低于恶意 SYN 数据包填充积压工作的时间。当攻击量增加或积压工作规模小于实际需求时,这项特定的防御措施将不奏效。
+
+#### SYN Cookie
+
+此策略要求服务器创建 Cookie。为避免在填充积压工作时断开连接,服务器使用 SYN-ACK 数据包响应每一项连接请求,而后从积压工作中删除 SYN 请求,同时从内存中删除请求,保证端口保持打开状态并做好重新建立连接的准备。如果连接是合法请求并且已将最后一个 ACK 数据包从客户端机器发回服务器,服务器将重建(存在一些限制)SYN 积压工作队列条目。虽然这项缓解措施势必会丢失一些 TCP 连接信息,但好过因此导致对合法用户发起拒绝服务攻击。
+
+## UDP Flood(洪水)
+
+### UDP Flood 是什么?
+
+**UDP Flood** 也是一种拒绝服务攻击,将大量的用户数据报协议(**UDP**)数据包发送到目标服务器,目的是压倒该设备的处理和响应能力。防火墙保护目标服务器也可能因 **UDP** 泛滥而耗尽,从而导致对合法流量的拒绝服务。
+
+### UDP Flood 攻击原理是什么?
+
+**UDP Flood** 主要通过利用服务器响应发送到其中一个端口的 **UDP** 数据包所采取的步骤。在正常情况下,当服务器在特定端口接收到 **UDP** 数据包时,会经过两个步骤:
+
+- 服务器首先检查是否正在运行正在侦听指定端口的请求的程序。
+- 如果没有程序在该端口接收数据包,则服务器使用 **ICMP**(ping)数据包进行响应,以通知发送方目的地不可达。
+
+举个例子。假设今天要联系酒店的小蓝,酒店客服接到电话后先查看房间的列表来确保小蓝在客房内,随后转接给小蓝。
+
+首先,接待员接收到呼叫者要求连接到特定房间的电话。接待员然后需要查看所有房间的清单,以确保客人在房间中可用,并愿意接听电话。碰巧的是,此时如果突然间所有的电话线同时亮起来,那么他们就会很快就变得不堪重负了。
+
+当服务器接收到每个新的 **UDP** 数据包时,它将通过步骤来处理请求,并利用该过程中的服务器资源。发送 **UDP** 报文时,每个报文将包含源设备的 **IP** 地址。在这种类型的 **DDoS** 攻击期间,攻击者通常不会使用自己的真实 **IP** 地址,而是会欺骗 **UDP** 数据包的源 **IP** 地址,从而阻止攻击者的真实位置被暴露并潜在地饱和来自目标的响应数据包服务器。
+
+由于目标服务器利用资源检查并响应每个接收到的 **UDP** 数据包的结果,当接收到大量 **UDP** 数据包时,目标的资源可能会迅速耗尽,导致对正常流量的拒绝服务。
+
+
+
+### 如何缓解 UDP Flood?
+
+大多数操作系统部分限制了 **ICMP** 报文的响应速率,以中断需要 ICMP 响应的 **DDoS** 攻击。这种缓解的一个缺点是在攻击过程中,合法的数据包也可能被过滤。如果 **UDP Flood** 的容量足够高以使目标服务器的防火墙的状态表饱和,则在服务器级别发生的任何缓解都将不足以应对目标设备上游的瓶颈。
+
+## HTTP Flood(洪水)
+
+### HTTP Flood 是什么?
+
+HTTP Flood 是一种大规模的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击,旨在利用 HTTP 请求使目标服务器不堪重负。目标因请求而达到饱和,且无法响应正常流量后,将出现拒绝服务,拒绝来自实际用户的其他请求。
+
+
+
+### HTTP Flood 的攻击原理是什么?
+
+HTTP 洪水攻击是“第 7 层”DDoS 攻击的一种。第 7 层是 OSI 模型的应用程序层,指的是 HTTP 等互联网协议。HTTP 是基于浏览器的互联网请求的基础,通常用于加载网页或通过互联网发送表单内容。缓解应用程序层攻击特别复杂,因为恶意流量和正常流量很难区分。
+
+为了获得最大效率,恶意行为者通常会利用或创建僵尸网络,以最大程度地扩大攻击的影响。通过利用感染了恶意软件的多台设备,攻击者可以发起大量攻击流量来进行攻击。
+
+HTTP 洪水攻击有两种:
+
+- **HTTP GET 攻击**:在这种攻击形式下,多台计算机或其他设备相互协调,向目标服务器发送对图像、文件或其他资产的多个请求。当目标被传入的请求和响应所淹没时,来自正常流量源的其他请求将被拒绝服务。
+- **HTTP POST 攻击**:一般而言,在网站上提交表单时,服务器必须处理传入的请求并将数据推送到持久层(通常是数据库)。与发送 POST 请求所需的处理能力和带宽相比,处理表单数据和运行必要数据库命令的过程相对密集。这种攻击利用相对资源消耗的差异,直接向目标服务器发送许多 POST 请求,直到目标服务器的容量饱和并拒绝服务为止。
+
+### 如何防护 HTTP Flood?
+
+如前所述,缓解第 7 层攻击非常复杂,而且通常要从多方面进行。一种方法是对发出请求的设备实施质询,以测试它是否是机器人,这与在线创建帐户时常用的 CAPTCHA 测试非常相似。通过提出 JavaScript 计算挑战之类的要求,可以缓解许多攻击。
+
+其他阻止 HTTP 洪水攻击的途径包括使用 Web 应用程序防火墙 (WAF)、管理 IP 信誉数据库以跟踪和有选择地阻止恶意流量,以及由工程师进行动态分析。Cloudflare 具有超过 2000 万个互联网设备的规模优势,能够分析来自各种来源的流量并通过快速更新的 WAF 规则和其他防护策略来缓解潜在的攻击,从而消除应用程序层 DDoS 流量。
+
+## DNS Flood(洪水)
+
+### DNS Flood 是什么?
+
+域名系统(DNS)服务器是互联网的“电话簿”;互联网设备通过这些服务器来查找特定 Web 服务器以便访问互联网内容。DNS Flood 攻击是一种分布式拒绝服务(DDoS)攻击,攻击者用大量流量淹没某个域的 DNS 服务器,以尝试中断该域的 DNS 解析。如果用户无法找到电话簿,就无法查找到用于调用特定资源的地址。通过中断 DNS 解析,DNS Flood 攻击将破坏网站、API 或 Web 应用程序响应合法流量的能力。很难将 DNS Flood 攻击与正常的大流量区分开来,因为这些大规模流量往往来自多个唯一地址,查询该域的真实记录,模仿合法流量。
+
+### DNS Flood 的攻击原理是什么?
+
+
+
+域名系统的功能是将易于记忆的名称(例如 example.com)转换成难以记住的网站服务器地址(例如 192.168.0.1),因此成功攻击 DNS 基础设施将导致大多数人无法使用互联网。DNS Flood 攻击是一种相对较新的基于 DNS 的攻击,这种攻击是在高带宽[物联网(IoT)](https://www.cloudflare.com/learning/ddos/glossary/internet-of-things-iot/)[僵尸网络](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-botnet/)(如 [Mirai](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/))兴起后激增的。DNS Flood 攻击使用 IP 摄像头、DVR 盒和其他 IoT 设备的高带宽连接直接淹没主要提供商的 DNS 服务器。来自 IoT 设备的大量请求淹没 DNS 提供商的服务,阻止合法用户访问提供商的 DNS 服务器。
+
+DNS Flood 攻击不同于 [DNS 放大攻击](https://www.cloudflare.com/zh-cn/learning/ddos/dns-amplification-ddos-attack/)。与 DNS Flood 攻击不同,DNS 放大攻击反射并放大不安全 DNS 服务器的流量,以便隐藏攻击的源头并提高攻击的有效性。DNS 放大攻击使用连接带宽较小的设备向不安全的 DNS 服务器发送无数请求。这些设备对非常大的 DNS 记录发出小型请求,但在发出请求时,攻击者伪造返回地址为目标受害者。这种放大效果让攻击者能借助有限的攻击资源来破坏较大的目标。
+
+### 如何防护 DNS Flood?
+
+DNS Flood 对传统上基于放大的攻击方法做出了改变。借助轻易获得的高带宽僵尸网络,攻击者现能针对大型组织发动攻击。除非被破坏的 IoT 设备得以更新或替换,否则抵御这些攻击的唯一方法是使用一个超大型、高度分布式的 DNS 系统,以便实时监测、吸收和阻止攻击流量。
+
+## TCP 重置攻击
+
+在 **TCP** 重置攻击中,攻击者通过向通信的一方或双方发送伪造的消息,告诉它们立即断开连接,从而使通信双方连接中断。正常情况下,如果客户端发现到达的报文段对于相关连接而言是不正确的,**TCP** 就会发送一个重置报文段,从而导致 **TCP** 连接的快速拆卸。
+
+**TCP** 重置攻击利用这一机制,通过向通信方发送伪造的重置报文段,欺骗通信双方提前关闭 TCP 连接。如果伪造的重置报文段完全逼真,接收者就会认为它有效,并关闭 **TCP** 连接,防止连接被用来进一步交换信息。服务端可以创建一个新的 **TCP** 连接来恢复通信,但仍然可能会被攻击者重置连接。万幸的是,攻击者需要一定的时间来组装和发送伪造的报文,所以一般情况下这种攻击只对长连接有杀伤力,对于短连接而言,你还没攻击呢,人家已经完成了信息交换。
+
+从某种意义上来说,伪造 **TCP** 报文段是很容易的,因为 **TCP/IP** 都没有任何内置的方法来验证服务端的身份。有些特殊的 IP 扩展协议(例如 `IPSec`)确实可以验证身份,但并没有被广泛使用。客户端只能接收报文段,并在可能的情况下使用更高级别的协议(如 `TLS`)来验证服务端的身份。但这个方法对 **TCP** 重置包并不适用,因为 **TCP** 重置包是 **TCP** 协议本身的一部分,无法使用更高级别的协议进行验证。
+
+## 模拟攻击
+
+> 以下实验是在 `OSX` 系统中完成的,其他系统请自行测试。
+
+现在来总结一下伪造一个 **TCP** 重置报文要做哪些事情:
+
+- 嗅探通信双方的交换信息。
+- 截获一个 `ACK` 标志位置位 1 的报文段,并读取其 `ACK` 号。
+- 伪造一个 TCP 重置报文段(`RST` 标志位置为 1),其序列号等于上面截获的报文的 `ACK` 号。这只是理想情况下的方案,假设信息交换的速度不是很快。大多数情况下为了增加成功率,可以连续发送序列号不同的重置报文。
+- 将伪造的重置报文发送给通信的一方或双方,使其中断连接。
+
+为了实验简单,我们可以使用本地计算机通过 `localhost` 与自己通信,然后对自己进行 TCP 重置攻击。需要以下几个步骤:
+
+- 在两个终端之间建立一个 TCP 连接。
+- 编写一个能嗅探通信双方数据的攻击程序。
+- 修改攻击程序,伪造并发送重置报文。
+
+下面正式开始实验。
+
+> 建立 TCP 连接
+
+可以使用 netcat 工具来建立 TCP 连接,这个工具很多操作系统都预装了。打开第一个终端窗口,运行以下命令:
+
+```bash
+nc -nvl 8000
+```
+
+这个命令会启动一个 TCP 服务,监听端口为 `8000`。接着再打开第二个终端窗口,运行以下命令:
+
+```bash
+nc 127.0.0.1 8000
+```
+
+该命令会尝试与上面的服务建立连接,在其中一个窗口输入一些字符,就会通过 TCP 连接发送给另一个窗口并打印出来。
+
+
+
+> 嗅探流量
+
+编写一个攻击程序,使用 Python 网络库 `scapy` 来读取两个终端窗口之间交换的数据,并将其打印到终端上。代码比较长,下面为一部份,完整代码后台回复 TCP 攻击,代码的核心是调用 `scapy` 的嗅探方法:
+
+
+
+这段代码告诉 `scapy` 在 `lo0` 网络接口上嗅探数据包,并记录所有 TCP 连接的详细信息。
+
+- **iface**:告诉 scapy 在 `lo0`(localhost)网络接口上进行监听。
+- **lfilter**:这是个过滤器,告诉 scapy 忽略所有不属于指定的 TCP 连接(通信双方皆为 `localhost`,且端口号为 `8000`)的数据包。
+- **prn**:scapy 通过这个函数来操作所有符合 `lfilter` 规则的数据包。上面的例子只是将数据包打印到终端,下文将会修改函数来伪造重置报文。
+- **count**:scapy 函数返回之前需要嗅探的数据包数量。
+
+> 发送伪造的重置报文
+
+下面开始修改程序,发送伪造的 TCP 重置报文来进行 TCP 重置攻击。根据上面的解读,只需要修改 prn 函数就行了,让其检查数据包,提取必要参数,并利用这些参数来伪造 TCP 重置报文并发送。
+
+例如,假设该程序截获了一个从(`src_ip`, `src_port`)发往 (`dst_ip`, `dst_port`)的报文段,该报文段的 ACK 标志位已置为 1,ACK 号为 `100,000`。攻击程序接下来要做的是:
+
+- 由于伪造的数据包是对截获的数据包的响应,所以伪造数据包的源 `IP/Port` 应该是截获数据包的目的 `IP/Port`,反之亦然。
+- 将伪造数据包的 `RST` 标志位置为 1,以表示这是一个重置报文。
+- 将伪造数据包的序列号设置为截获数据包的 ACK 号,因为这是发送方期望收到的下一个序列号。
+- 调用 `scapy` 的 `send` 方法,将伪造的数据包发送给截获数据包的发送方。
+
+对于我的程序而言,只需将这一行取消注释,并注释这一行的上面一行,就可以全面攻击了。按照步骤 1 的方法设置 TCP 连接,打开第三个窗口运行攻击程序,然后在 TCP 连接的其中一个终端输入一些字符串,你会发现 TCP 连接被中断了!
+
+> 进一步实验
+
+1. 可以继续使用攻击程序进行实验,将伪造数据包的序列号加减 1 看看会发生什么,是不是确实需要和截获数据包的 `ACK` 号完全相同。
+2. 打开 `Wireshark`,监听 lo0 网络接口,并使用过滤器 `ip.src == 127.0.0.1 && ip.dst == 127.0.0.1 && tcp.port == 8000` 来过滤无关数据。你可以看到 TCP 连接的所有细节。
+3. 在连接上更快速地发送数据流,使攻击更难执行。
+
+## 中间人攻击
+
+猪八戒要向小蓝表白,于是写了一封信给小蓝,结果第三者小黑拦截到了这封信,把这封信进行了篡改,于是乎在他们之间进行搞破坏行动。这个马文才就是中间人,实施的就是中间人攻击。好我们继续聊聊什么是中间人攻击。
+
+### 什么是中间人?
+
+中间人攻击英文名叫 Man-in-the-Middle Attack,简称「MITM 攻击」。指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制。我们画一张图:
+
+
+
+从这张图可以看到,中间人其实就是攻击者。通过这种原理,有很多实现的用途,比如说,你在手机上浏览不健康网站的时候,手机就会提示你,此网站可能含有病毒,是否继续访问还是做其他的操作等等。
+
+### 中间人攻击的原理是什么?
+
+举个例子,我和公司签了一个一份劳动合同,一人一份合同。不晓得哪个可能改了合同内容,不知道真假了,怎么搞?只好找专业的机构来鉴定,自然就要花钱。
+
+在安全领域有句话:**我们没有办法杜绝网络犯罪,只好想办法提高网络犯罪的成本**。既然没法杜绝这种情况,那我们就想办法提高作案的成本,今天我们就简单了解下基本的网络安全知识,也是面试中的高频面试题了。
+
+为了避免双方说话不算数的情况,双方引入第三家机构,将合同原文给可信任的第三方机构,只要这个机构不监守自盗,合同就相对安全。
+
+**如果第三方机构内部不严格或容易出现纰漏?**
+
+虽然我们将合同原文给第三方机构了,为了防止内部人员的更改,需要采取什么措施呢?
+
+一种可行的办法是引入 **摘要算法** 。即合同和摘要一起,为了简单的理解摘要。大家可以想象这个摘要为一个函数,这个函数对原文进行了加密,会产生一个唯一的散列值,一旦原文发生一点点变化,那么这个散列值将会变化。
+
+#### 有哪些常用的摘要算法呢?
+
+目前比较常用的加密算法有消息摘要算法和安全散列算法(**SHA**)。**MD5** 是将任意长度的文章转化为一个 128 位的散列值,可是在 2004 年,**MD5** 被证实了容易发生碰撞,即两篇原文产生相同的摘要。这样的话相当于直接给黑客一个后门,轻松伪造摘要。
+
+所以在大部分的情况下都会选择 **SHA 算法** 。
+
+**出现内鬼了怎么办?**
+
+看似很安全的场面了,理论上来说杜绝了篡改合同的做法。主要某个员工同时具有修改合同和摘要的权利,那搞事儿就是时间的问题了,毕竟没哪个系统可以完全的杜绝员工接触敏感信息,除非敏感信息都不存在。所以能不能考虑将合同和摘要分开存储呢?
+
+**那如何确保员工不会修改合同呢?**
+
+这确实蛮难的,不过办法总比困难多。我们将合同放在双方手中,摘要放在第三方机构,篡改难度进一步加大。
+
+**那么员工万一和某个用户串通好了呢?**
+
+看来放在第三方的机构还是不好使,同样存在不小风险。所以还需要寻找新的方案,这就出现了**数字签名和证书**。
+
+#### 数字证书和签名有什么用?
+
+同样的,举个例子。Sum 和 Mike 两个人签合同。Sum 首先用 **SHA** 算法计算合同的摘要,然后用自己私钥将摘要加密,得到数字签名。Sum 将合同原文、签名,以及公钥三者都交给 Mike
+
+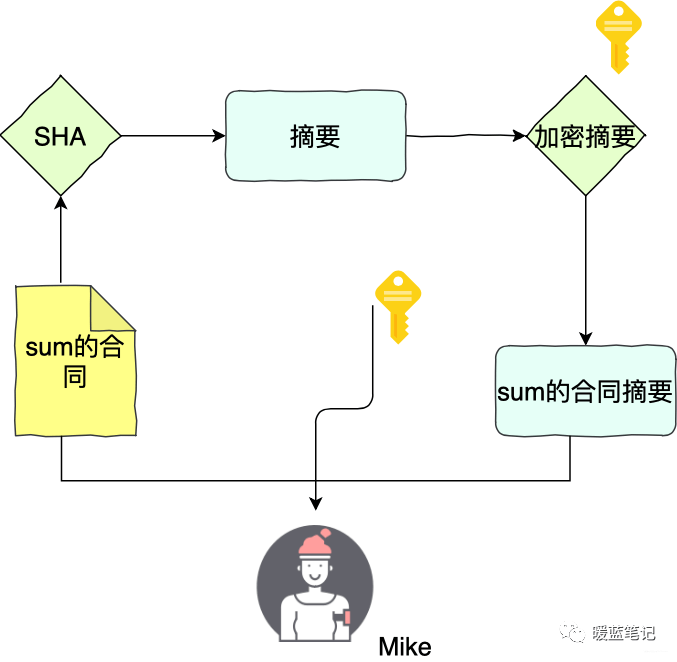
+
+如果 Sum 想要证明合同是 Mike 的,那么就要使用 Mike 的公钥,将这个签名解密得到摘要 x,然后 Mike 计算原文的 sha 摘要 Y,随后对比 x 和 y,如果两者相等,就认为数据没有被篡改
+
+在这样的过程中,Mike 是不能更改 Sum 的合同,因为要修改合同不仅仅要修改原文还要修改摘要,修改摘要需要提供 Mike 的私钥,私钥即 Sum 独有的密码,公钥即 Sum 公布给他人使用的密码
+
+总之,公钥加密的数据只能私钥可以解密。私钥加密的数据只有公钥可以解密,这就是 **非对称加密** 。
+
+隐私保护?不是吓唬大家,信息是透明的兄 die,不过尽量去维护个人的隐私吧,今天学习对称加密和非对称加密。
+
+大家先读读这个字“钥”,是读"yao",我以前也是,其实读"yue"
+
+#### 什么是对称加密?
+
+对称加密,顾名思义,加密方与解密方使用同一钥匙(秘钥)。具体一些就是,发送方通过使用相应的加密算法和秘钥,对将要发送的信息进行加密;对于接收方而言,使用解密算法和相同的秘钥解锁信息,从而有能力阅读信息。
+
+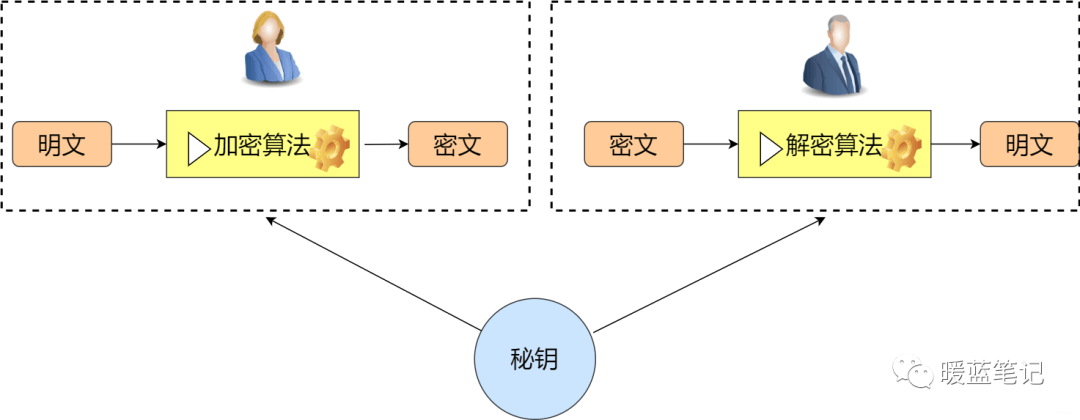
+
+#### 常见的对称加密算法有哪些?
+
+**DES**
+
+DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实际用于算法,其余 8 位可以被用于奇偶校验,并在算法中被丢弃。因此,**DES** 的有效密钥长度为 56 位,通常称 **DES** 的密钥长度为 56 位。假设秘钥为 56 位,采用暴力破 Jie 的方式,其秘钥个数为 2 的 56 次方,那么每纳秒执行一次解密所需要的时间差不多 1 年的样子。当然,没人这么干。**DES** 现在已经不是一种安全的加密方法,主要因为它使用的 56 位密钥过短。
+
+
+
+**IDEA**
+
+国际数据加密算法(International Data Encryption Algorithm)。秘钥长度 128 位,优点没有专利的限制。
+
+**AES**
+
+当 DES 被破解以后,没过多久推出了 **AES** 算法,提供了三种长度供选择,128 位、192 位和 256 位,为了保证性能不受太大的影响,选择 128 即可。
+
+**SM1 和 SM4**
+
+之前几种都是国外的,我们国内自行研究了国密 **SM1** 和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可。
+
+**总结**:
+
+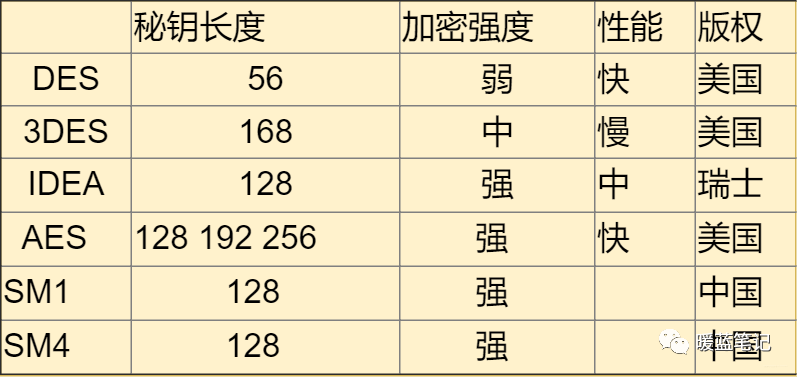
+
+#### 常见的非对称加密算法有哪些?
+
+在对称加密中,发送方与接收方使用相同的秘钥。那么在非对称加密中则是发送方与接收方使用的不同的秘钥。其主要解决的问题是防止在秘钥协商的过程中发生泄漏。比如在对称加密中,小蓝将需要发送的消息加密,然后告诉你密码是 123balala,ok,对于其他人而言,很容易就能劫持到密码是 123balala。那么在非对称的情况下,小蓝告诉所有人密码是 123balala,对于中间人而言,拿到也没用,因为没有私钥。所以,非对称密钥其实主要解决了密钥分发的难题。如下图
+
+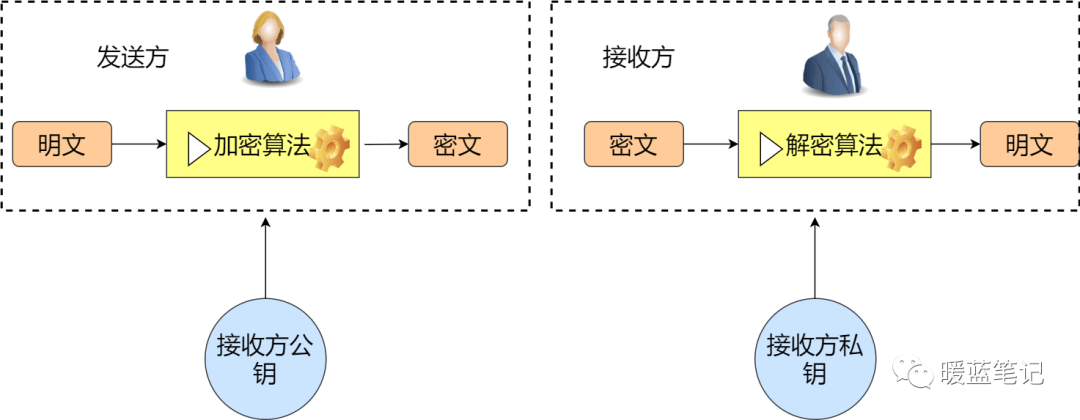
+
+其实我们经常都在使用非对称加密,比如使用多台服务器搭建大数据平台 Hadoop,为了方便多台机器设置免密登录,是不是就会涉及到秘钥分发。再比如搭建 Docker 集群也会使用相关非对称加密算法。
+
+常见的非对称加密算法:
+
+- RSA(RSA 加密算法,RSA Algorithm):安全性基于大整数分解的计算难度,应用广泛,兼容性好。缺点是性能相对较慢,且密钥越长(如 2048/4096 位)安全性越高,但运算开销也随之增大。
+- ECC:基于椭圆曲线提出,是目前加密强度最高的非对称加密算法。
+- SM2:同样基于椭圆曲线问题设计,最大优势就是国家认可和大力支持。
+
+总结:
+
+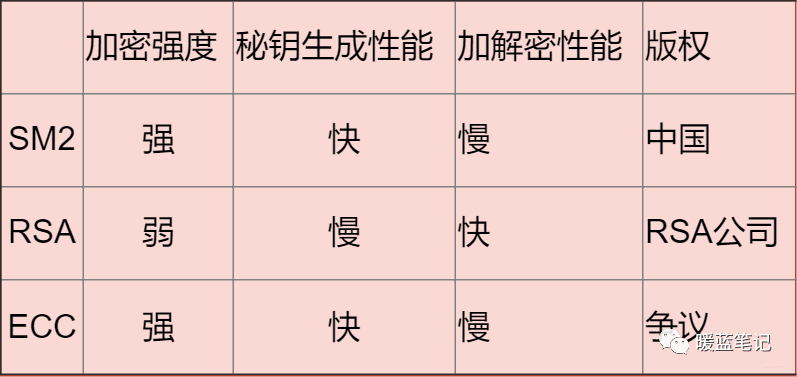
+
+#### 常见的散列算法有哪些?
+
+这个大家应该更加熟悉了,比如我们平常使用的 MD5 校验,在很多时候,我并不是拿来进行加密,而是用来获得唯一性 ID。在做系统的过程中,存储用户的各种密码信息,通常都会通过散列算法,最终存储其散列值。
+
+**MD5**(不推荐)
+
+MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较普遍的散列算法,具体的应用场景你可以自行 参阅。虽然,因为算法的缺陷,它的唯一性已经被破解了,但是大部分场景下,这并不会构成安全问题。但是,如果不是长度受限(32 个字符),我还是不推荐你继续使用 **MD5** 的。
+
+**SHA**
+
+安全散列算法。**SHA** 包括**SHA-1**、**SHA-2**和**SHA-3**三个版本。该算法的基本思想是:接收一段明文数据,通过不可逆的方式将其转换为固定长度的密文。简单来说,SHA 将输入数据(即预映射或消息)转化为固定长度、较短的输出值,称为散列值(或信息摘要、信息认证码)。SHA-1 已被证明不够安全,因此逐渐被 SHA-2 取代,而 SHA-3 则作为 SHA 系列的最新版本,采用不同的结构(Keccak 算法)提供更高的安全性和灵活性。
+
+**SM3**
+
+国密算法 **SM3**。加密强度和 SHA-256 算法相差不多。主要是受到了国家的支持。
+
+**总结**:
+
+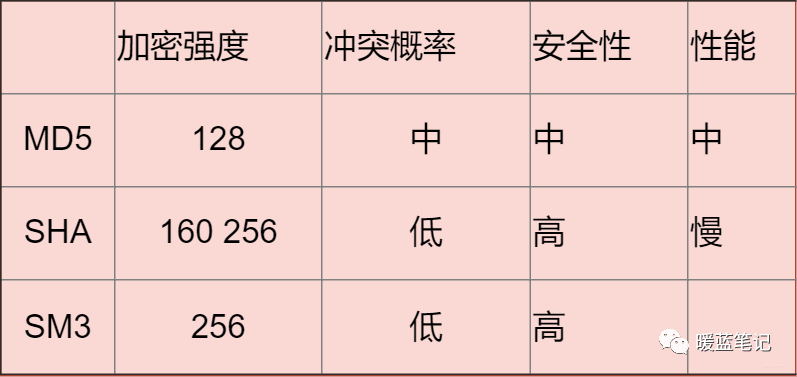
+
+**大部分情况下使用对称加密,具有比较不错的安全性。如果需要分布式进行秘钥分发,考虑非对称。如果不需要可逆计算则使用散列算法。**
+
+#### 第三方机构和证书机制有什么用?
+
+问题还有,此时如果 Sum 否认给过 Mike 的公钥和合同,不久就麻烦了。
+
+所以需要 Sum 过的话做过的事儿需要足够的信誉,这就引入了**第三方机构和证书机制**。
+
+证书之所以会有信用,是因为证书的签发方拥有信用。所以如果 Sum 想让 Mike 承认自己的公钥,Sum 不会直接将公钥给 Mike,而是提供由第三方机构签发的含有公钥的证书。如果 Mike 也信任这个机构,法律都认可,那信任关系成立。
+
+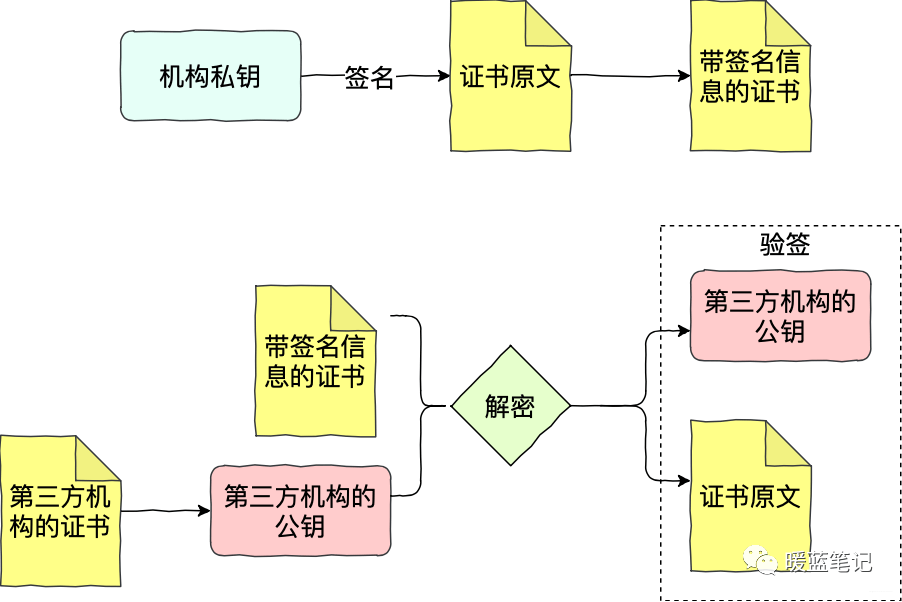
+
+如上图所示,Sum 将自己的申请提交给机构,产生证书的原文。机构用自己的私钥签名 Sum 的申请原文(先根据原文内容计算摘要,再用私钥加密),得到带有签名信息的证书。Mike 拿到带签名信息的证书,通过第三方机构的公钥进行解密,获得 Sum 证书的摘要、证书的原文。有了 Sum 证书的摘要和原文,Mike 就可以进行验签。验签通过,Mike 就可以确认 Sum 的证书的确是第三方机构签发的。
+
+用上面这样一个机制,合同的双方都无法否认合同。这个解决方案的核心在于需要第三方信用服务机构提供信用背书。这里产生了一个最基础的信任链,如果第三方机构的信任崩溃,比如被黑客攻破,那整条信任链条也就断裂了。
+
+为了让这个信任条更加稳固,就需要环环相扣,打造更长的信任链,避免单点信任风险。
+
+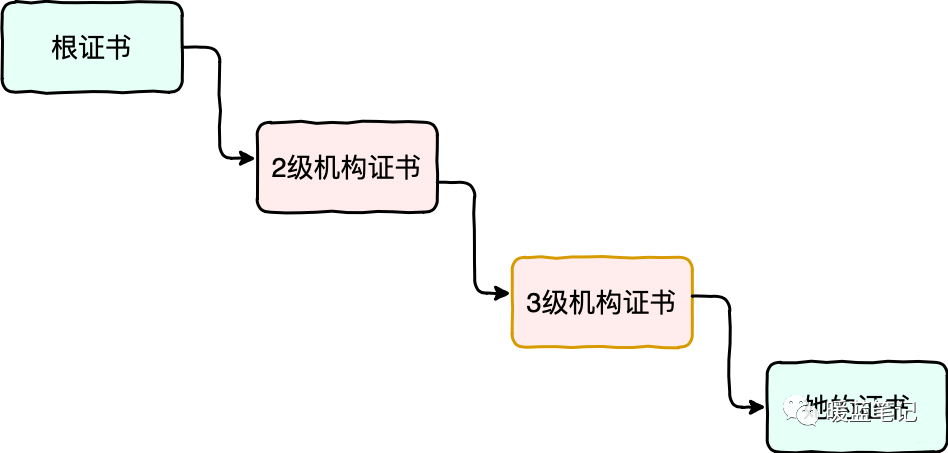
+
+上图中,由信誉最好的根证书机构提供根证书,然后根证书机构去签发二级机构的证书;二级机构去签发三级机构的证书;最后有由三级机构去签发 Sum 证书。
+
+如果要验证 Sum 证书的合法性,就需要用三级机构证书中的公钥去解密 Sum 证书的数字签名。
+
+如果要验证三级机构证书的合法性,就需要用二级机构的证书去解密三级机构证书的数字签名。
+
+如果要验证二级机构证书的合法性,就需要用根证书去解密。
+
+以上,就构成了一个相对长一些的信任链。如果其中一方想要作弊是非常困难的,除非链条中的所有机构同时联合起来,进行欺诈。
+
+### 中间人攻击如何避免?
+
+既然知道了中间人攻击的原理也知道了他的危险,现在我们看看如何避免。相信我们都遇到过下面这种状况:
+
+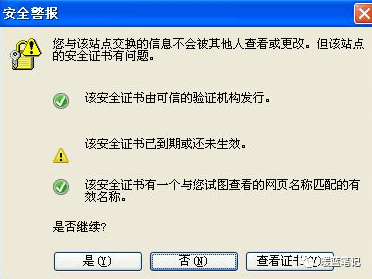
+
+出现这个界面的很多情况下,都是遇到了中间人攻击的现象,需要对安全证书进行及时地监测。而且大名鼎鼎的 github 网站,也曾遭遇过中间人攻击:
+
+想要避免中间人攻击的方法目前主要有两个:
+
+- 客户端不要轻易相信证书:因为这些证书极有可能是中间人。
+- App 可以提前预埋证书在本地:意思是我们本地提前有一些证书,这样其他证书就不能再起作用了。
+
+## DDoS
+
+通过上面的描述,前面好多种攻击都属于 DDoS 攻击,所以简单总结一下这个攻击的相关内容。
+
+其实,像全球互联网各大公司,均遭受过大量的 **DDoS**。
+
+2018 年,GitHub 在一瞬间遭到高达 1.35Tbps 的带宽攻击。这次 DDoS 攻击几乎可以堪称是互联网有史以来规模最大、威力最大的 DDoS 攻击了。在 GitHub 遭到攻击后,仅仅一周后,DDoS 攻击又开始对 Google、亚马逊甚至 Pornhub 等网站进行了 DDoS 攻击。后续的 DDoS 攻击带宽最高也达到了 1Tbps。
+
+### DDoS 攻击究竟是什么?
+
+DDos 全名 Distributed Denial of Service,翻译成中文就是**分布式拒绝服务**。指的是处于不同位置的多个攻击者同时向一个或数个目标发动攻击,是一种分布的、协同的大规模攻击方式。单一的 DoS 攻击一般是采用一对一方式的,它利用网络协议和操作系统的一些缺陷,采用**欺骗和伪装**的策略来进行网络攻击,使网站服务器充斥大量要求回复的信息,消耗网络带宽或系统资源,导致网络或系统不胜负荷以至于瘫痪而停止提供正常的网络服务。
+
+> 举个例子
+
+我开了一家有五十个座位的重庆火锅店,由于用料上等,童叟无欺。平时门庭若市,生意特别红火,而对面二狗家的火锅店却无人问津。二狗为了对付我,想了一个办法,叫了五十个人来我的火锅店坐着却不点菜,让别的客人无法吃饭。
+
+上面这个例子讲的就是典型的 DDoS 攻击,一般来说是指攻击者利用“肉鸡”对目标网站在较短的时间内发起大量请求,大规模消耗目标网站的主机资源,让它无法正常服务。在线游戏、互联网金融等领域是 DDoS 攻击的高发行业。
+
+攻击方式很多,比如 **ICMP Flood**、**UDP Flood**、**NTP Flood**、**SYN Flood**、**CC 攻击**、**DNS Query Flood**等等。
+
+### 如何应对 DDoS 攻击?
+
+#### 高防服务器
+
+还是拿开的重庆火锅店举例,高防服务器就是我给重庆火锅店增加了两名保安,这两名保安可以让保护店铺不受流氓骚扰,并且还会定期在店铺周围巡逻防止流氓骚扰。
+
+高防服务器主要是指能独立硬防御 50Gbps 以上的服务器,能够帮助网站拒绝服务攻击,定期扫描网络主节点等。
+
+#### 黑名单
+
+面对火锅店里面的流氓,我一怒之下将他们拍照入档,并禁止他们踏入店铺,但是有的时候遇到长得像的人也会禁止他进入店铺。这个就是设置黑名单,此方法秉承的就是“错杀一千,也不放一百”的原则,会封锁正常流量,影响到正常业务。
+
+#### DDoS 清洗
+
+**DDos** 清洗,就是我发现客人进店几分钟以后,但是一直不点餐,我就把他踢出店里。
+
+**DDoS** 清洗会对用户请求数据进行实时监控,及时发现 **DOS** 攻击等异常流量,在不影响正常业务开展的情况下清洗掉这些异常流量。
+
+#### CDN 加速
+
+CDN 加速,我们可以这么理解:为了减少流氓骚扰,我干脆将火锅店开到了线上,承接外卖服务,这样流氓找不到店在哪里,也耍不来流氓了。
+
+在现实中,CDN 服务将网站访问流量分配到了各个节点中,这样一方面隐藏网站的真实 IP,另一方面即使遭遇 **DDoS** 攻击,也可以将流量分散到各个节点中,防止源站崩溃。
+
+## 参考
+
+- HTTP 洪水攻击 - CloudFlare:
+- SYN 洪水攻击:
+- 什么是 IP 欺骗?:
+- 什么是 DNS 洪水?| DNS 洪水 DDoS 攻击:
+
+
diff --git a/docs/cs-basics/network/osi-and-tcp-ip-model.md b/docs/cs-basics/network/osi-and-tcp-ip-model.md
new file mode 100644
index 00000000000..1456e3b9575
--- /dev/null
+++ b/docs/cs-basics/network/osi-and-tcp-ip-model.md
@@ -0,0 +1,211 @@
+---
+title: OSI 七层模型与 TCP/IP 四层模型详解
+description: 详解 OSI 与 TCP/IP 的分层模型与职责划分,结合历史与实践对比两者差异与工程取舍。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: OSI 七层,TCP/IP 四层,分层模型,职责划分,协议栈,对比
+---
+
+网络分层是学习计算机网络的第一张地图。没有这张地图,HTTP、TCP、IP、以太网、DNS 这些概念很容易堆在一起,分不清谁依赖谁、谁负责什么。
+
+常见的两套分层模型是 OSI 七层模型和 TCP/IP 四层模型。前者更适合建立概念框架,后者更贴近互联网实际落地。
+
+这篇文章主要回答几个问题:
+
+1. OSI 七层模型每一层分别做什么?
+2. TCP/IP 四层模型和 OSI 七层模型如何对应?
+3. 为什么 OSI 模型理论完整,但实际没有成为互联网主流实现?
+4. 学习具体网络协议时,为什么要先知道它位于哪一层?
+
+## OSI 七层模型
+
+**OSI 七层模型** 是国际标准化组织提出一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
+
+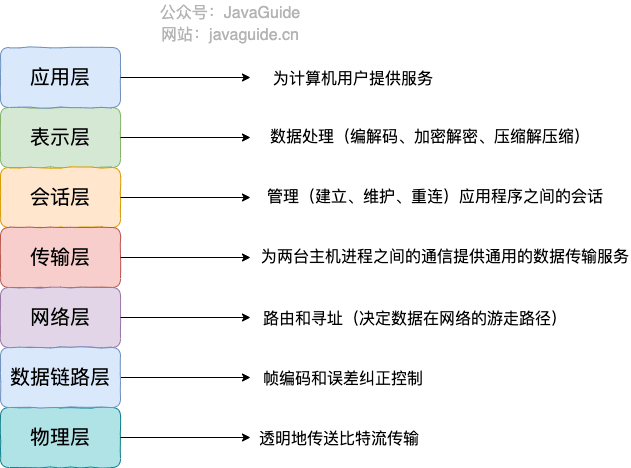
+
+每一层都专注做一件事情,并且每一层都需要使用下一层提供的功能比如传输层需要使用网络层提供的路由和寻址功能,这样传输层才知道把数据传输到哪里去。
+
+**OSI 的七层体系结构概念清楚,理论也很完整,但是它比较复杂而且不实用,而且有些功能在多个层中重复出现。**
+
+上面这种图可能比较抽象,再来一个比较生动的图片。下面这个图片是我在国外的一个网站上看到的,非常赞!
+
+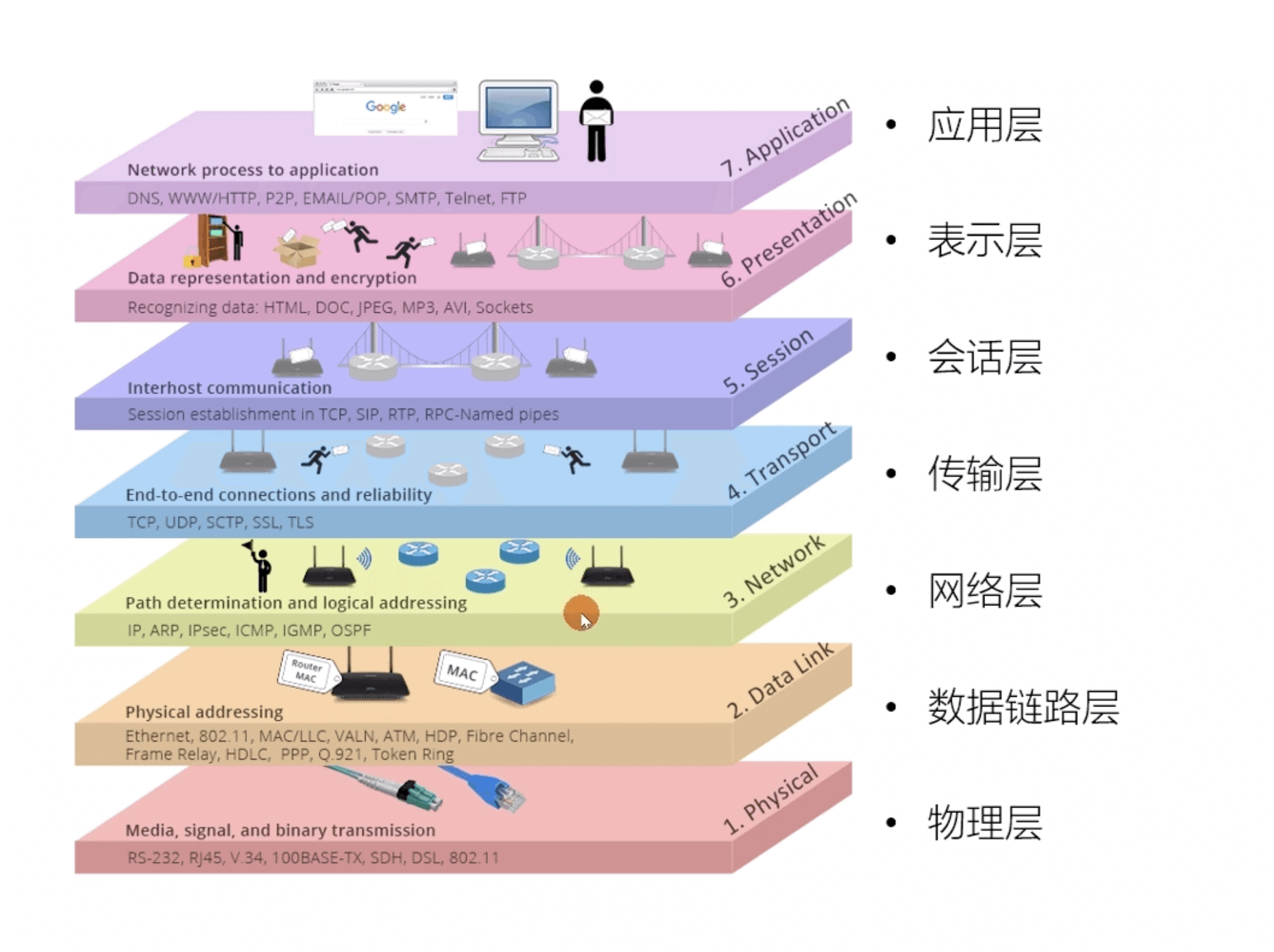
+
+**既然 OSI 七层模型这么厉害,为什么干不过 TCP/IP 四层模型呢?**
+
+的确,OSI 七层模型当时一直被一些大公司甚至一些国家政府支持。这样的背景下,为什么会失败呢?我觉得主要有下面几方面原因:
+
+1. OSI 的专家缺乏实际经验,他们在完成 OSI 标准时缺乏商业驱动力
+2. OSI 的协议实现起来过分复杂,而且运行效率很低
+3. OSI 制定标准的周期太长,因而使得按 OSI 标准生产的设备无法及时进入市场(20 世纪 90 年代初期,虽然整套的 OSI 国际标准都已经制定出来,但基于 TCP/IP 的互联网已经抢先在全球相当大的范围成功运行了)
+4. OSI 的层次划分不太合理,有些功能在多个层次中重复出现。
+
+OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础。为了更好地去了解网络分层,OSI 七层模型还是非常有必要学习的。
+
+最后再分享一个关于 OSI 七层模型非常不错的总结图片!
+
+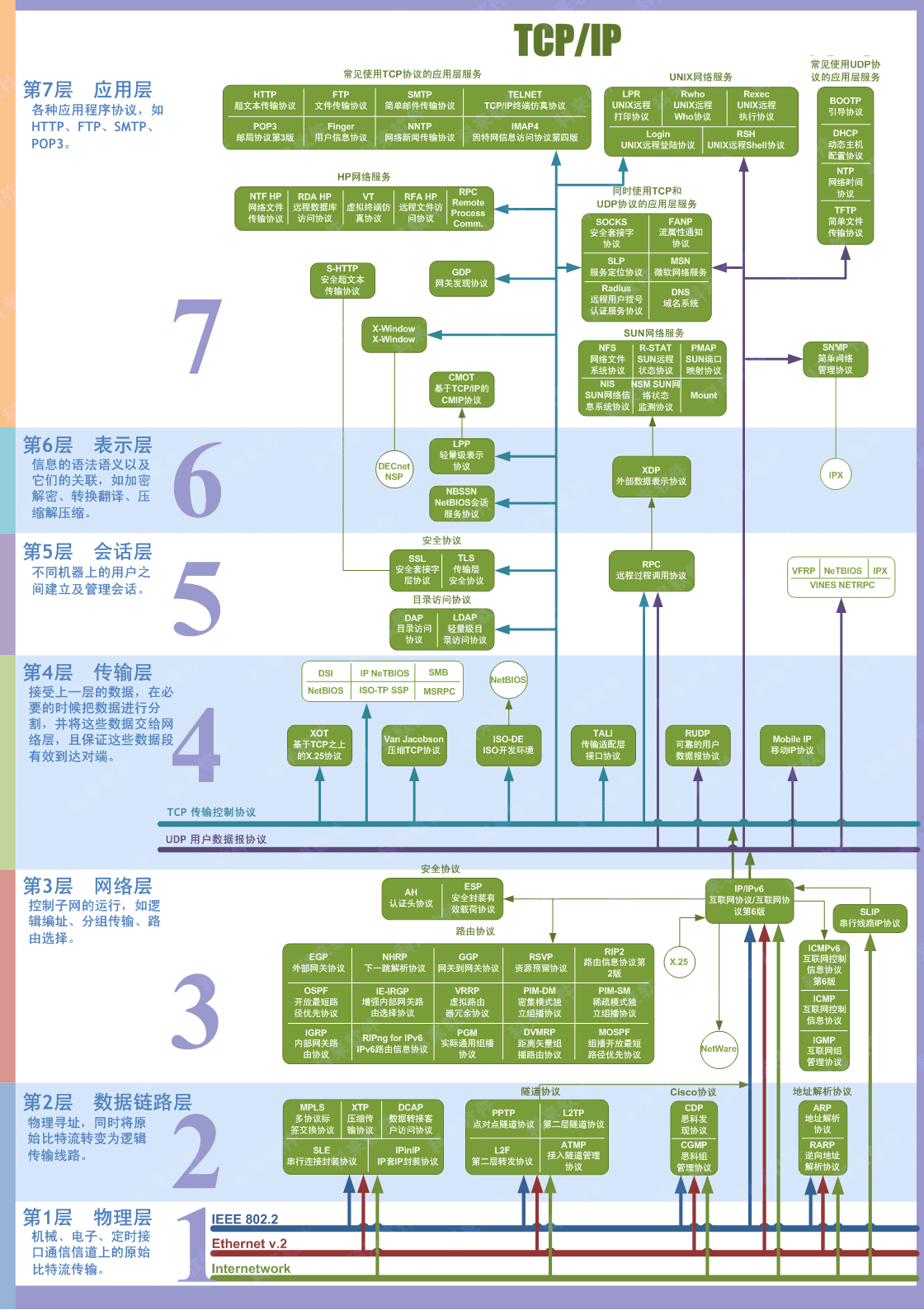
+
+## TCP/IP 四层模型
+
+**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP/IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
+
+1. 应用层
+2. 传输层
+3. 网络层
+4. 网络接口层
+
+需要注意的是,我们并不能将 TCP/IP 四层模型 和 OSI 七层模型完全精确地匹配起来,不过可以简单将两者对应起来,如下图所示:
+
+
+
+### 应用层(Application layer)
+
+**应用层位于传输层之上,主要提供两个终端设备上的应用程序之间信息交换的服务,它定义了信息交换的格式,消息会交给下一层传输层来传输。** 我们把应用层交互的数据单元称为报文。
+
+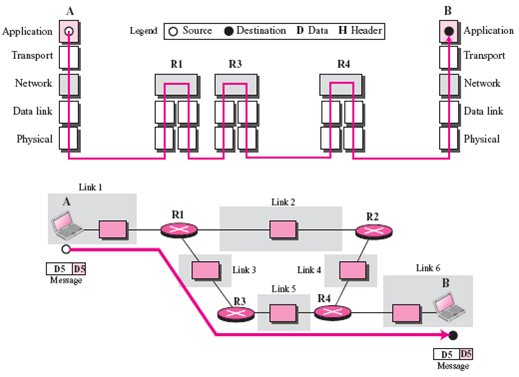
+
+应用层协议定义了网络通信规则,对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如支持 Web 应用的 HTTP 协议,支持电子邮件的 SMTP 协议等等。
+
+**应用层常见协议**:
+
+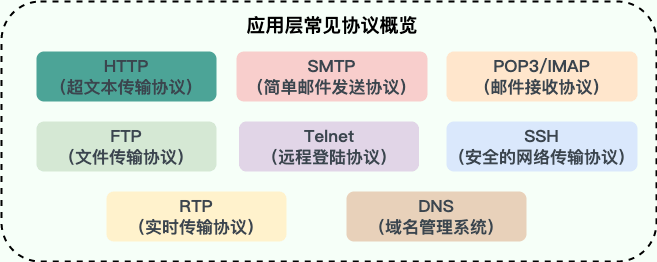
+
+- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
+- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
+- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
+- **FTP(File Transfer Protocol,文件传输协议)**:基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
+- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
+- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
+- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
+- **DNS(Domain Name System,域名管理系统)**:通常基于 UDP 协议(端口 53),用于解决域名和 IP 地址的映射问题。当响应数据过大或进行区域传送时会改用 TCP。
+
+关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](./application-layer-protocol.md) 这篇文章。
+
+### 传输层(Transport layer)
+
+**传输层的主要任务就是负责向两台终端设备进程之间的通信提供通用的数据传输服务。** 应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。
+
+**传输层常见协议**:
+
+
+
+- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
+- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
+
+### 网络层(Network layer)
+
+**网络层负责为分组交换网上的不同主机提供通信服务。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 IP 协议,因此分组也叫 IP 数据报,简称数据报。
+
+⚠️ 注意:**不要把运输层的“用户数据报 UDP”和网络层的“IP 数据报”弄混**。
+
+**网络层的还有一个任务就是选择合适的路由,使源主机运输层所传下来的分组,能通过网络层中的路由器找到目的主机。**
+
+这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称。
+
+互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Internet Protocol)和许多路由选择协议,因此互联网的网络层也叫做 **网际层** 或 **IP 层**。
+
+**网络层常见协议**:
+
+
+
+- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
+- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
+- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
+- **OSPF(Open Shortest Path First,开放式最短路径优先)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
+- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
+- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
+
+### 网络接口层(Network interface layer)
+
+我们可以把网络接口层看作是数据链路层和物理层的合体。
+
+1. 数据链路层(data link layer)通常简称为链路层( 两台主机之间的数据传输,总是在一段一段的链路上传送的)。**数据链路层的作用是将网络层交下来的 IP 数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。**
+2. **物理层的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异**
+
+网络接口层重要功能和协议如下图所示:
+
+
+
+### 总结
+
+简单总结一下每一层包含的协议和核心技术:
+
+
+
+**应用层协议**:
+
+- HTTP(Hypertext Transfer Protocol,超文本传输协议)
+- SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)
+- POP3/IMAP(邮件接收协议)
+- FTP(File Transfer Protocol,文件传输协议)
+- Telnet(远程登陆协议)
+- SSH(Secure Shell Protocol,安全的网络传输协议)
+- RTP(Real-time Transport Protocol,实时传输协议)
+- DNS(Domain Name System,域名管理系统)
+- ……
+
+**传输层协议**:
+
+- TCP 协议
+ - 报文段结构
+ - 可靠数据传输
+ - 流量控制
+ - 拥塞控制
+- UDP 协议
+ - 报文段结构
+ - RDT(可靠数据传输协议)
+
+**网络层协议**:
+
+- IP(Internet Protocol,网际协议)
+- ARP(Address Resolution Protocol,地址解析协议)
+- ICMP 协议(控制报文协议,用于发送控制消息)
+- NAT(Network Address Translation,网络地址转换协议)
+- OSPF(Open Shortest Path First,开放式最短路径优先)
+- RIP(Routing Information Protocol,路由信息协议)
+- BGP(Border Gateway Protocol,边界网关协议)
+- ……
+
+**网络接口层**:
+
+- 差错检测技术
+- 多路访问协议(信道复用技术)
+- CSMA/CD 协议
+- MAC 协议
+- 以太网技术
+- ……
+
+## 网络分层的原因
+
+在这篇文章的最后,我想聊聊:“为什么网络要分层?”。
+
+说到分层,我们先从我们平时使用框架开发一个后台程序来说,我们往往会按照每一层做不同的事情的原则将系统分为三层(复杂的系统分层会更多):
+
+1. Repository(数据库操作)
+2. Service(业务操作)
+3. Controller(前后端数据交互)
+
+**复杂的系统需要分层,因为每一层都需要专注于一类事情。网络分层的原因也是一样,每一层只专注于做一类事情。**
+
+好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
+
+1. **各层之间相互独立**:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)**。这个和我们对开发时系统进行分层是一个道理。**
+2. **提高了整体灵活性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
+3. **大问题化小**:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
+
+我想到了计算机世界非常非常有名的一句话,这里分享一下:
+
+> 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决,计算机整个体系从上到下都是按照严格的层次结构设计的。
+
+## 参考
+
+- TCP/IP model vs OSI model:
+- Data Encapsulation and the TCP/IP Protocol Stack:
+
+
diff --git a/docs/cs-basics/network/other-network-questions.md b/docs/cs-basics/network/other-network-questions.md
new file mode 100644
index 00000000000..c90757b5dc8
--- /dev/null
+++ b/docs/cs-basics/network/other-network-questions.md
@@ -0,0 +1,548 @@
+---
+title: 计算机网络常见面试题总结(上)
+description: 最新计算机网络高频面试题总结(上):TCP/IP四层模型、HTTP全版本对比、TCP三次握手、DNS解析、WebSocket/SSE实时推送等,附图解+⭐️重点标注,一文搞定应用层&传输层&网络层核心考点,快速备战后端面试!
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP/IP四层模型,HTTP面试,HTTPS vs HTTP,HTTP/1.1 vs HTTP/2,HTTP/3 QUIC,TCP三次握手,UDP区别,DNS解析,WebSocket vs SSE,GET vs POST,应用层协议,网络分层,队头阻塞,PING命令,ARP协议
+---
+
+
+
+
+
+计算机网络是后端面试和校招面试中绕不开的高频考点,尤其是 **TCP/IP 网络分层、HTTP、HTTPS、DNS、WebSocket、TCP 三次握手** 这些问题,几乎贯穿了“从输入 URL 到页面展示”“接口为什么变慢”“连接为什么失败”等真实开发场景。
+
+这篇《计算机网络常见面试题总结(上)》会先从网络分层模型讲起,再梳理应用层和 HTTP 相关的核心知识点,适合用来系统复习计算机网络基础,也适合作为 Java 后端、后端开发、计算机基础面试前的速查清单。
+
+## 计算机网络基础
+
+### 网络分层模型
+
+#### OSI 七层模型是什么?每一层的作用是什么?
+
+**OSI 七层模型** 是国际标准化组织提出的一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
+
+
+
+每一层都专注做一件事情,并且每一层都需要使用下一层提供的功能比如传输层需要使用网络层提供的路由和寻址功能,这样传输层才知道把数据传输到哪里去。
+
+**OSI 的七层体系结构概念清楚,理论也很完整,但是它比较复杂而且不实用,而且有些功能在多个层中重复出现。**
+
+上面这种图可能比较抽象,再来一个比较生动的图片。下面这个图片是我在国外的一个网站上看到的,非常赞!
+
+
+
+#### ⭐️TCP/IP 四层模型是什么?每一层的作用是什么?
+
+**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP/IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
+
+1. 应用层
+2. 传输层
+3. 网络层
+4. 网络接口层
+
+需要注意的是,我们并不能将 TCP/IP 四层模型 和 OSI 七层模型完全精确地匹配起来,不过可以简单将两者对应起来,如下图所示:
+
+
+
+关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](https://javaguide.cn/cs-basics/network/osi-and-tcp-ip-model.html) 这篇文章。
+
+#### 为什么网络要分层?
+
+说到分层,我们先从我们平时使用框架开发一个后台程序来说,我们往往会按照每一层做不同的事情的原则将系统分为三层(复杂的系统分层会更多):
+
+1. Repository(数据库操作)
+2. Service(业务操作)
+3. Controller(前后端数据交互)
+
+**复杂的系统需要分层,因为每一层都需要专注于一类事情。网络分层的原因也是一样,每一层只专注于做一类事情。**
+
+好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
+
+1. **各层之间相互独立**:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)**。这个和我们对开发时系统进行分层是一个道理。**
+2. **提高了灵活性和可替换性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。并且,每一层都可以根据需要进行修改或替换,而不会影响到整个网络的结构。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
+3. **大问题化小**:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
+
+我想到了计算机世界非常非常有名的一句话,这里分享一下:
+
+> 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决,计算机整个体系从上到下都是按照严格的层次结构设计的。
+
+### 常见网络协议
+
+#### ⭐️应用层有哪些常见的协议?
+
+
+
+- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
+- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
+- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
+- **FTP(File Transfer Protocol,文件传输协议)**:基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
+- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
+- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
+- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
+- **DNS(Domain Name System,域名管理系统)**:通常基于 UDP 协议(端口 53),用于解决域名和 IP 地址的映射问题。当响应数据过大或进行区域传送时会改用 TCP。
+
+关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](./application-layer-protocol.md) 这篇文章。
+
+#### 传输层有哪些常见的协议?
+
+
+
+- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
+- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
+
+#### 网络层有哪些常见的协议?
+
+
+
+- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
+- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
+- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
+- **OSPF(Open Shortest Path First,开放式最短路径优先)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
+- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
+- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
+
+## HTTP
+
+### ⭐️从输入 URL 到页面展示到底发生了什么?(非常重要)
+
+> 类似的问题:打开一个网页,整个过程会使用哪些协议?
+
+先来看一张图(来源于《图解 HTTP》):
+
+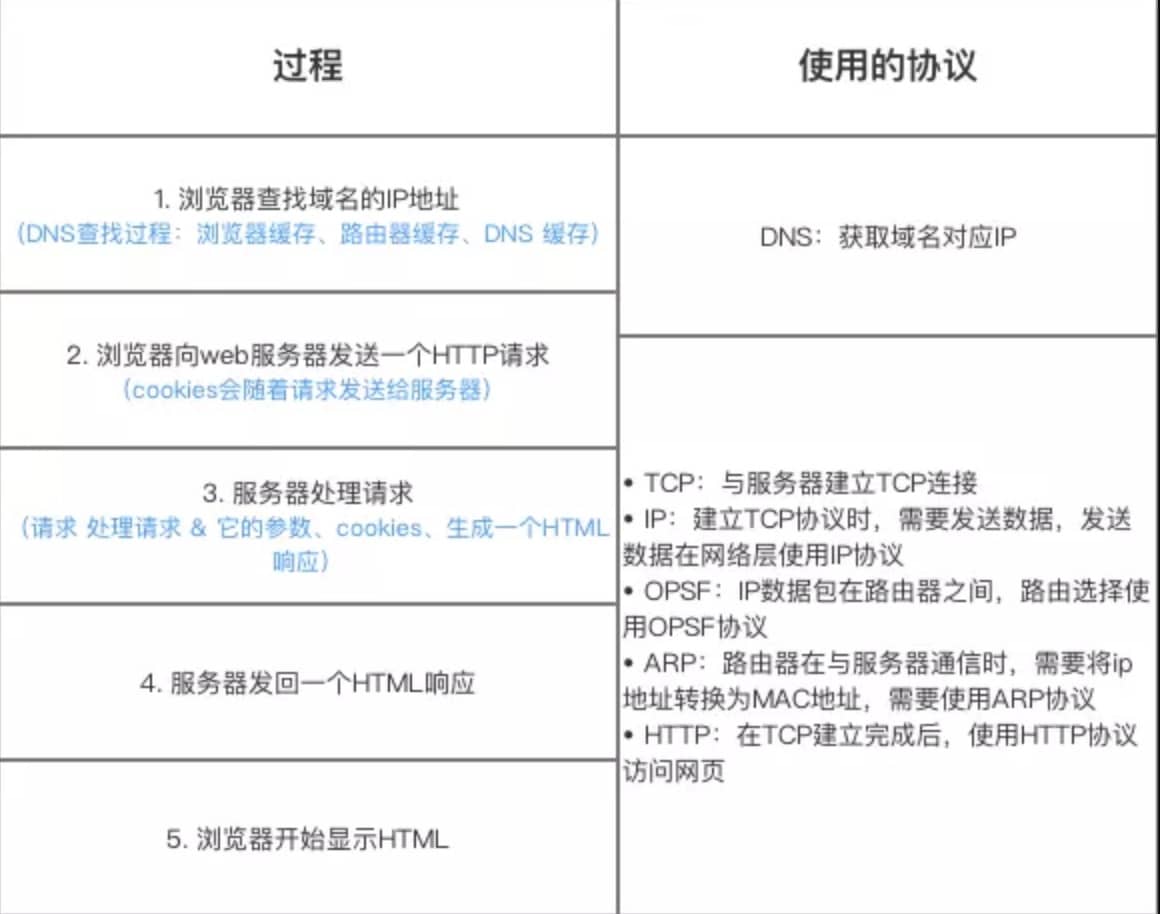 +
+上图有一个错误需要注意:是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
+
+总体来说分为以下几个步骤:
+
+1. 在浏览器中输入指定网页的 URL。
+2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
+3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
+4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
+5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
+6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
+7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
+
+详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](https://javaguide.cn/cs-basics/network/the-whole-process-of-accessing-web-pages.html)(强烈推荐)。
+
+### ⭐️HTTP 状态码有哪些?
+
+HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
+
+
+
+关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)。
+
+### HTTP Header 中常见的字段有哪些?
+
+| 请求头字段名 | 说明 | 示例 |
+| :------------------ | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------- |
+| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
+| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
+| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
+| Accept-Encoding | 能够接受的编码方式列表。参考 HTTP 压缩。 | Accept-Encoding: gzip, deflate |
+| Accept-Language | 能够接受的回应内容的自然语言列表。 | Accept-Language: en-US |
+| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令 | Cache-Control: no-cache |
+| Connection | 该浏览器想要优先使用的连接类型 | Connection: keep-alive |
+| Content-Length | 以八位字节数组(8 位的字节)表示的请求体的长度 | Content-Length: 348 |
+| Content-MD5 | 请求体的内容的二进制 MD5 散列值,以 Base64 编码的结果 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
+| Content-Type | 请求体的多媒体类型(用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded |
+| Cookie | 之前由服务器通过 Set-Cookie(下文详述)发送的一个超文本传输协议 Cookie | Cookie: $Version=1; Skin=new; |
+| Date | 发送该消息的日期和时间(按照 RFC 7231 中定义的“超文本传输协议日期”格式来发送) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
+| Expect | 表明客户端要求服务器做出特定的行为 | Expect: 100-continue |
+| From | 发起此请求的用户的邮件地址 | From: `user@example.com` |
+| Host | 服务器的域名(用于虚拟主机),以及服务器所监听的传输控制协议端口号。如果所请求的端口是对应的服务的标准端口,则端口号可被省略。 | Host: en.wikipedia.org |
+| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要作用是用于像 PUT 这样的方法中,仅当从用户上次更新某个资源以来,该资源未被修改的情况下,才更新该资源。 | If-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Modified-Since | 允许服务器在请求的资源自指定的日期以来未被修改的情况下返回 `304 Not Modified` 状态码 | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| If-None-Match | 允许服务器在请求的资源的 ETag 未发生变化的情况下返回 `304 Not Modified` 状态码 | If-None-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Range | 如果该实体未被修改过,则向我发送我所缺少的那一个或多个部分;否则,发送整个新的实体 | If-Range: "737060cd8c284d8af7ad3082f209582d" |
+| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
+| Origin | 发起一个针对跨来源资源共享的请求。 | `Origin: http://www.example-social-network.com` |
+| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生多种效果。 | Pragma: no-cache |
+| Proxy-Authorization | 用来向代理进行认证的认证信息。 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Range | 仅请求某个实体的一部分。字节偏移以 0 开始。参见字节服务。 | Range: bytes=500-999 |
+| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面。 | `Referer: http://en.wikipedia.org/wiki/Main_Page` |
+| TE | 浏览器预期接受的传输编码方式:可使用回应协议头 Transfer-Encoding 字段中的值; | TE: trailers, deflate |
+| Upgrade | 要求服务器升级到另一个协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
+| User-Agent | 浏览器的浏览器身份标识字符串 | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
+| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
+| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
+
+### ⭐️HTTP 和 HTTPS 有什么区别?(重要)
+
+
+
+- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
+- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
+- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
+- **SEO(搜索引擎优化)**:搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
+
+关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html) 。
+
+### HTTP/1.0 和 HTTP/1.1 有什么区别?
+
+
+
+- **连接方式**:HTTP/1.0 为短连接,HTTP/1.1 支持长连接。HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
+- **状态响应码**:HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
+- **缓存机制**:在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
+- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+- **Host 头(Host Header)处理**:HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
+
+关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html) 。
+
+### ⭐️HTTP/1.1 和 HTTP/2.0 有什么区别?
+
+
+
+- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
+- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
+- **队头阻塞**:HTTP/2 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 HTTP/1.1 应用层的队头阻塞问题,但 HTTP/2 依然受到 TCP 层队头阻塞 的影响。
+- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,使用了专门为`Header`压缩而设计的 HPACK 算法,减少了网络开销。
+- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
+
+HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://blog.cloudflare.com/http-2-for-web-developers/)):
+
+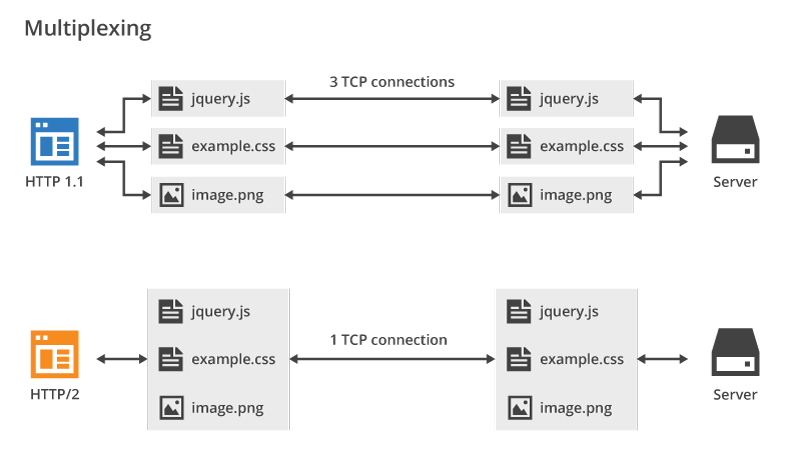
+
+可以看到,HTTP/2 的多路复用机制允许多个请求和响应共享一个 TCP 连接,从而避免了 HTTP/1.1 在应对并发请求时需要建立多个并行连接的情况,减少了重复连接建立和维护的额外开销。而在 HTTP/1.1 中,尽管支持持久连接,但为了缓解队头阻塞问题,浏览器通常会为同一域名建立多个并行连接。
+
+### HTTP/2.0 和 HTTP/3.0 有什么区别?
+
+
+
+- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
+- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
+- **头部压缩**:HTTP/2.0 使用 HPACK 算法进行头部压缩,而 HTTP/3.0 使用更高效的 QPACK 头压缩算法。
+- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
+- **连接迁移**:HTTP/3.0 支持连接迁移,因为 QUIC 使用 64 位 ID 标识连接,只要 ID 不变就不会中断,网络环境改变时(如从 Wi-Fi 切换到移动数据)也能保持连接。而 TCP 连接是由(源 IP,源端口,目的 IP,目的端口)组成,这个四元组中一旦有一项值发生改变,这个连接也就不能用了。
+- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
+- **安全性**:在 HTTP/2.0 中,TLS 用于加密和认证整个 HTTP 会话,包括所有的 HTTP 头部和数据负载。TLS 的工作是在 TCP 层之上,它加密的是在 TCP 连接中传输的应用层的数据,并不会对 TCP 头部以及 TLS 记录层头部进行加密,所以在传输的过程中 TCP 头部可能会被攻击者篡改来干扰通信。而 HTTP/3.0 的 QUIC 对整个数据包(包括报文头和报文体)进行了加密与认证处理,保障安全性。
+
+HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
+
+
+
+下图是一个更详细的 HTTP/2.0 和 HTTP/3.0 对比图:
+
+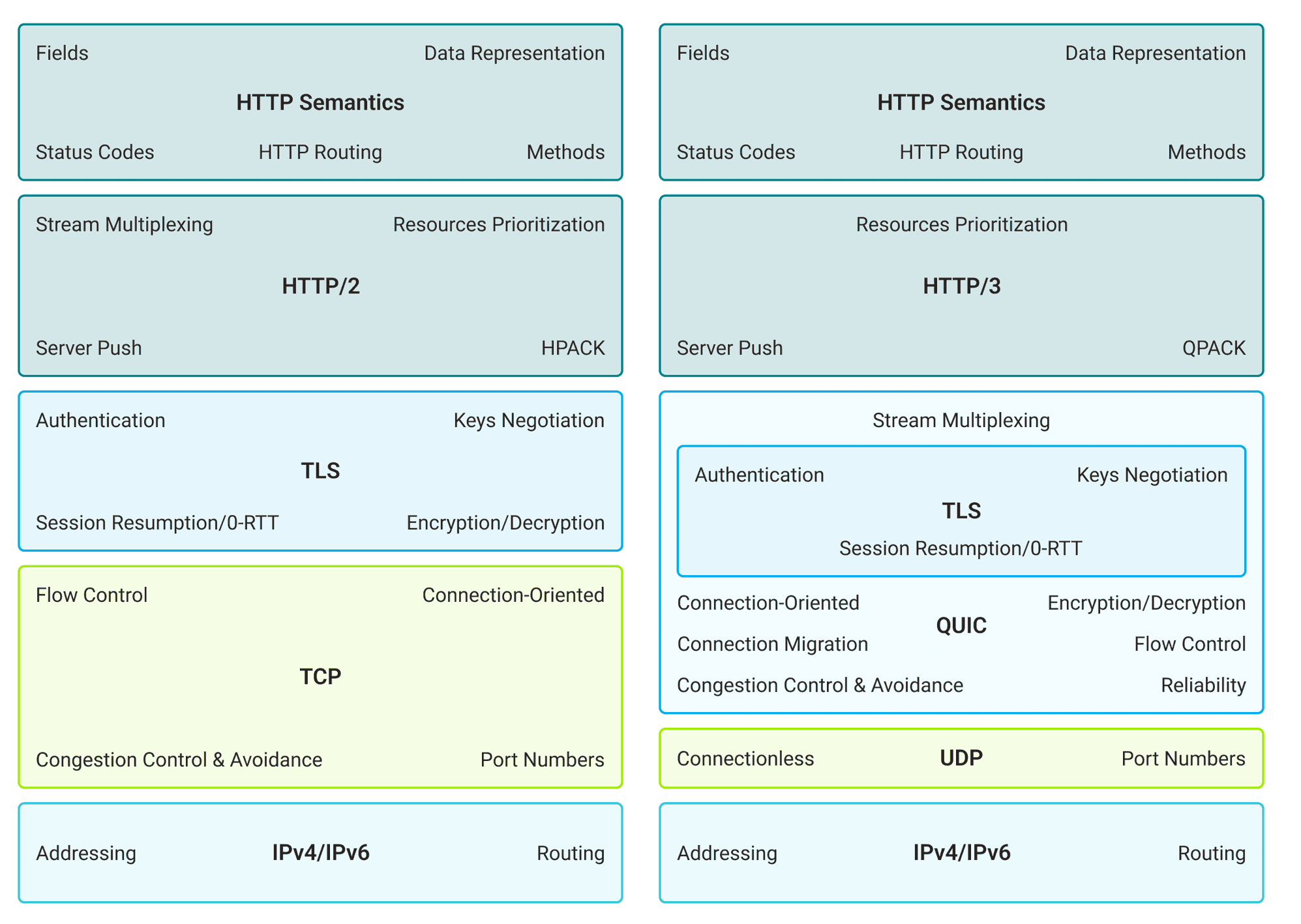
+
+从上图可以看出:
+
+- **HTTP/2.0**:使用 TCP 作为传输协议、使用 HPACK 进行头部压缩、依赖 TLS 进行加密。
+- **HTTP/3.0**:使用基于 UDP 的 QUIC 协议、使用更高效的 QPACK 进行头部压缩、在 QUIC 中直接集成了 TLS。QUIC 协议具备连接迁移、拥塞控制与避免、流量控制等特性。
+
+关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
+
+### HTTP/1.1 和 HTTP/2.0 的队头阻塞有什么不同?
+
+HTTP/1.1 队头阻塞的主要原因是无法多路复用:
+
+- 在一个 TCP 连接中,资源的请求和响应是按顺序处理的。如果一个大的资源(如一个大文件)正在传输,后续的小资源(如较小的 CSS 文件)需要等待前面的资源传输完成后才能被发送。
+- 如果浏览器需要同时加载多个资源(如多个 CSS、JS 文件等),它通常会开启多个并行的 TCP 连接(一般限制为 6 个)。但每个连接仍然受限于顺序的请求-响应机制,因此仍然会发生 **应用层的队头阻塞**。
+
+虽然 HTTP/2.0 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 **HTTP/1.1 应用层的队头阻塞问题**,但 HTTP/2.0 依然受到 **TCP 层队头阻塞** 的影响:
+
+- HTTP/2.0 通过帧(frame)机制将每个资源分割成小块,并为每个资源分配唯一的流 ID,这样多个资源的数据可以在同一 TCP 连接中交错传输。
+- TCP 作为传输层协议,要求数据按顺序交付。如果某个数据包在传输过程中丢失,即使后续的数据包已经到达,也必须等待丢失的数据包重传后才能继续处理。这种传输层的顺序性导致了 **TCP 层的队头阻塞**。
+- 举例来说,如果 HTTP/2 的一个 TCP 数据包中携带了多个资源的数据(例如 JS 和 CSS),而该数据包丢失了,那么后续数据包中的所有资源数据都需要等待丢失的数据包重传回来,导致所有流(streams)都被阻塞。
+
+最后,来一张表格总结补充一下:
+
+| **方面** | **HTTP/1.1 的队头阻塞** | **HTTP/2.0 的队头阻塞** |
+| -------------- | ---------------------------------------- | ---------------------------------------------------------------- |
+| **层级** | 应用层(HTTP 协议本身的限制) | 传输层(TCP 协议的限制) |
+| **根本原因** | 无法多路复用,请求和响应必须按顺序传输 | TCP 要求数据包按顺序交付,丢包时阻塞整个连接 |
+| **受影响范围** | 单个 HTTP 请求/响应会阻塞后续请求/响应。 | 单个 TCP 包丢失会影响所有 HTTP/2.0 流(依赖于同一个底层 TCP 连接) |
+| **缓解方法** | 开启多个并行的 TCP 连接 | 减少网络掉包或者使用基于 UDP 的 QUIC 协议 |
+| **影响场景** | 每次都会发生,尤其是大文件阻塞小文件时。 | 丢包率较高的网络环境下更容易发生。 |
+
+### ⭐️HTTP 是不保存状态的协议, 如何保存用户状态?
+
+HTTP 协议本身是 **无状态的 (stateless)** 。这意味着服务器默认情况下无法区分两个连续的请求是否来自同一个用户,或者同一个用户之前的操作是什么。这就像一个“健忘”的服务员,每次你跟他说话,他都不知道你是谁,也不知道你之前点过什么菜。
+
+但在实际的 Web 应用中,比如网上购物、用户登录等场景,我们显然需要记住用户的状态(例如购物车里的商品、用户的登录信息)。为了解决这个问题,主要有以下几种常用机制:
+
+**方案一:Session (会话) 配合 Cookie (主流方式):**
+
+
+
+这可以说是最经典也是最常用的方法了。基本流程是这样的:
+
+1. 用户向服务器发送用户名、密码、验证码用于登陆系统。
+2. 服务器验证通过后,会为这个用户创建一个专属的 Session 对象(可以理解为服务器上的一块内存,存放该用户的状态数据,如购物车、登录信息等)存储起来,并给这个 Session 分配一个唯一的 `SessionID`。
+3. 服务器通过 HTTP 响应头中的 `Set-Cookie` 指令,把这个 `SessionID` 发送给用户的浏览器。
+4. 浏览器接收到 `SessionID` 后,会将其以 Cookie 的形式保存在本地。当用户保持登录状态时,每次向该服务器发请求,浏览器都会自动带上这个存有 `SessionID` 的 Cookie。
+5. 服务器收到请求后,从 Cookie 中拿出 `SessionID`,就能找到之前保存的那个 Session 对象,从而知道这是哪个用户以及他之前的状态了。
+
+使用 Session 的时候需要注意下面几个点:
+
+- **客户端 Cookie 支持**:依赖 Session 的核心功能要确保用户浏览器开启了 Cookie。
+- **Session 过期管理**:合理设置 Session 的过期时间,平衡安全性和用户体验。
+- **Session ID 安全**:为包含 `SessionID` 的 Cookie 设置 `HttpOnly` 标志可以防止客户端脚本(如 JavaScript)窃取,设置 Secure 标志可以保证 `SessionID` 只在 HTTPS 连接下传输,增加安全性。
+
+Session 数据本身存储在服务器端。常见的存储方式有:
+
+- **服务器内存**:实现简单,访问速度快,但服务器重启数据会丢失,且不利于多服务器间的负载均衡。这种方式适合简单且用户量不大的业务场景。
+- **数据库 (如 MySQL, PostgreSQL)**:数据持久化,但读写性能相对较低,一般不会使用这种方式。
+- **分布式缓存 (如 Redis)**:性能高,支持分布式部署,是目前大规模应用中非常主流的方案。
+
+**方案二:当 Cookie 被禁用时:URL 重写 (URL Rewriting)**
+
+如果用户的浏览器禁用了 Cookie,或者某些情况下不便使用 Cookie,还有一种备选方案是 URL 重写。这种方式会将 `SessionID` 直接附加到 URL 的末尾,作为参数传递。例如:。服务器端会解析 URL 中的 `sessionid` 参数来获取 `SessionID`,进而找到对应的 Session 数据。
+
+这种方法一般不会使用,存在以下缺点:
+
+- URL 会变长且不美观;
+- `SessionID` 暴露在 URL 中,安全性较低(容易被复制、分享或记录在日志中);
+- 对搜索引擎优化 (SEO) 可能不友好。
+
+**方案三:Token-based 认证 (如 JWT - JSON Web Tokens)**
+
+这是一种越来越流行的无状态认证方式,尤其适用于前后端分离的架构和微服务。
+
+
+
+以 JWT 为例(普通 Token 方案也可以),简化后的步骤如下:
+
+1. 用户向服务器发送用户名、密码以及验证码用于登陆系统。
+2. 如果用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT。
+3. 客户端收到 Token 后自己保存起来(比如浏览器的 `localStorage`)。
+4. 用户以后每次向后端发请求都在 Header 中带上这个 JWT。
+5. 服务端检查 JWT 并从中获取用户相关信息。
+
+JWT 详细介绍可以查看这两篇文章:
+
+- [JWT 基础概念详解](https://javaguide.cn/system-design/security/jwt-intro.html)
+- [JWT 身份认证优缺点分析](https://javaguide.cn/system-design/security/advantages-and-disadvantages-of-jwt.html)
+
+总结来说,虽然 HTTP 本身是无状态的,但通过 Cookie + Session、URL 重写或 Token 等机制,我们能够有效地在 Web 应用中跟踪和管理用户状态。其中,**Cookie + Session 是最传统也最广泛使用的方式,而 Token-based 认证则在现代 Web 应用中越来越受欢迎。**
+
+### URI 和 URL 的区别是什么?
+
+- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
+- URL(Uniform Resource Locator) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
+
+URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL 是一种具体的 URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
+
+### Cookie 和 Session 有什么区别?
+
+准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](https://javaguide.cn/system-design/security/basis-of-authority-certification.html) 这篇文章中找到详细的答案。
+
+### ⭐️GET 和 POST 的区别
+
+这个问题在知乎上被讨论的挺火热的,地址: 。
+
+GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分二者(重点搞清两者在语义上的区别即可):
+
+- 语义(主要区别):GET 通常用于获取或查询资源,而 POST 通常用于创建或修改资源。
+- 幂等:GET 请求是幂等的,即多次重复执行不会改变资源的状态,而 POST 请求是不幂等的,即每次执行可能会产生不同的结果或影响资源的状态。
+- 格式:GET 请求的参数通常放在 URL 中,形成查询字符串(querystring),而 POST 请求的参数通常放在请求体(body)中,可以有多种编码格式,如 application/x-www-form-urlencoded、multipart/form-data、application/json 等。GET 请求的 URL 长度受到浏览器和服务器的限制,而 POST 请求的 body 大小则没有明确的限制。不过,实际上 GET 请求也可以用 body 传输数据,只是并不推荐这样做,因为这样可能会导致一些兼容性或者语义上的问题。
+- 缓存:由于 GET 请求是幂等的,它可以被浏览器或其他中间节点(如代理、网关)缓存起来,以提高性能和效率。而 POST 请求则不适合被缓存,因为它可能有副作用,每次执行可能需要实时的响应。
+- 安全性:GET 请求和 POST 请求如果使用 HTTP 协议的话,那都不安全,因为 HTTP 协议本身是明文传输的,必须使用 HTTPS 协议来加密传输数据。另外,GET 请求相比 POST 请求更容易泄露敏感数据,因为 GET 请求的参数通常放在 URL 中。
+
+再次提示,重点搞清两者在语义上的区别即可,实际使用过程中,也是通过语义来区分使用 GET 还是 POST。不过,也有一些项目所有的请求都用 POST,这个并不是固定的,项目组达成共识即可。
+
+## WebSocket
+
+### 什么是 WebSocket?
+
+WebSocket 是一种基于 TCP 连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据。
+
+WebSocket 协议在 2008 年诞生,2011 年成为国际标准,几乎所有主流较新版本的浏览器都支持该协议。不过,WebSocket 不只能在基于浏览器的应用程序中使用,很多编程语言、框架和服务器都提供了 WebSocket 支持。
+
+WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持久通信能力上的不足。客户端和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
+
+
+
+下面是 WebSocket 的常见应用场景:
+
+- 视频弹幕
+- 实时消息推送,详见[Web 实时消息推送详解](https://javaguide.cn/system-design/web-real-time-message-push.html)这篇文章
+- 实时游戏对战
+- 多用户协同编辑
+- 社交聊天
+- ……
+
+### ⭐️WebSocket 和 HTTP 有什么区别?
+
+WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网络中传输数据。
+
+下面是二者的主要区别:
+
+- WebSocket 是一种双向实时通信协议,而 HTTP 是一种单向通信协议。并且,HTTP 协议下的通信只能由客户端发起,服务器无法主动通知客户端。
+- WebSocket 使用 ws:// 或 wss://(使用 SSL/TLS 加密后的协议,类似于 HTTP 和 HTTPS 的关系) 作为协议前缀,HTTP 使用 http:// 或 https:// 作为协议前缀。
+- WebSocket 可以支持扩展,用户可以扩展协议,实现部分自定义的子协议,如支持压缩、加密等。
+- WebSocket 通信数据格式比较轻量,用于协议控制的数据包头部相对较小,网络开销小,而 HTTP 通信每次都要携带完整的头部,网络开销较大(HTTP/2.0 使用二进制帧进行数据传输,还支持头部压缩,减少了网络开销)。
+
+### WebSocket 的工作过程是什么样的?
+
+WebSocket 的工作过程可以分为以下几个步骤:
+
+1. 客户端向服务器发送一个 HTTP 请求,请求头中包含 `Upgrade: websocket` 和 `Sec-WebSocket-Key` 等字段,表示要求升级协议为 WebSocket;
+2. 服务器收到这个请求后,会进行升级协议的操作,如果支持 WebSocket,它将回复一个 HTTP 101 状态码,响应头中包含 `Connection: Upgrade` 和 `Sec-WebSocket-Accept: xxx` 等字段,表示成功升级到 WebSocket 协议。
+3. 客户端和服务器之间建立了一个 WebSocket 连接,可以进行双向的数据传输。数据以帧(frames)的形式进行传送,WebSocket 的每条消息可能会被切分成多个数据帧(最小单位)。发送端会将消息切割成多个帧发送给接收端,接收端接收消息帧,并将关联的帧重新组装成完整的消息。
+4. 客户端或服务器可以主动发送一个关闭帧,表示要断开连接。另一方收到后,也会回复一个关闭帧,然后双方关闭 TCP 连接。
+
+另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
+
+### ⭐️WebSocket 与短轮询、长轮询的区别
+
+这三种方式,都是为了解决“**客户端如何及时获取服务器最新数据,实现实时更新**”的问题。它们的实现方式和效率、实时性差异较大。
+
+**1.短轮询(Short Polling)**
+
+- **原理**:客户端每隔固定时间(如 5 秒)发起一次 HTTP 请求,询问服务器是否有新数据。服务器收到请求后立即响应。
+- **优点**:实现简单,兼容性好,直接用常规 HTTP 请求即可。
+- **缺点**:
+ - **实时性一般**:消息可能在两次轮询间到达,用户需等到下次请求才知晓。
+ - **资源浪费大**:反复建立/关闭连接,且大多数请求收到的都是“无新消息”,极大增加服务器和网络压力。
+
+**2.长轮询(Long Polling)**
+
+- **原理**:客户端发起请求后,若服务器暂时无新数据,则会保持连接,直到有新数据或超时才响应。客户端收到响应后立即发起下一次请求,实现“伪实时”。
+- **优点**:
+ - **实时性较好**:一旦有新数据可立即推送,无需等待下次定时请求。
+ - **空响应减少**:减少了无效的空响应,提升了效率。
+- **缺点**:
+ - **服务器资源占用高**:需长时间维护大量连接,消耗服务器线程/连接数。
+ - **资源浪费大**:每次响应后仍需重新建立连接,且依然基于 HTTP 单向请求-响应机制。
+
+**3. WebSocket**
+
+- **原理**:客户端与服务器通过一次 HTTP Upgrade 握手后,建立一条持久的 TCP 连接。之后,双方可以随时、主动地发送数据,实现真正的全双工、低延迟通信。
+- **优点**:
+ - **实时性强**:数据可即时双向收发,延迟极低。
+ - **资源效率高**:连接持续,无需反复建立/关闭,减少资源消耗。
+ - **功能强大**:支持服务端主动推送消息、客户端主动发起通信。
+- **缺点**:
+ - **使用限制**:需要服务器和客户端都支持 WebSocket 协议。对连接管理有一定要求(如心跳保活、断线重连等)。
+ - **实现麻烦**:实现起来比短轮询和长轮询要更麻烦一些。
+
+
+
+### ⭐️SSE 与 WebSocket 有什么区别?
+
+SSE (Server-Sent Events) 和 WebSocket 都是用来实现服务器向浏览器实时推送消息的技术,让网页内容能自动更新,而不需要用户手动刷新。虽然目标相似,但它们在工作方式和适用场景上有几个关键区别:
+
+1. **通信方式:**
+ - **SSE:** **单向通信**。只有服务器能向客户端(浏览器)发送数据。客户端不能通过同一个连接向服务器发送数据(需要发起新的 HTTP 请求)。
+ - **WebSocket:** **双向通信 (全双工)**。客户端和服务器可以随时互相发送消息,实现真正的实时交互。
+2. **底层协议:**
+ - **SSE:** 基于**标准的 HTTP/HTTPS 协议**。它本质上是一个“长连接”的 HTTP 请求,服务器保持连接打开并持续发送事件流。不需要特殊的服务器或协议支持,现有的 HTTP 基础设施就能用。
+ - **WebSocket:** 使用**独立的 ws:// 或 wss:// 协议**。它需要通过一个特定的 HTTP "Upgrade" 请求来建立连接,并且服务器需要明确支持 WebSocket 协议来处理连接和消息帧。
+3. **实现复杂度和成本:**
+ - **SSE:** **实现相对简单**,主要在服务器端处理。浏览器端有标准的 EventSource API,使用方便。开发和维护成本较低。
+ - **WebSocket:** **稍微复杂一些**。需要服务器端专门处理 WebSocket 连接和协议,客户端也需要使用 WebSocket API。如果需要考虑兼容性、心跳、重连等,开发成本会更高。
+4. **断线重连:**
+ - **SSE:** **浏览器原生支持**。EventSource API 提供了自动断线重连的机制。
+ - **WebSocket:** **需要手动实现**。开发者需要自己编写逻辑来检测断线并进行重连尝试。
+5. **数据类型:**
+ - **SSE:** **主要设计用来传输文本** (UTF-8 编码)。如果需要传输二进制数据,需要先进行 Base64 等编码转换成文本。
+ - **WebSocket:** **原生支持传输文本和二进制数据**,无需额外编码。
+
+为了提供更好的用户体验和利用其简单、高效、基于标准 HTTP 的特性,**Server-Sent Events (SSE) 是目前大型语言模型 API(如 OpenAI、DeepSeek 等)实现流式响应的常用甚至可以说是标准的技术选择**。
+
+这里以 DeepSeek 为例,我们发送一个请求并打开浏览器控制台验证一下:
+
+
+
+
+
+可以看到,响应头里包含了 `text/event-stream`,说明使用的确实是 SSE。并且,响应数据也确实是持续分块传输。
+
+## PING
+
+### PING 命令的作用是什么?
+
+PING 命令是一种常用的网络诊断工具,经常用来测试网络中主机之间的连通性和网络延迟。
+
+这里简单举一个例子,我们来 PING 一下百度。
+
+```bash
+# 发送4个PING请求数据包到 www.baidu.com
+❯ ping -c 4 www.baidu.com
+
+PING www.a.shifen.com (14.119.104.189): 56 data bytes
+64 bytes from 14.119.104.189: icmp_seq=0 ttl=54 time=27.867 ms
+64 bytes from 14.119.104.189: icmp_seq=1 ttl=54 time=28.732 ms
+64 bytes from 14.119.104.189: icmp_seq=2 ttl=54 time=27.571 ms
+64 bytes from 14.119.104.189: icmp_seq=3 ttl=54 time=27.581 ms
+
+--- www.a.shifen.com ping statistics ---
+4 packets transmitted, 4 packets received, 0.0% packet loss
+round-trip min/avg/max/stddev = 27.571/27.938/28.732/0.474 ms
+```
+
+PING 命令的输出结果通常包括以下几部分信息:
+
+1. **ICMP Echo Request(请求报文)信息**:序列号、TTL(Time to Live)值。
+2. **目标主机的域名或 IP 地址**:输出结果的第一行。
+3. **往返时间(RTT,Round-Trip Time)**:从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
+4. **统计结果(Statistics)**:包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
+
+如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题(有些主机或网络管理员可能禁用了对 ICMP 请求的回复,这样也会导致无法得到正确的响应)。如果往返时间(RTT)过高,则表明网络延迟过高。
+
+### PING 命令的工作原理是什么?
+
+PING 基于网络层的 **ICMP(Internet Control Message Protocol,互联网控制报文协议)**,其主要原理就是通过在网络上发送和接收 ICMP 报文实现的。
+
+ICMP 报文中包含了类型字段,用于标识 ICMP 报文类型。ICMP 报文的类型有很多种,但大致可以分为两类:
+
+- **查询报文类型**:向目标主机发送请求并期望得到响应。
+- **差错报文类型**:向源主机发送错误信息,用于报告网络中的错误情况。
+
+PING 用到的 ICMP Echo Request(类型为 8 ) 和 ICMP Echo Reply(类型为 0) 属于查询报文类型 。
+
+- PING 命令会向目标主机发送 ICMP Echo Request。
+- 如果两个主机的连通性正常,目标主机会返回一个对应的 ICMP Echo Reply。
+
+## DNS
+
+### DNS 的作用是什么?
+
+DNS(Domain Name System)域名管理系统,是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是**域名和 IP 地址的映射问题**。
+
+
+
+在一台电脑上,可能存在浏览器 DNS 缓存,操作系统 DNS 缓存,路由器 DNS 缓存。如果以上缓存都查询不到,那么 DNS 就闪亮登场了。
+
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53** 。
+
+### DNS 服务器有哪些?根服务器有多少个?
+
+DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
+
+- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
+- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如`com`、`org`、`net`和`edu`等。国家也有自己的顶级域,如`uk`、`fr`和`ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
+- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
+- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构
+
+世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 1700 多台,未来还会继续增加。
+
+### ⭐️DNS 解析的过程是什么样的?
+
+整个过程的步骤比较多,我单独写了一篇文章详细介绍:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html) 。
+
+### DNS 劫持了解吗?如何应对?
+
+DNS 劫持是一种网络攻击,它通过修改 DNS 服务器的解析结果,使用户访问的域名指向错误的 IP 地址,从而导致用户无法访问正常的网站,或者被引导到恶意的网站。DNS 劫持有时也被称为 DNS 重定向、DNS 欺骗或 DNS 污染。
+
+## 参考
+
+- 《图解 HTTP》
+- 《计算机网络自顶向下方法》(第七版)
+- 详解 HTTP/2.0 及 HTTPS 协议:
+- HTTP 请求头字段大全| HTTP Request Headers:
+- HTTP1、HTTP2、HTTP3:
+- 如何看待 HTTP/3 ? - 车小胖的回答 - 知乎:
+
+
diff --git a/docs/cs-basics/network/other-network-questions2.md b/docs/cs-basics/network/other-network-questions2.md
new file mode 100644
index 00000000000..e98ece86cde
--- /dev/null
+++ b/docs/cs-basics/network/other-network-questions2.md
@@ -0,0 +1,276 @@
+---
+title: 计算机网络常见面试题总结(下)
+description: 最新计算机网络高频面试题总结(下):TCP/UDP深度对比、三次握手四次挥手、HTTP/3 QUIC优化、IPv6优势、NAT/ARP详解,附表格+⭐️重点标注,一文掌握传输层&网络层核心考点,快速通关后端技术面试!
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP vs UDP,TCP三次握手,HTTP/3 QUIC,IPv4 vs IPv6,TCP可靠性,IP地址,NAT协议,ARP协议,传输层面试,网络层高频题,基于TCP协议,基于UDP协议,队头阻塞,四次挥手
+---
+
+
+
+计算机网络面试题里,真正容易被追问到细节的部分,往往集中在 **TCP、UDP、IP、ARP、NAT、IPv4/IPv6** 这些传输层和网络层知识点上。比如:为什么 TCP 可靠?为什么要三次握手和四次挥手?HTTP/3 为什么改用基于 UDP 的 QUIC?这些问题不仅考概念,也考你对网络通信过程的理解。
+
+这篇《计算机网络常见面试题总结(下)》会重点梳理 TCP 与 UDP、TCP 连接管理、可靠传输、IP 地址、ARP、NAT 等后端面试高频内容,帮助你把传输层和网络层的核心考点串起来。
+
+## TCP 与 UDP
+
+### ⭐️TCP 与 UDP 的区别(重要)
+
+1. **是否面向连接**:
+ - TCP 是面向连接的。在传输数据之前,必须先通过“三次握手”建立连接;数据传输完成后,还需要通过“四次挥手”来释放连接。这保证了双方都准备好通信。
+ - UDP 是无连接的。发送数据前不需要建立任何连接,直接把数据包(数据报)扔出去。
+2. **是否是可靠传输**:
+ - TCP 提供可靠的数据传输服务。它通过序列号、确认应答 (ACK)、超时重传、流量控制、拥塞控制等一系列机制,来确保数据能够无差错、不丢失、不重复且按顺序地到达目的地。
+ - UDP 提供不可靠的传输。它尽最大努力交付 (best-effort delivery),但不保证数据一定能到达,也不保证到达的顺序,更不会自动重传。收到报文后,接收方也不会主动发确认。
+3. **是否有状态**:
+ - TCP 是有状态的。因为要保证可靠性,TCP 需要在连接的两端维护连接状态信息,比如序列号、窗口大小、哪些数据发出去了、哪些收到了确认等。
+ - UDP 是无状态的。它不维护连接状态,发送方发出数据后就不再关心它是否到达以及如何到达,因此开销更小(**这很“渣男”!**)。
+4. **传输效率**:
+ - TCP 因为需要建立连接、发送确认、处理重传等,其开销较大,传输效率相对较低。
+ - UDP 结构简单,没有复杂的控制机制,开销小,传输效率更高,速度更快。
+5. **传输形式**:
+ - TCP 是面向字节流 (Byte Stream) 的。它将应用程序交付的数据视为一连串无结构的字节流,可能会对数据进行拆分或合并。
+ - UDP 是面向报文 (Message Oriented) 的。应用程序交给 UDP 多大的数据块,UDP 就照样发送,既不拆分也不合并,保留了应用程序消息的边界。
+6. **首部开销**:
+ - TCP 的头部至少需要 20 字节,如果包含选项字段,最多可达 60 字节。
+ - UDP 的头部非常简单,固定只有 8 字节。
+7. **是否提供广播或多播服务**:
+ - TCP 只支持点对点 (Point-to-Point) 的单播通信。
+ - UDP 支持一对一 (单播)、一对多 (多播/Multicast) 和一对所有 (广播/Broadcast) 的通信方式。
+8. ……
+
+为了更直观地对比,可以看下面这个表格:
+
+| 特性 | TCP | UDP |
+| ------------ | -------------------------- | ----------------------------------- |
+| **连接性** | 面向连接 | 无连接 |
+| **可靠性** | 可靠 | 不可靠 (尽力而为) |
+| **状态维护** | 有状态 | 无状态 |
+| **传输效率** | 较低 | 较高 |
+| **传输形式** | 面向字节流 | 面向数据报 (报文) |
+| **头部开销** | 20 - 60 字节 | 8 字节 |
+| **通信模式** | 点对点 (单播) | 单播、多播、广播 |
+| **常见应用** | HTTP/HTTPS, FTP, SMTP, SSH | DNS, DHCP, SNMP, TFTP, VoIP, 视频流 |
+
+### ⭐️什么时候选择 TCP,什么时候选 UDP?
+
+选择 TCP 还是 UDP,主要取决于你的应用**对数据传输的可靠性要求有多高,以及对实时性和效率的要求有多高**。
+
+当**数据准确性和完整性至关重要,一点都不能出错**时,通常选择 TCP。因为 TCP 提供了一整套机制(三次握手、确认应答、重传、流量控制等)来保证数据能够可靠、有序地送达。典型应用场景如下:
+
+- **Web 浏览 (HTTP/HTTPS):** 网页内容、图片、脚本必须完整加载才能正确显示。
+- **文件传输 (FTP, SCP):** 文件内容不允许有任何字节丢失或错序。
+- **邮件收发 (SMTP, POP3, IMAP):** 邮件内容需要完整无误地送达。
+- **远程登录 (SSH, Telnet):** 命令和响应需要准确传输。
+- ……
+
+当**实时性、速度和效率优先,并且应用能容忍少量数据丢失或乱序**时,通常选择 UDP。UDP 开销小、传输快,没有建立连接和保证可靠性的复杂过程。典型应用场景如下:
+
+- **实时音视频通信 (VoIP, 视频会议, 直播):** 偶尔丢失一两个数据包(可能导致画面或声音短暂卡顿)通常比因为等待重传(TCP 机制)导致长时间延迟更可接受。应用层可能会有自己的补偿机制。
+- **在线游戏:** 需要快速传输玩家位置、状态等信息,对实时性要求极高,旧的数据很快就没用了,丢失少量数据影响通常不大。
+- **DHCP (动态主机配置协议):** 客户端在请求 IP 时自身没有 IP 地址,无法满足 TCP 建立连接的前提条件,并且 DHCP 有广播需求、交互模式简单以及自带可靠性机制。
+- **物联网 (IoT) 数据上报:** 某些场景下,传感器定期上报数据,丢失个别数据点可能不影响整体趋势分析。
+- ……
+
+### HTTP 基于 TCP 还是 UDP?
+
+~~**HTTP 协议是基于 TCP 协议的**,所以发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。~~
+
+🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):
+
+HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** :
+
+- **HTTP/1.x 和 HTTP/2.0**:这两个版本的 HTTP 协议都明确建立在 TCP 之上。TCP 提供了可靠的、面向连接的传输,确保数据按序、无差错地到达,这对于网页内容的正确展示非常重要。发送 HTTP 请求前,需要先通过 TCP 的三次握手建立连接。
+- **HTTP/3.0**:这是一个重大的改变。HTTP/3 弃用了 TCP,转而使用 QUIC 协议,而 QUIC 是构建在 UDP 之上的。
+
+
+
+**为什么 HTTP/3 要做这个改变呢?主要有两大原因:**
+
+1. 解决队头阻塞 (Head-of-Line Blocking,简写:HOL blocking) 问题。
+2. 减少连接建立的延迟。
+
+下面我们来详细介绍这两大优化。
+
+在 HTTP/2 中,虽然可以在一个 TCP 连接上并发传输多个请求/响应流(多路复用),但 TCP 本身的特性(保证有序、可靠)意味着如果其中一个流的某个 TCP 报文丢失或延迟,整个 TCP 连接都会被阻塞,等待该报文重传。这会导致所有在这个 TCP 连接上的 HTTP/2 流都受到影响,即使其他流的数据包已经到达。**QUIC (运行在 UDP 上) 解决了这个问题**。QUIC 内部实现了自己的多路复用和流控制机制。不同的 HTTP 请求/响应流在 QUIC 层面是真正独立的。如果一个流的数据包丢失,它只会阻塞该流,而不会影响同一 QUIC 连接上的其他流(本质上是多路复用+轮询),大大提高了并发传输的效率。
+
+除了解决队头阻塞问题,HTTP/3.0 还可以减少握手过程的延迟。在 HTTP/2.0 中,如果要建立一个安全的 HTTPS 连接,需要经过 TCP 三次握手和 TLS 握手:
+
+1. TCP 三次握手:客户端和服务器交换 SYN 和 ACK 包,建立一个 TCP 连接。这个过程需要 1.5 个 RTT(round-trip time),即一个数据包从发送到接收的时间。
+2. TLS 握手:客户端和服务器交换密钥和证书,建立一个 TLS 加密层。这个过程需要至少 1 个 RTT(TLS 1.3)或者 2 个 RTT(TLS 1.2)。
+
+所以,HTTP/2.0 的连接建立就至少需要 2.5 个 RTT(TLS 1.3)或者 3.5 个 RTT(TLS 1.2)。而在 HTTP/3.0 中,使用的 QUIC 协议(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
+
+相关证明可以参考下面这两个链接:
+
+-
+-
+
+### 你知道哪些基于 TCP/UDP 的协议?
+
+TCP (传输控制协议) 和 UDP (用户数据报协议) 是互联网传输层的两大核心协议,它们为各种应用层协议提供了基础的通信服务。以下是一些常见的、分别构建在 TCP 和 UDP 之上的应用层协议:
+
+**运行于 TCP 协议之上的协议 (强调可靠、有序传输):**
+
+| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
+| -------------------------- | ---------------------------------- | ---------------------------- | --------------------------------------------------------------------------------------------------------------------------- |
+| 超文本传输协议 (HTTP) | HyperText Transfer Protocol | 传输网页、超文本、多媒体内容 | **HTTP/1.x 和 HTTP/2 基于 TCP**。早期版本不加密,是 Web 通信的基础。 |
+| 安全超文本传输协议 (HTTPS) | HyperText Transfer Protocol Secure | 加密的网页传输 | 在 HTTP 和 TCP 之间增加了 SSL/TLS 加密层,确保数据传输的机密性和完整性。 |
+| 文件传输协议 (FTP) | File Transfer Protocol | 文件传输 | 传统的 FTP **明文传输**,不安全。推荐使用其安全版本 **SFTP (SSH File Transfer Protocol)** 或 **FTPS (FTP over SSL/TLS)** 。 |
+| 简单邮件传输协议 (SMTP) | Simple Mail Transfer Protocol | **发送**电子邮件 | 负责将邮件从客户端发送到服务器,或在邮件服务器之间传递。可通过 **STARTTLS** 升级到加密传输。 |
+| 邮局协议第 3 版 (POP3) | Post Office Protocol version 3 | **接收**电子邮件 | 通常将邮件从服务器**下载到本地设备后删除服务器副本** (可配置保留)。**POP3S** 是其 SSL/TLS 加密版本。 |
+| 互联网消息访问协议 (IMAP) | Internet Message Access Protocol | **接收和管理**电子邮件 | 邮件保留在服务器,支持多设备同步邮件状态、文件夹管理、在线搜索等。**IMAPS** 是其 SSL/TLS 加密版本。现代邮件服务首选。 |
+| 远程终端协议 (Telnet) | Teletype Network | 远程终端登录 | **明文传输**所有数据 (包括密码),安全性极差,基本已被 SSH 完全替代。 |
+| 安全外壳协议 (SSH) | Secure Shell | 安全远程管理、加密数据传输 | 提供了加密的远程登录和命令执行,以及安全的文件传输 (SFTP) 等功能,是 Telnet 的安全替代品。 |
+
+**运行于 UDP 协议之上的协议 (强调快速、低开销传输):**
+
+| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
+| ----------------------- | ------------------------------------- | -------------------------- | ------------------------------------------------------------------------------------------------------------ |
+| 超文本传输协议 (HTTP/3) | HyperText Transfer Protocol version 3 | 新一代网页传输 | 基于 **QUIC** 协议 (QUIC 本身构建于 UDP 之上),旨在减少延迟、解决 TCP 队头阻塞问题,支持 0-RTT 连接建立。 |
+| 动态主机配置协议 (DHCP) | Dynamic Host Configuration Protocol | 动态分配 IP 地址及网络配置 | 客户端从服务器自动获取 IP 地址、子网掩码、网关、DNS 服务器等信息。 |
+| 域名系统 (DNS) | Domain Name System | 域名到 IP 地址的解析 | **通常使用 UDP** 进行快速查询。当响应数据包过大或进行区域传送 (AXFR) 时,会**切换到 TCP** 以保证数据完整性。 |
+| 实时传输协议 (RTP) | Real-time Transport Protocol | 实时音视频数据流传输 | 常用于 VoIP、视频会议、直播等。追求低延迟,允许少量丢包。通常与 RTCP 配合使用。 |
+| RTP 控制协议 (RTCP) | RTP Control Protocol | RTP 流的质量监控和控制信息 | 配合 RTP 工作,提供丢包、延迟、抖动等统计信息,辅助流量控制和拥塞管理。 |
+| 简单文件传输协议 (TFTP) | Trivial File Transfer Protocol | 简化的文件传输 | 功能简单,常用于局域网内无盘工作站启动、网络设备固件升级等小文件传输场景。 |
+| 简单网络管理协议 (SNMP) | Simple Network Management Protocol | 网络设备的监控与管理 | 允许网络管理员查询和修改网络设备的状态信息。 |
+| 网络时间协议 (NTP) | Network Time Protocol | 同步计算机时钟 | 用于在网络中的计算机之间同步时间,确保时间的一致性。 |
+
+**总结一下:**
+
+- **TCP** 更适合那些对数据**可靠性、完整性和顺序性**要求高的应用,如网页浏览 (HTTP/HTTPS)、文件传输 (FTP/SFTP)、邮件收发 (SMTP/POP3/IMAP)。
+- **UDP** 则更适用于那些对**实时性要求高、能容忍少量数据丢失**的应用,如域名解析 (DNS)、实时音视频 (RTP)、在线游戏、网络管理 (SNMP) 等。
+
+### ⭐️TCP 三次握手和四次挥手(非常重要)
+
+**相关面试题**:
+
+- 为什么要三次握手?
+- 第 2 次握手传回了 ACK,为什么还要传回 SYN?
+- 为什么要四次挥手?
+- 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
+- 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
+- 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
+
+**参考答案**:[TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html) 。
+
+### ⭐️TCP 如何保证传输的可靠性?(重要)
+
+[TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
+
+## IP
+
+### IP 协议的作用是什么?
+
+**IP(Internet Protocol,网际协议)** 是 TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。
+
+目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+
+### 什么是 IP 地址?IP 寻址如何工作?
+
+每个连入互联网的设备或域(如计算机、服务器、路由器等)都被分配一个 **IP 地址(Internet Protocol address)**,作为唯一标识符。每个 IP 地址都是一个字符序列,如 192.168.1.1(IPv4)、2001:0db8:85a3:0000:0000:8a2e:0370:7334(IPv6) 。
+
+当网络设备发送 IP 数据包时,数据包中包含了 **源 IP 地址** 和 **目的 IP 地址** 。源 IP 地址用于标识数据包的发送方设备或域,而目的 IP 地址则用于标识数据包的接收方设备或域。这类似于一封邮件中同时包含了目的地地址和回邮地址。
+
+网络设备根据目的 IP 地址来判断数据包的目的地,并将数据包转发到正确的目的地网络或子网络,从而实现了设备间的通信。
+
+这种基于 IP 地址的寻址方式是互联网通信的基础,它允许数据包在不同的网络之间传递,从而实现了全球范围内的网络互联互通。IP 地址的唯一性和全局性保证了网络中的每个设备都可以通过其独特的 IP 地址进行标识和寻址。
+
+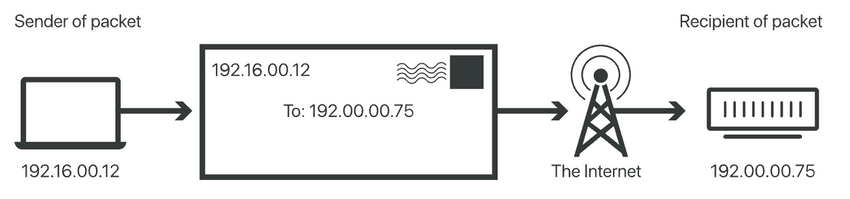
+
+### 什么是 IP 地址过滤?
+
+**IP 地址过滤(IP Address Filtering)** 简单来说就是限制或阻止特定 IP 地址或 IP 地址范围的访问。例如,你有一个图片服务突然被某一个 IP 地址攻击,那我们就可以禁止这个 IP 地址访问图片服务。
+
+IP 地址过滤是一种简单的网络安全措施,实际应用中一般会结合其他网络安全措施,如认证、授权、加密等一起使用。单独使用 IP 地址过滤并不能完全保证网络的安全。
+
+### ⭐️IPv4 和 IPv6 有什么区别?
+
+**IPv4(Internet Protocol version 4)** 是目前广泛使用的 IP 地址版本,其格式是四组由点分隔的数字,例如:123.89.46.72。IPv4 使用 32 位地址作为其 Internet 地址,这意味着共有约 42 亿( 2^32)个可用 IP 地址。
+
+
+
+这么少当然不够用啦!为了解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议 - **IPv6(Internet Protocol version 6)**。IPv6 地址使用更复杂的格式,该格式使用由单或双冒号分隔的一组数字和字母,例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334 。IPv6 使用 128 位互联网地址,这意味着越有 2^128(3 开头的 39 位数字,恐怖如斯) 个可用 IP 地址。
+
+
+
+除了更大的地址空间之外,IPv6 的优势还包括:
+
+- **无状态地址自动配置(Stateless Address Autoconfiguration,简称 SLAAC)**:主机可以直接通过根据接口标识和网络前缀生成全局唯一的 IPv6 地址,而无需依赖 DHCP(Dynamic Host Configuration Protocol)服务器,简化了网络配置和管理。
+- **NAT(Network Address Translation,网络地址转换) 成为可选项**:IPv6 地址资源充足,可以给全球每个设备一个独立的地址。
+- **对标头结构进行了改进**:IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
+- **可选的扩展头**:允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
+- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
+- ……
+
+### 如何获取客户端真实 IP?
+
+获取客户端真实 IP 的方法有多种,主要分为应用层方法、传输层方法和网络层方法。
+
+**应用层方法**:
+
+通过 [X-Forwarded-For](https://en.wikipedia.org/wiki/X-Forwarded-For) 请求头获取,简单方便。不过,这种方法无法保证获取到的是真实 IP,这是因为 X-Forwarded-For 字段可能会被伪造。如果经过多个代理服务器,X-Forwarded-For 字段可能会有多个值(附带了整个请求链中的所有代理服务器 IP 地址)。并且,这种方法只适用于 HTTP 和 SMTP 协议。
+
+**传输层方法**:
+
+利用 TCP Options 字段承载真实源 IP 信息。这种方法适用于任何基于 TCP 的协议,不受应用层的限制。不过,这并非是 TCP 标准所支持的,所以需要通信双方都进行改造。也就是:对于发送方来说,需要有能力把真实源 IP 插入到 TCP Options 里面。对于接收方来说,需要有能力把 TCP Options 里面的 IP 地址读取出来。
+
+也可以通过 Proxy Protocol 协议来传递客户端 IP 和 Port 信息。这种方法可以利用 Nginx 或者其他支持该协议的反向代理服务器来获取真实 IP 或者在业务服务器解析真实 IP。
+
+**网络层方法**:
+
+隧道 + DSR 模式。这种方法可以适用于任何协议,就是实施起来会比较麻烦,也存在一定限制,实际应用中一般不会使用这种方法。
+
+### NAT 的作用是什么?
+
+**NAT(Network Address Translation,网络地址转换)** 主要用于在不同网络之间转换 IP 地址。它允许将私有 IP 地址(如在局域网中使用的 IP 地址)映射为公有 IP 地址(在互联网中使用的 IP 地址)或者反向映射,从而实现局域网内的多个设备通过单一公有 IP 地址访问互联网。
+
+NAT 不光可以缓解 IPv4 地址资源短缺的问题,还可以隐藏内部网络的实际拓扑结构,使得外部网络无法直接访问内部网络中的设备,从而提高了内部网络的安全性。
+
+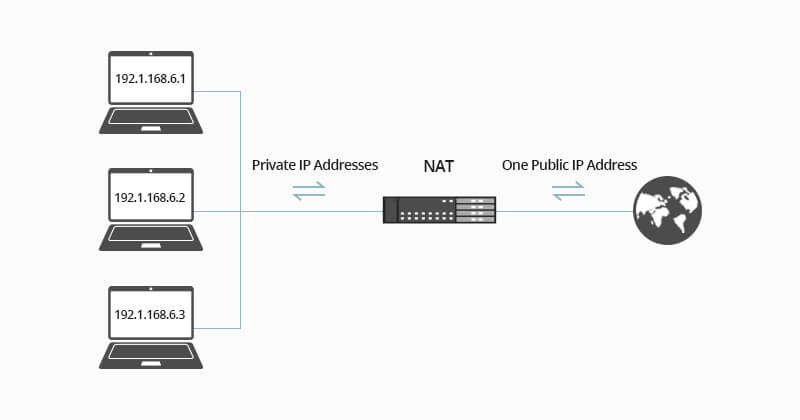
+
+相关阅读:[NAT 协议详解(网络层)](https://javaguide.cn/cs-basics/network/nat.html)。
+
+## ARP
+
+### 什么是 Mac 地址?
+
+MAC 地址的全称是 **媒体访问控制地址(Media Access Control Address)**。如果说,互联网中每一个资源都由 IP 地址唯一标识(IP 协议内容),那么一切网络设备都由 MAC 地址唯一标识。
+
+
+
+可以理解为,MAC 地址是一个网络设备真正的身份证号,IP 地址只是一种不重复的定位方式(比如说住在某省某市某街道的张三,这种逻辑定位是 IP 地址,他的身份证号才是他的 MAC 地址),也可以理解为 MAC 地址是身份证号,IP 地址是邮政地址。MAC 地址也有一些别称,如 LAN 地址、物理地址、以太网地址等。
+
+> 还有一点要知道的是,不仅仅是网络资源才有 IP 地址,网络设备也有 IP 地址,比如路由器。但从结构上说,路由器等网络设备的作用是组成一个网络,而且通常是内网,所以它们使用的 IP 地址通常是内网 IP,内网的设备在与内网以外的设备进行通信时,需要用到 NAT 协议。
+
+MAC 地址的长度为 6 字节(48 比特),地址空间大小有 280 万亿之多( $2^{48}$ ),MAC 地址由 IEEE 统一管理与分配,理论上,一个网络设备中的网卡上的 MAC 地址是永久的。不同的网卡生产商从 IEEE 那里购买自己的 MAC 地址空间(MAC 的前 24 比特),也就是前 24 比特由 IEEE 统一管理,保证不会重复。而后 24 比特,由各家生产商自己管理,同样保证生产的两块网卡的 MAC 地址不会重复。
+
+MAC 地址具有可携带性、永久性,身份证号永久地标识一个人的身份,不论他到哪里都不会改变。而 IP 地址不具有这些性质,当一台设备更换了网络,它的 IP 地址也就可能发生改变,也就是它在互联网中的定位发生了变化。
+
+最后,记住,MAC 地址有一个特殊地址:FF-FF-FF-FF-FF-FF(全 1 地址),该地址表示广播地址。
+
+### ⭐️ARP 协议解决了什么问题?
+
+ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
+
+### ARP 协议的工作原理?
+
+[ARP 协议详解(网络层)](https://javaguide.cn/cs-basics/network/arp.html)
+
+## 复习建议
+
+非常推荐大家看一下 《图解 HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
+
+## 参考
+
+- 《图解 HTTP》
+- 《计算机网络自顶向下方法》(第七版)
+- 什么是 Internet 协议(IP)?:
+- 透传真实源 IP 的各种方法 - 极客时间:
+- What Is NAT and What Are the Benefits of NAT Firewalls?:
+
+
diff --git a/docs/cs-basics/network/tcp-byte-stream-udp-datagram.md b/docs/cs-basics/network/tcp-byte-stream-udp-datagram.md
new file mode 100644
index 00000000000..e3e9fa99205
--- /dev/null
+++ b/docs/cs-basics/network/tcp-byte-stream-udp-datagram.md
@@ -0,0 +1,162 @@
+---
+title: 为什么 TCP 是面向字节流,UDP 是面向报文?(传输层)
+description: 讲清 TCP 字节流与 UDP 报文的本质差异,解析粘包/拆包成因与解决方案,覆盖 Nagle、Delayed ACK 等常见面试考点。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,UDP,字节流,报文,粘包,拆包,消息边界,Nagle,Delayed ACK,TCP_NODELAY
+---
+
+前面说 TCP 是面向字节流,UDP 是面向报文。这个点看起来像一句定义,但很多粘包、拆包问题,其实都藏在这里。
+
+先说结论:**TCP 只保证字节可靠、有序地到达,不保证应用层消息边界;UDP 会保留应用层交给它的报文边界。**
+
+这篇文章主要回答几个问题:
+
+1. 为什么说 TCP 是面向字节流,UDP 是面向报文?
+2. TCP 粘包、拆包到底是怎么产生的?
+3. 应用层应该如何定义消息边界?
+4. Nagle 算法和 Delayed ACK 为什么可能让小包变慢?
+
+举个例子,应用层连续发送两条消息:
+
+```
+消息 1:hello
+消息 2:world
+```
+
+如果用 UDP 发送,通常会对应两个 UDP 数据报。接收方调用 `recvfrom()` 时,也是按数据报来读:一次读取一个 UDP 报文,不会把两次发送的报文合成一个流。UDP 的接收队列里,一个元素就是一个数据报,消息边界天然保留了下来。
+
+不过这里也有一个细节:UDP 保留的是传输层报文边界,不代表它适合发送任意大的消息。数据报太大时,底层 IP 层仍可能分片;接收端缓冲区太小时,也可能出现截断。所以 UDP 的“面向报文”不是“随便发多大都没事”,而是说它不会像 TCP 那样把应用数据抽象成一条连续字节流。RFC 768 对 UDP 的定义就是 datagram mode,并说明它提供的是最小协议机制,不保证可靠交付和去重。
+
+如果用 TCP 发送,就不能这么理解。应用层调用两次 `send()`,只是把两段字节写进内核发送缓冲区。至于这些字节什么时候发、合成几个 TCP 段发、对端一次 `recv()` 能读到多少,都不是由这两次 `send()` 直接决定的。
+
+比如,接收端可能一次读到(粘包):
+
+```
+helloworld
+```
+
+也可能分几次读到(拆包):
+
+```
+hel
+lowor
+ld
+```
+
+这不是 TCP 出错,而是 TCP 的工作方式本来就是这样。TCP 处理的是连续字节流,它只关心这些字节是否可靠、有序地到达,不关心应用层定义的“第几条消息”从哪里开始、到哪里结束。RFC 9293 也明确提到,TCP segment 和应用层 `send()` / socket write 的边界通常不是一一对应的,TCP 不保证应用读写缓冲区边界和网络分段边界相关。
+
+
+
+所以,“TCP 粘包/拆包”这个说法更像是应用层视角下的现象。严格来说,TCP 没有“包”的概念,它传的是连续字节流。真正需要解决的是:**应用层协议如何定义消息边界**。
+
+#### 为什么会出现粘包和拆包?
+
+常见原因有这几个。
+
+**1. TCP 是字节流协议,没有应用层消息边界。**
+
+TCP 负责把字节可靠、有序地送到对端,但不会记录“这 20 个字节是第一条消息,那 30 个字节是第二条消息”。
+
+**2. 一次 `send()` 不等于一次网络发送。**
+
+`send()` 成功通常只表示数据从应用进程拷贝到了内核发送缓冲区。至于什么时候真正发出去、拆成几个 TCP 段发,要看 MSS、发送窗口、拥塞窗口、Nagle 算法、网卡队列等因素。
+
+**3. 一次 `recv()` 也不等于读到一条完整消息。**
+
+接收端只是从 TCP 接收缓冲区取字节。缓冲区里可能已经堆了多条消息,也可能只有半条消息。`recv()` 只会把当前可读的数据拷贝给应用,不会帮你按业务消息切分。
+
+**4. 小包优化可能改变发送时机。**
+
+Nagle 算法、Delayed ACK、Linux 自动合并小写入等机制,都可能影响小数据的发送时机。比如 Linux 从 3.14 开始有 `tcp_autocorking`,内核会尽量合并连续的小写入,减少发送包数量;应用也可以用 `TCP_CORK` 明确控制何时“拔塞”发送。
+
+这也是为什么在 Netty、Dubbo、自定义 RPC、IM 网关、游戏服务里,协议编解码都很重要。只要底层用的是 TCP,就必须在应用层定义清楚消息边界。
+
+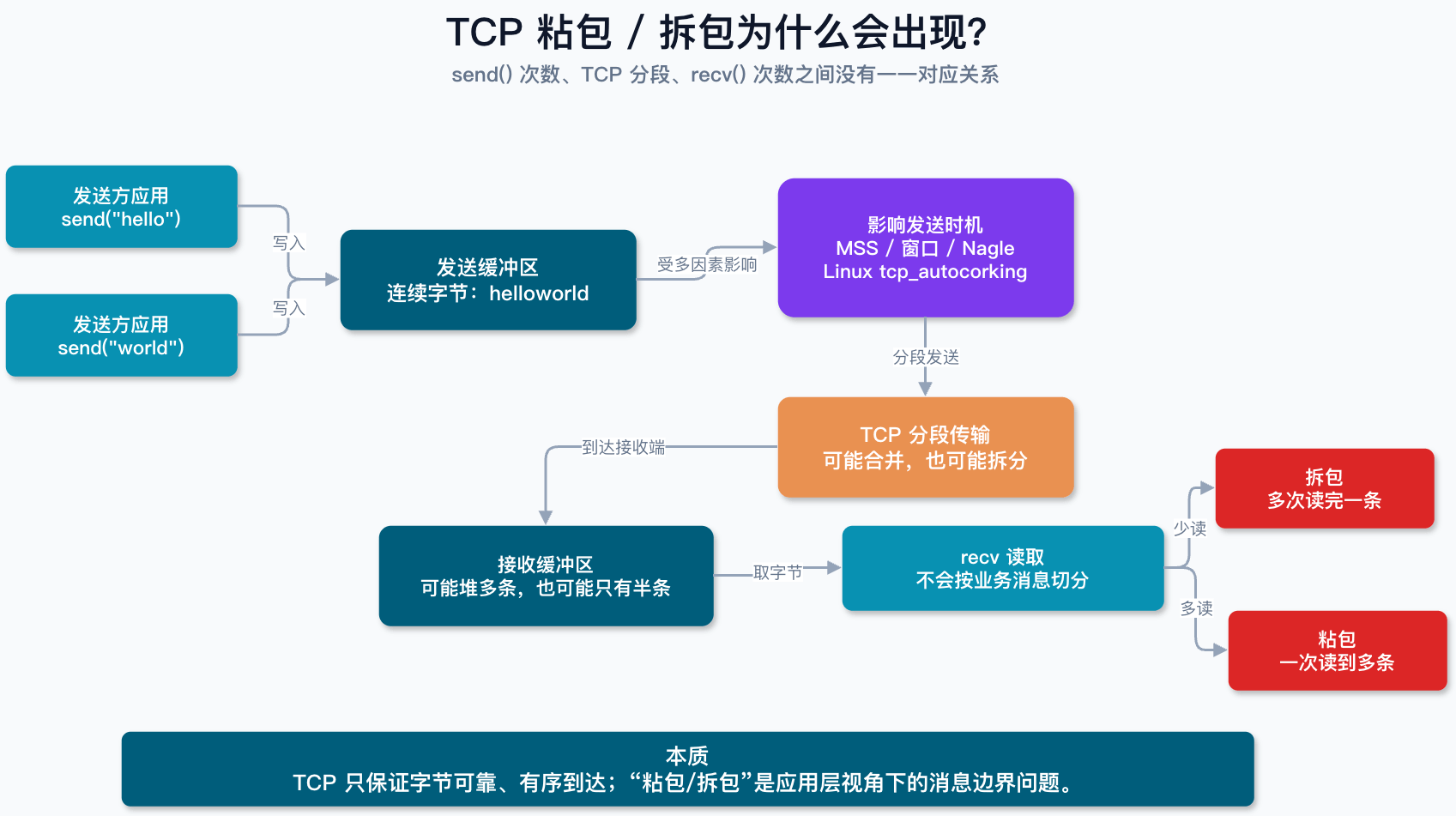
+
+#### 怎么解决 TCP 粘包/拆包?
+
+核心思路只有一个:**让接收方知道一条消息到哪里结束。**
+
+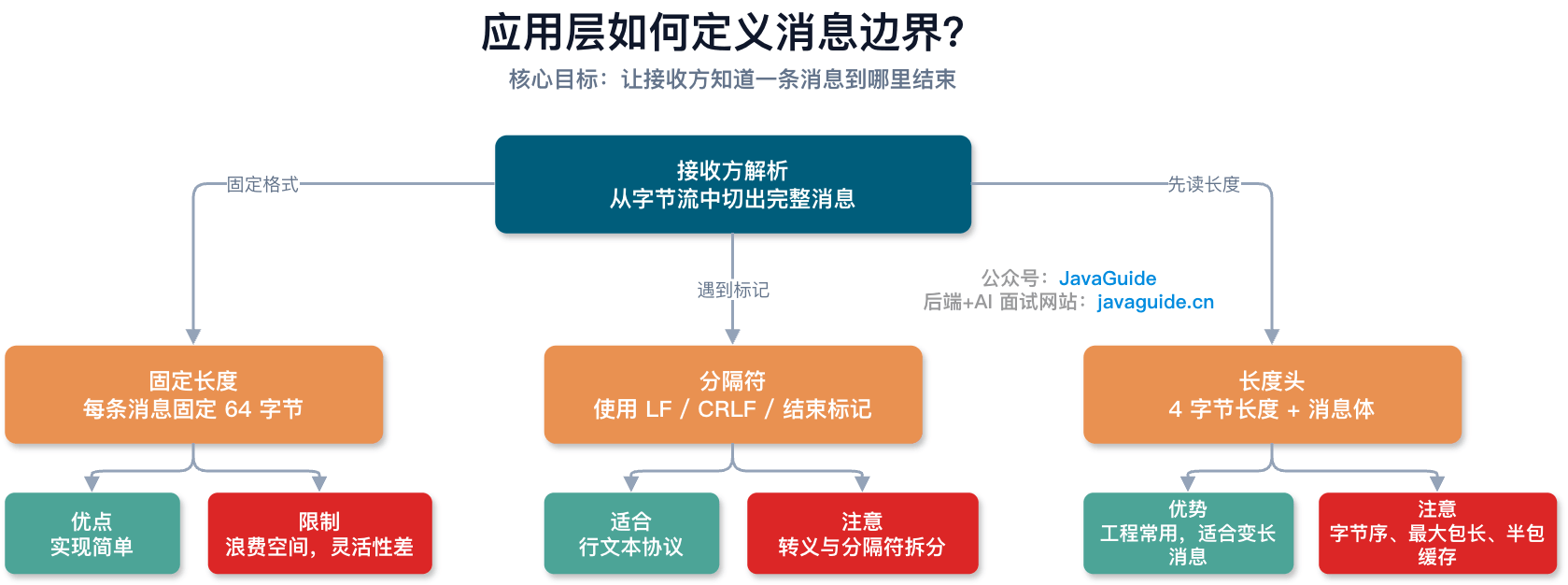
+
+常见做法有三种。
+
+**1. 固定长度**
+
+规定每条消息都是固定长度,比如 64 字节。接收方每读满 64 字节,就认为读到了一条完整消息。
+
+这种方式实现简单,但灵活性差。消息短了要补齐,浪费空间;消息长了又要额外拆分。它适合消息格式非常固定的场景,不太适合通用业务协议。
+
+**2. 分隔符**
+
+在消息之间加特殊分隔符,比如换行符 `\n`、`\r\n`,或者自定义结束标记。
+
+```
+hello\n
+world\n
+```
+
+接收方不断从缓冲区读数据,只要遇到分隔符,就切出一条完整消息。很多文本协议都会用类似思路。
+
+这种方式直观,但要注意两个问题:第一,分隔符可能刚好出现在消息体里,这时需要转义;第二,分隔符本身也可能被拆在两次读取里,所以接收端解析时不能假设一次 `recv()` 就能读到完整分隔符。
+
+**3. 长度头**
+
+这是工程里更常见的一种方式。协议头里固定放一个长度字段,表示后面的消息体有多少字节。
+
+```
+| 4 字节长度 | 消息体 |
+```
+
+接收方先读固定长度的协议头,解析出消息体长度,再继续读取指定字节数。只要没有读满,就继续等待;如果读多了,就把多出来的字节留在缓冲区,作为下一条消息的开头。
+
+很多二进制协议、RPC 协议都会用这种方式。实际设计时,协议头里通常不只放长度,还会放魔数、版本号、消息类型、序列号、序列化方式等字段。
+
+长度头方案也有坑。长度字段要约定字节序,通常使用网络字节序;还要限制最大包体长度,避免对端传一个特别大的长度值,把内存撑爆。线上做协议解析时,不能只考虑正常路径,还要处理半包、异常长度、连接中途关闭、恶意构造请求等情况。
+
+#### Nagle 算法和 Delayed ACK 为什么会让小包变慢?
+
+讲粘包时,经常会顺带问到 Nagle 算法。
+
+Nagle 算法的目标是减少小包数量。早期网络带宽有限,如果应用每次只写 1 个字节,TCP/IP 头部却有几十个字节,网络里就会充满“小包”,效率很低。RFC 896 讨论的就是这类 small-packet problem,并提出当连接上还有未确认数据时,新的小数据可以先暂缓发送,等 ACK 到来后再继续发送。
+
+Delayed ACK 是接收端的优化。接收端收到数据后,不一定立刻发 ACK,而是等一小段时间,看能不能把 ACK 和要返回的数据一起发出去,减少纯 ACK 包数量。RFC 9293 也把这种“少于每个数据段一个 ACK”的策略称为 delayed ACK。
+
+这两个机制单独看都有道理,放在一起就可能放大延迟。典型场景是:
+
+```
+客户端 write 小数据 A
+客户端马上 write 小数据 B
+客户端等待服务端响应
+```
+
+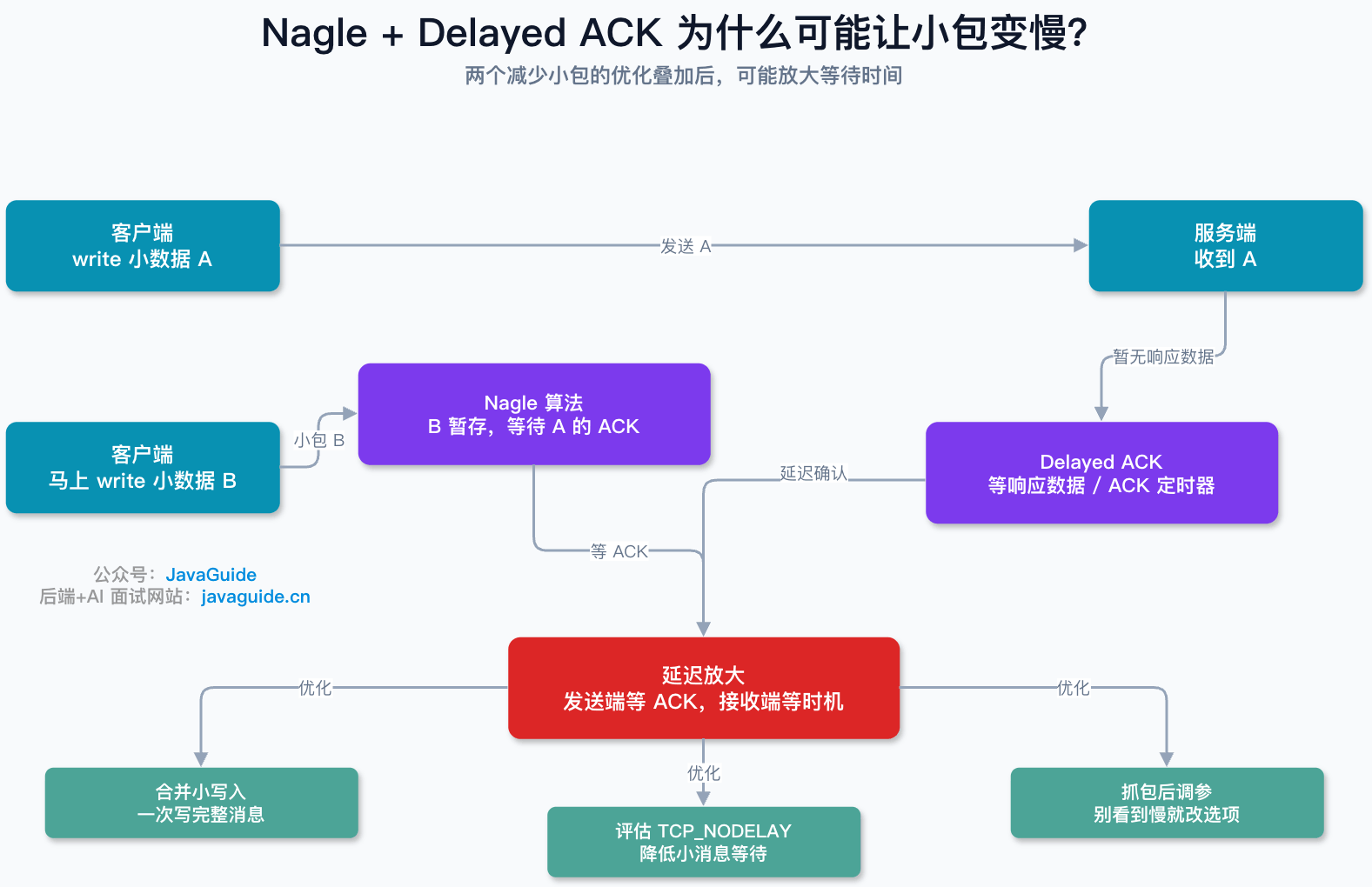
+
+小数据 A 发出去了,小数据 B 可能因为 Nagle 算法暂存在发送缓冲区里,等待 A 的 ACK。服务端收到 A 后,如果暂时没有业务响应要返回,Delayed ACK 又可能延迟发送 ACK。于是发送端等 ACK,接收端等更多数据或等延迟确认定时器,延迟就被放大了。
+
+这类问题在短小 RPC、交互式协议、游戏同步、远程终端里更容易被感知。
+
+解决思路不是“无脑关 Nagle”。更稳的做法是:
+
+- 能合并的小写入,在应用层先合并成一次完整消息,再调用一次 `write()`。
+- 请求/响应模型里,尽量避免连续多次小 `write()` 后马上等待响应。
+- 对延迟敏感、消息很小的连接,可以评估开启 `TCP_NODELAY`,让小数据尽快发送。
+- 对吞吐优先、希望攒够数据再发的场景,可以在 Linux 上评估 `TCP_CORK`,但它不适合写跨平台代码。
+- 调参前先抓包确认,不要看到“慢”就直接改 socket 选项。
+
+在 Java 里,很多网络框架都会暴露 `TCP_NODELAY` 配置,例如 Netty 的 `ChannelOption.TCP_NODELAY`。它确实能降低小消息的等待时间,但也可能增加小包数量。对高 QPS 服务来说,这个 trade-off 要结合消息大小、RTT、吞吐、CPU 和网卡包量一起看。Linux `tcp(7)` 也说明,`TCP_NODELAY` 会关闭 Nagle 算法,而 `TCP_CORK` 则用于避免发送不完整帧、等应用确认“可以发了”再发送。
+
+#### 面试时怎么回答?
+
+可以这么回答:
+
+TCP 是面向字节流的。应用层写入的数据会进入内核缓冲区,TCP 只保证这些字节可靠、有序地到达对端,不保证一次 `send()` 对应一次 `recv()`,也不保留应用层消息边界。因此接收方可能一次读到多条消息,也可能只读到半条消息,这就是常说的粘包、拆包现象。
+
+UDP 是面向报文的。应用层交给 UDP 的一次数据会作为一个 UDP 数据报发送,接收端也是按数据报读取,所以天然保留消息边界。不过 UDP 不保证可靠到达,也不保证顺序。
+
+解决 TCP 粘包/拆包,本质是应用层协议自己定义消息边界。常见方案有固定长度、分隔符、长度头。工程里更常用长度头,因为它对二进制协议和变长消息更友好,但要处理字节序、最大长度限制、半包缓存和异常连接关闭等问题。
diff --git a/docs/cs-basics/network/tcp-connection-and-disconnection.md b/docs/cs-basics/network/tcp-connection-and-disconnection.md
new file mode 100644
index 00000000000..ddc092ba7cc
--- /dev/null
+++ b/docs/cs-basics/network/tcp-connection-and-disconnection.md
@@ -0,0 +1,452 @@
+---
+title: TCP 三次握手和四次挥手(传输层)
+description: 一文讲清 TCP 三次握手与四次挥手:SEQ/ACK/SYN/FIN 如何同步,TIME_WAIT 与 2MSL 的原因,半连接队列(SYN Queue)与全连接队列(Accept Queue)的工作机制,以及 backlog/somaxconn/syncookies 在高并发与 SYN Flood 下的影响。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,三次握手,四次挥手,三次握手为什么,四次挥手为什么,TIME_WAIT,CLOSE_WAIT,2MSL,状态机,SEQ,ACK,SYN,FIN,RST,半连接队列,全连接队列,SYN队列,Accept队列,backlog,somaxconn,SYN Flood,syncookies
+---
+
+TCP(Transmission Control Protocol)是一种**面向连接**、**可靠**的传输层协议。这里的“可靠”,通常体现在按序交付、差错检测、丢包重传、流量控制和拥塞控制等方面。
+
+TCP 连接的建立和释放,最常被问到的就是三次握手和四次挥手。它们看起来像固定流程,背后其实是在同步序列号、确认双方收发能力,并尽量安全地释放连接状态。
+
+这篇文章主要回答几个问题:
+
+1. TCP 三次握手每一步分别做了什么?
+2. 为什么建立连接需要三次握手,而不是两次或四次?
+3. TCP 四次挥手每一步分别做了什么?
+4. `TIME_WAIT`、`CLOSE_WAIT`、半连接队列和全连接队列分别该怎么理解?
+
+> **术语约定**:本文正文统一使用 `SYN_RCVD`、`TIME_WAIT` 这类下划线写法;RFC 中常写作 `SYN-RECEIVED`、`TIME-WAIT`,Linux `ss` 命令中常显示为 `syn-recv`、`time-wait`。它们指向的是同一类 TCP 状态,只是不同语境下的写法不同。
+
+## 建立连接:TCP 三次握手
+
+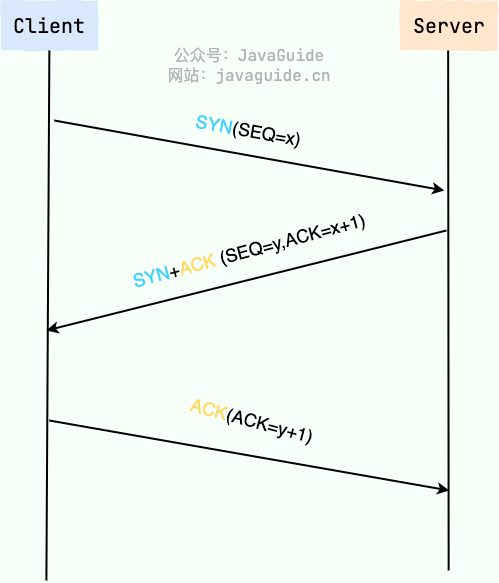
+
+在最常见的“一端主动发起连接、一端被动监听”的场景下,TCP 连接通常通过三次握手建立:
+
+1. **第一次握手(SYN)**:客户端向服务端发送一个 SYN(Synchronize Sequence Numbers)报文段,其中包含客户端生成的初始序列号(Initial Sequence Number,ISN),例如 `seq=x`。发送后,客户端进入 `SYN_SENT` 状态,等待服务端确认。
+2. **第二次握手(SYN+ACK)**:服务端收到 SYN 后,如果同意建立连接,会回复一个 SYN+ACK 报文段。这个报文段包含两个关键信息:
+ - **SYN**:服务端也需要同步自己的初始序列号,因此会携带服务端生成的 ISN,例如 `seq=y`。
+ - **ACK**:用于确认收到客户端的 SYN,确认号设置为客户端初始序列号加一,即 `ack=x+1`。
+ - 发送该报文段后,服务端进入 `SYN_RCVD` 状态。
+3. **第三次握手(ACK)**:客户端收到服务端的 SYN+ACK 后,会向服务端发送最终确认报文段,确认号为 `ack=y+1`。发送后,客户端进入 `ESTABLISHED` 状态。服务端收到这个 ACK 后,也进入 `ESTABLISHED` 状态。
+
+至此,双方完成初始序列号同步,并确认这条连接可以开始双向传输数据。
+
+### 什么是半连接队列和全连接队列?
+
+```mermaid
+sequenceDiagram
+ autonumber
+ participant C as 客户端 Client
+ participant K as 服务端内核 TCP
+ box 服务端内核队列
+ participant SQ as 半连接队列 SYN queue
+ participant AQ as 全连接队列 Accept queue
+ end
+ participant App as 用户态应用 Server app
+
+ C->>K: SYN
+ K-->>C: SYN+ACK
+ Note over SQ: 内核为该连接创建请求条目
+
+上图有一个错误需要注意:是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
+
+总体来说分为以下几个步骤:
+
+1. 在浏览器中输入指定网页的 URL。
+2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
+3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
+4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
+5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
+6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
+7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
+
+详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](https://javaguide.cn/cs-basics/network/the-whole-process-of-accessing-web-pages.html)(强烈推荐)。
+
+### ⭐️HTTP 状态码有哪些?
+
+HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
+
+
+
+关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)。
+
+### HTTP Header 中常见的字段有哪些?
+
+| 请求头字段名 | 说明 | 示例 |
+| :------------------ | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------- |
+| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
+| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
+| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
+| Accept-Encoding | 能够接受的编码方式列表。参考 HTTP 压缩。 | Accept-Encoding: gzip, deflate |
+| Accept-Language | 能够接受的回应内容的自然语言列表。 | Accept-Language: en-US |
+| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令 | Cache-Control: no-cache |
+| Connection | 该浏览器想要优先使用的连接类型 | Connection: keep-alive |
+| Content-Length | 以八位字节数组(8 位的字节)表示的请求体的长度 | Content-Length: 348 |
+| Content-MD5 | 请求体的内容的二进制 MD5 散列值,以 Base64 编码的结果 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
+| Content-Type | 请求体的多媒体类型(用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded |
+| Cookie | 之前由服务器通过 Set-Cookie(下文详述)发送的一个超文本传输协议 Cookie | Cookie: $Version=1; Skin=new; |
+| Date | 发送该消息的日期和时间(按照 RFC 7231 中定义的“超文本传输协议日期”格式来发送) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
+| Expect | 表明客户端要求服务器做出特定的行为 | Expect: 100-continue |
+| From | 发起此请求的用户的邮件地址 | From: `user@example.com` |
+| Host | 服务器的域名(用于虚拟主机),以及服务器所监听的传输控制协议端口号。如果所请求的端口是对应的服务的标准端口,则端口号可被省略。 | Host: en.wikipedia.org |
+| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要作用是用于像 PUT 这样的方法中,仅当从用户上次更新某个资源以来,该资源未被修改的情况下,才更新该资源。 | If-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Modified-Since | 允许服务器在请求的资源自指定的日期以来未被修改的情况下返回 `304 Not Modified` 状态码 | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| If-None-Match | 允许服务器在请求的资源的 ETag 未发生变化的情况下返回 `304 Not Modified` 状态码 | If-None-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Range | 如果该实体未被修改过,则向我发送我所缺少的那一个或多个部分;否则,发送整个新的实体 | If-Range: "737060cd8c284d8af7ad3082f209582d" |
+| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
+| Origin | 发起一个针对跨来源资源共享的请求。 | `Origin: http://www.example-social-network.com` |
+| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生多种效果。 | Pragma: no-cache |
+| Proxy-Authorization | 用来向代理进行认证的认证信息。 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Range | 仅请求某个实体的一部分。字节偏移以 0 开始。参见字节服务。 | Range: bytes=500-999 |
+| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面。 | `Referer: http://en.wikipedia.org/wiki/Main_Page` |
+| TE | 浏览器预期接受的传输编码方式:可使用回应协议头 Transfer-Encoding 字段中的值; | TE: trailers, deflate |
+| Upgrade | 要求服务器升级到另一个协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
+| User-Agent | 浏览器的浏览器身份标识字符串 | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
+| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
+| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
+
+### ⭐️HTTP 和 HTTPS 有什么区别?(重要)
+
+
+
+- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
+- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
+- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
+- **SEO(搜索引擎优化)**:搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
+
+关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html) 。
+
+### HTTP/1.0 和 HTTP/1.1 有什么区别?
+
+
+
+- **连接方式**:HTTP/1.0 为短连接,HTTP/1.1 支持长连接。HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
+- **状态响应码**:HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
+- **缓存机制**:在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
+- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+- **Host 头(Host Header)处理**:HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
+
+关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html) 。
+
+### ⭐️HTTP/1.1 和 HTTP/2.0 有什么区别?
+
+
+
+- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
+- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
+- **队头阻塞**:HTTP/2 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 HTTP/1.1 应用层的队头阻塞问题,但 HTTP/2 依然受到 TCP 层队头阻塞 的影响。
+- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,使用了专门为`Header`压缩而设计的 HPACK 算法,减少了网络开销。
+- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
+
+HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://blog.cloudflare.com/http-2-for-web-developers/)):
+
+
+
+可以看到,HTTP/2 的多路复用机制允许多个请求和响应共享一个 TCP 连接,从而避免了 HTTP/1.1 在应对并发请求时需要建立多个并行连接的情况,减少了重复连接建立和维护的额外开销。而在 HTTP/1.1 中,尽管支持持久连接,但为了缓解队头阻塞问题,浏览器通常会为同一域名建立多个并行连接。
+
+### HTTP/2.0 和 HTTP/3.0 有什么区别?
+
+
+
+- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
+- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
+- **头部压缩**:HTTP/2.0 使用 HPACK 算法进行头部压缩,而 HTTP/3.0 使用更高效的 QPACK 头压缩算法。
+- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
+- **连接迁移**:HTTP/3.0 支持连接迁移,因为 QUIC 使用 64 位 ID 标识连接,只要 ID 不变就不会中断,网络环境改变时(如从 Wi-Fi 切换到移动数据)也能保持连接。而 TCP 连接是由(源 IP,源端口,目的 IP,目的端口)组成,这个四元组中一旦有一项值发生改变,这个连接也就不能用了。
+- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
+- **安全性**:在 HTTP/2.0 中,TLS 用于加密和认证整个 HTTP 会话,包括所有的 HTTP 头部和数据负载。TLS 的工作是在 TCP 层之上,它加密的是在 TCP 连接中传输的应用层的数据,并不会对 TCP 头部以及 TLS 记录层头部进行加密,所以在传输的过程中 TCP 头部可能会被攻击者篡改来干扰通信。而 HTTP/3.0 的 QUIC 对整个数据包(包括报文头和报文体)进行了加密与认证处理,保障安全性。
+
+HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
+
+
+
+下图是一个更详细的 HTTP/2.0 和 HTTP/3.0 对比图:
+
+
+
+从上图可以看出:
+
+- **HTTP/2.0**:使用 TCP 作为传输协议、使用 HPACK 进行头部压缩、依赖 TLS 进行加密。
+- **HTTP/3.0**:使用基于 UDP 的 QUIC 协议、使用更高效的 QPACK 进行头部压缩、在 QUIC 中直接集成了 TLS。QUIC 协议具备连接迁移、拥塞控制与避免、流量控制等特性。
+
+关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
+
+### HTTP/1.1 和 HTTP/2.0 的队头阻塞有什么不同?
+
+HTTP/1.1 队头阻塞的主要原因是无法多路复用:
+
+- 在一个 TCP 连接中,资源的请求和响应是按顺序处理的。如果一个大的资源(如一个大文件)正在传输,后续的小资源(如较小的 CSS 文件)需要等待前面的资源传输完成后才能被发送。
+- 如果浏览器需要同时加载多个资源(如多个 CSS、JS 文件等),它通常会开启多个并行的 TCP 连接(一般限制为 6 个)。但每个连接仍然受限于顺序的请求-响应机制,因此仍然会发生 **应用层的队头阻塞**。
+
+虽然 HTTP/2.0 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 **HTTP/1.1 应用层的队头阻塞问题**,但 HTTP/2.0 依然受到 **TCP 层队头阻塞** 的影响:
+
+- HTTP/2.0 通过帧(frame)机制将每个资源分割成小块,并为每个资源分配唯一的流 ID,这样多个资源的数据可以在同一 TCP 连接中交错传输。
+- TCP 作为传输层协议,要求数据按顺序交付。如果某个数据包在传输过程中丢失,即使后续的数据包已经到达,也必须等待丢失的数据包重传后才能继续处理。这种传输层的顺序性导致了 **TCP 层的队头阻塞**。
+- 举例来说,如果 HTTP/2 的一个 TCP 数据包中携带了多个资源的数据(例如 JS 和 CSS),而该数据包丢失了,那么后续数据包中的所有资源数据都需要等待丢失的数据包重传回来,导致所有流(streams)都被阻塞。
+
+最后,来一张表格总结补充一下:
+
+| **方面** | **HTTP/1.1 的队头阻塞** | **HTTP/2.0 的队头阻塞** |
+| -------------- | ---------------------------------------- | ---------------------------------------------------------------- |
+| **层级** | 应用层(HTTP 协议本身的限制) | 传输层(TCP 协议的限制) |
+| **根本原因** | 无法多路复用,请求和响应必须按顺序传输 | TCP 要求数据包按顺序交付,丢包时阻塞整个连接 |
+| **受影响范围** | 单个 HTTP 请求/响应会阻塞后续请求/响应。 | 单个 TCP 包丢失会影响所有 HTTP/2.0 流(依赖于同一个底层 TCP 连接) |
+| **缓解方法** | 开启多个并行的 TCP 连接 | 减少网络掉包或者使用基于 UDP 的 QUIC 协议 |
+| **影响场景** | 每次都会发生,尤其是大文件阻塞小文件时。 | 丢包率较高的网络环境下更容易发生。 |
+
+### ⭐️HTTP 是不保存状态的协议, 如何保存用户状态?
+
+HTTP 协议本身是 **无状态的 (stateless)** 。这意味着服务器默认情况下无法区分两个连续的请求是否来自同一个用户,或者同一个用户之前的操作是什么。这就像一个“健忘”的服务员,每次你跟他说话,他都不知道你是谁,也不知道你之前点过什么菜。
+
+但在实际的 Web 应用中,比如网上购物、用户登录等场景,我们显然需要记住用户的状态(例如购物车里的商品、用户的登录信息)。为了解决这个问题,主要有以下几种常用机制:
+
+**方案一:Session (会话) 配合 Cookie (主流方式):**
+
+
+
+这可以说是最经典也是最常用的方法了。基本流程是这样的:
+
+1. 用户向服务器发送用户名、密码、验证码用于登陆系统。
+2. 服务器验证通过后,会为这个用户创建一个专属的 Session 对象(可以理解为服务器上的一块内存,存放该用户的状态数据,如购物车、登录信息等)存储起来,并给这个 Session 分配一个唯一的 `SessionID`。
+3. 服务器通过 HTTP 响应头中的 `Set-Cookie` 指令,把这个 `SessionID` 发送给用户的浏览器。
+4. 浏览器接收到 `SessionID` 后,会将其以 Cookie 的形式保存在本地。当用户保持登录状态时,每次向该服务器发请求,浏览器都会自动带上这个存有 `SessionID` 的 Cookie。
+5. 服务器收到请求后,从 Cookie 中拿出 `SessionID`,就能找到之前保存的那个 Session 对象,从而知道这是哪个用户以及他之前的状态了。
+
+使用 Session 的时候需要注意下面几个点:
+
+- **客户端 Cookie 支持**:依赖 Session 的核心功能要确保用户浏览器开启了 Cookie。
+- **Session 过期管理**:合理设置 Session 的过期时间,平衡安全性和用户体验。
+- **Session ID 安全**:为包含 `SessionID` 的 Cookie 设置 `HttpOnly` 标志可以防止客户端脚本(如 JavaScript)窃取,设置 Secure 标志可以保证 `SessionID` 只在 HTTPS 连接下传输,增加安全性。
+
+Session 数据本身存储在服务器端。常见的存储方式有:
+
+- **服务器内存**:实现简单,访问速度快,但服务器重启数据会丢失,且不利于多服务器间的负载均衡。这种方式适合简单且用户量不大的业务场景。
+- **数据库 (如 MySQL, PostgreSQL)**:数据持久化,但读写性能相对较低,一般不会使用这种方式。
+- **分布式缓存 (如 Redis)**:性能高,支持分布式部署,是目前大规模应用中非常主流的方案。
+
+**方案二:当 Cookie 被禁用时:URL 重写 (URL Rewriting)**
+
+如果用户的浏览器禁用了 Cookie,或者某些情况下不便使用 Cookie,还有一种备选方案是 URL 重写。这种方式会将 `SessionID` 直接附加到 URL 的末尾,作为参数传递。例如:。服务器端会解析 URL 中的 `sessionid` 参数来获取 `SessionID`,进而找到对应的 Session 数据。
+
+这种方法一般不会使用,存在以下缺点:
+
+- URL 会变长且不美观;
+- `SessionID` 暴露在 URL 中,安全性较低(容易被复制、分享或记录在日志中);
+- 对搜索引擎优化 (SEO) 可能不友好。
+
+**方案三:Token-based 认证 (如 JWT - JSON Web Tokens)**
+
+这是一种越来越流行的无状态认证方式,尤其适用于前后端分离的架构和微服务。
+
+
+
+以 JWT 为例(普通 Token 方案也可以),简化后的步骤如下:
+
+1. 用户向服务器发送用户名、密码以及验证码用于登陆系统。
+2. 如果用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT。
+3. 客户端收到 Token 后自己保存起来(比如浏览器的 `localStorage`)。
+4. 用户以后每次向后端发请求都在 Header 中带上这个 JWT。
+5. 服务端检查 JWT 并从中获取用户相关信息。
+
+JWT 详细介绍可以查看这两篇文章:
+
+- [JWT 基础概念详解](https://javaguide.cn/system-design/security/jwt-intro.html)
+- [JWT 身份认证优缺点分析](https://javaguide.cn/system-design/security/advantages-and-disadvantages-of-jwt.html)
+
+总结来说,虽然 HTTP 本身是无状态的,但通过 Cookie + Session、URL 重写或 Token 等机制,我们能够有效地在 Web 应用中跟踪和管理用户状态。其中,**Cookie + Session 是最传统也最广泛使用的方式,而 Token-based 认证则在现代 Web 应用中越来越受欢迎。**
+
+### URI 和 URL 的区别是什么?
+
+- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
+- URL(Uniform Resource Locator) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
+
+URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL 是一种具体的 URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
+
+### Cookie 和 Session 有什么区别?
+
+准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](https://javaguide.cn/system-design/security/basis-of-authority-certification.html) 这篇文章中找到详细的答案。
+
+### ⭐️GET 和 POST 的区别
+
+这个问题在知乎上被讨论的挺火热的,地址: 。
+
+GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分二者(重点搞清两者在语义上的区别即可):
+
+- 语义(主要区别):GET 通常用于获取或查询资源,而 POST 通常用于创建或修改资源。
+- 幂等:GET 请求是幂等的,即多次重复执行不会改变资源的状态,而 POST 请求是不幂等的,即每次执行可能会产生不同的结果或影响资源的状态。
+- 格式:GET 请求的参数通常放在 URL 中,形成查询字符串(querystring),而 POST 请求的参数通常放在请求体(body)中,可以有多种编码格式,如 application/x-www-form-urlencoded、multipart/form-data、application/json 等。GET 请求的 URL 长度受到浏览器和服务器的限制,而 POST 请求的 body 大小则没有明确的限制。不过,实际上 GET 请求也可以用 body 传输数据,只是并不推荐这样做,因为这样可能会导致一些兼容性或者语义上的问题。
+- 缓存:由于 GET 请求是幂等的,它可以被浏览器或其他中间节点(如代理、网关)缓存起来,以提高性能和效率。而 POST 请求则不适合被缓存,因为它可能有副作用,每次执行可能需要实时的响应。
+- 安全性:GET 请求和 POST 请求如果使用 HTTP 协议的话,那都不安全,因为 HTTP 协议本身是明文传输的,必须使用 HTTPS 协议来加密传输数据。另外,GET 请求相比 POST 请求更容易泄露敏感数据,因为 GET 请求的参数通常放在 URL 中。
+
+再次提示,重点搞清两者在语义上的区别即可,实际使用过程中,也是通过语义来区分使用 GET 还是 POST。不过,也有一些项目所有的请求都用 POST,这个并不是固定的,项目组达成共识即可。
+
+## WebSocket
+
+### 什么是 WebSocket?
+
+WebSocket 是一种基于 TCP 连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据。
+
+WebSocket 协议在 2008 年诞生,2011 年成为国际标准,几乎所有主流较新版本的浏览器都支持该协议。不过,WebSocket 不只能在基于浏览器的应用程序中使用,很多编程语言、框架和服务器都提供了 WebSocket 支持。
+
+WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持久通信能力上的不足。客户端和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
+
+
+
+下面是 WebSocket 的常见应用场景:
+
+- 视频弹幕
+- 实时消息推送,详见[Web 实时消息推送详解](https://javaguide.cn/system-design/web-real-time-message-push.html)这篇文章
+- 实时游戏对战
+- 多用户协同编辑
+- 社交聊天
+- ……
+
+### ⭐️WebSocket 和 HTTP 有什么区别?
+
+WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网络中传输数据。
+
+下面是二者的主要区别:
+
+- WebSocket 是一种双向实时通信协议,而 HTTP 是一种单向通信协议。并且,HTTP 协议下的通信只能由客户端发起,服务器无法主动通知客户端。
+- WebSocket 使用 ws:// 或 wss://(使用 SSL/TLS 加密后的协议,类似于 HTTP 和 HTTPS 的关系) 作为协议前缀,HTTP 使用 http:// 或 https:// 作为协议前缀。
+- WebSocket 可以支持扩展,用户可以扩展协议,实现部分自定义的子协议,如支持压缩、加密等。
+- WebSocket 通信数据格式比较轻量,用于协议控制的数据包头部相对较小,网络开销小,而 HTTP 通信每次都要携带完整的头部,网络开销较大(HTTP/2.0 使用二进制帧进行数据传输,还支持头部压缩,减少了网络开销)。
+
+### WebSocket 的工作过程是什么样的?
+
+WebSocket 的工作过程可以分为以下几个步骤:
+
+1. 客户端向服务器发送一个 HTTP 请求,请求头中包含 `Upgrade: websocket` 和 `Sec-WebSocket-Key` 等字段,表示要求升级协议为 WebSocket;
+2. 服务器收到这个请求后,会进行升级协议的操作,如果支持 WebSocket,它将回复一个 HTTP 101 状态码,响应头中包含 `Connection: Upgrade` 和 `Sec-WebSocket-Accept: xxx` 等字段,表示成功升级到 WebSocket 协议。
+3. 客户端和服务器之间建立了一个 WebSocket 连接,可以进行双向的数据传输。数据以帧(frames)的形式进行传送,WebSocket 的每条消息可能会被切分成多个数据帧(最小单位)。发送端会将消息切割成多个帧发送给接收端,接收端接收消息帧,并将关联的帧重新组装成完整的消息。
+4. 客户端或服务器可以主动发送一个关闭帧,表示要断开连接。另一方收到后,也会回复一个关闭帧,然后双方关闭 TCP 连接。
+
+另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
+
+### ⭐️WebSocket 与短轮询、长轮询的区别
+
+这三种方式,都是为了解决“**客户端如何及时获取服务器最新数据,实现实时更新**”的问题。它们的实现方式和效率、实时性差异较大。
+
+**1.短轮询(Short Polling)**
+
+- **原理**:客户端每隔固定时间(如 5 秒)发起一次 HTTP 请求,询问服务器是否有新数据。服务器收到请求后立即响应。
+- **优点**:实现简单,兼容性好,直接用常规 HTTP 请求即可。
+- **缺点**:
+ - **实时性一般**:消息可能在两次轮询间到达,用户需等到下次请求才知晓。
+ - **资源浪费大**:反复建立/关闭连接,且大多数请求收到的都是“无新消息”,极大增加服务器和网络压力。
+
+**2.长轮询(Long Polling)**
+
+- **原理**:客户端发起请求后,若服务器暂时无新数据,则会保持连接,直到有新数据或超时才响应。客户端收到响应后立即发起下一次请求,实现“伪实时”。
+- **优点**:
+ - **实时性较好**:一旦有新数据可立即推送,无需等待下次定时请求。
+ - **空响应减少**:减少了无效的空响应,提升了效率。
+- **缺点**:
+ - **服务器资源占用高**:需长时间维护大量连接,消耗服务器线程/连接数。
+ - **资源浪费大**:每次响应后仍需重新建立连接,且依然基于 HTTP 单向请求-响应机制。
+
+**3. WebSocket**
+
+- **原理**:客户端与服务器通过一次 HTTP Upgrade 握手后,建立一条持久的 TCP 连接。之后,双方可以随时、主动地发送数据,实现真正的全双工、低延迟通信。
+- **优点**:
+ - **实时性强**:数据可即时双向收发,延迟极低。
+ - **资源效率高**:连接持续,无需反复建立/关闭,减少资源消耗。
+ - **功能强大**:支持服务端主动推送消息、客户端主动发起通信。
+- **缺点**:
+ - **使用限制**:需要服务器和客户端都支持 WebSocket 协议。对连接管理有一定要求(如心跳保活、断线重连等)。
+ - **实现麻烦**:实现起来比短轮询和长轮询要更麻烦一些。
+
+
+
+### ⭐️SSE 与 WebSocket 有什么区别?
+
+SSE (Server-Sent Events) 和 WebSocket 都是用来实现服务器向浏览器实时推送消息的技术,让网页内容能自动更新,而不需要用户手动刷新。虽然目标相似,但它们在工作方式和适用场景上有几个关键区别:
+
+1. **通信方式:**
+ - **SSE:** **单向通信**。只有服务器能向客户端(浏览器)发送数据。客户端不能通过同一个连接向服务器发送数据(需要发起新的 HTTP 请求)。
+ - **WebSocket:** **双向通信 (全双工)**。客户端和服务器可以随时互相发送消息,实现真正的实时交互。
+2. **底层协议:**
+ - **SSE:** 基于**标准的 HTTP/HTTPS 协议**。它本质上是一个“长连接”的 HTTP 请求,服务器保持连接打开并持续发送事件流。不需要特殊的服务器或协议支持,现有的 HTTP 基础设施就能用。
+ - **WebSocket:** 使用**独立的 ws:// 或 wss:// 协议**。它需要通过一个特定的 HTTP "Upgrade" 请求来建立连接,并且服务器需要明确支持 WebSocket 协议来处理连接和消息帧。
+3. **实现复杂度和成本:**
+ - **SSE:** **实现相对简单**,主要在服务器端处理。浏览器端有标准的 EventSource API,使用方便。开发和维护成本较低。
+ - **WebSocket:** **稍微复杂一些**。需要服务器端专门处理 WebSocket 连接和协议,客户端也需要使用 WebSocket API。如果需要考虑兼容性、心跳、重连等,开发成本会更高。
+4. **断线重连:**
+ - **SSE:** **浏览器原生支持**。EventSource API 提供了自动断线重连的机制。
+ - **WebSocket:** **需要手动实现**。开发者需要自己编写逻辑来检测断线并进行重连尝试。
+5. **数据类型:**
+ - **SSE:** **主要设计用来传输文本** (UTF-8 编码)。如果需要传输二进制数据,需要先进行 Base64 等编码转换成文本。
+ - **WebSocket:** **原生支持传输文本和二进制数据**,无需额外编码。
+
+为了提供更好的用户体验和利用其简单、高效、基于标准 HTTP 的特性,**Server-Sent Events (SSE) 是目前大型语言模型 API(如 OpenAI、DeepSeek 等)实现流式响应的常用甚至可以说是标准的技术选择**。
+
+这里以 DeepSeek 为例,我们发送一个请求并打开浏览器控制台验证一下:
+
+
+
+
+
+可以看到,响应头里包含了 `text/event-stream`,说明使用的确实是 SSE。并且,响应数据也确实是持续分块传输。
+
+## PING
+
+### PING 命令的作用是什么?
+
+PING 命令是一种常用的网络诊断工具,经常用来测试网络中主机之间的连通性和网络延迟。
+
+这里简单举一个例子,我们来 PING 一下百度。
+
+```bash
+# 发送4个PING请求数据包到 www.baidu.com
+❯ ping -c 4 www.baidu.com
+
+PING www.a.shifen.com (14.119.104.189): 56 data bytes
+64 bytes from 14.119.104.189: icmp_seq=0 ttl=54 time=27.867 ms
+64 bytes from 14.119.104.189: icmp_seq=1 ttl=54 time=28.732 ms
+64 bytes from 14.119.104.189: icmp_seq=2 ttl=54 time=27.571 ms
+64 bytes from 14.119.104.189: icmp_seq=3 ttl=54 time=27.581 ms
+
+--- www.a.shifen.com ping statistics ---
+4 packets transmitted, 4 packets received, 0.0% packet loss
+round-trip min/avg/max/stddev = 27.571/27.938/28.732/0.474 ms
+```
+
+PING 命令的输出结果通常包括以下几部分信息:
+
+1. **ICMP Echo Request(请求报文)信息**:序列号、TTL(Time to Live)值。
+2. **目标主机的域名或 IP 地址**:输出结果的第一行。
+3. **往返时间(RTT,Round-Trip Time)**:从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
+4. **统计结果(Statistics)**:包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
+
+如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题(有些主机或网络管理员可能禁用了对 ICMP 请求的回复,这样也会导致无法得到正确的响应)。如果往返时间(RTT)过高,则表明网络延迟过高。
+
+### PING 命令的工作原理是什么?
+
+PING 基于网络层的 **ICMP(Internet Control Message Protocol,互联网控制报文协议)**,其主要原理就是通过在网络上发送和接收 ICMP 报文实现的。
+
+ICMP 报文中包含了类型字段,用于标识 ICMP 报文类型。ICMP 报文的类型有很多种,但大致可以分为两类:
+
+- **查询报文类型**:向目标主机发送请求并期望得到响应。
+- **差错报文类型**:向源主机发送错误信息,用于报告网络中的错误情况。
+
+PING 用到的 ICMP Echo Request(类型为 8 ) 和 ICMP Echo Reply(类型为 0) 属于查询报文类型 。
+
+- PING 命令会向目标主机发送 ICMP Echo Request。
+- 如果两个主机的连通性正常,目标主机会返回一个对应的 ICMP Echo Reply。
+
+## DNS
+
+### DNS 的作用是什么?
+
+DNS(Domain Name System)域名管理系统,是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是**域名和 IP 地址的映射问题**。
+
+
+
+在一台电脑上,可能存在浏览器 DNS 缓存,操作系统 DNS 缓存,路由器 DNS 缓存。如果以上缓存都查询不到,那么 DNS 就闪亮登场了。
+
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53** 。
+
+### DNS 服务器有哪些?根服务器有多少个?
+
+DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
+
+- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
+- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如`com`、`org`、`net`和`edu`等。国家也有自己的顶级域,如`uk`、`fr`和`ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
+- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
+- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构
+
+世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 1700 多台,未来还会继续增加。
+
+### ⭐️DNS 解析的过程是什么样的?
+
+整个过程的步骤比较多,我单独写了一篇文章详细介绍:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html) 。
+
+### DNS 劫持了解吗?如何应对?
+
+DNS 劫持是一种网络攻击,它通过修改 DNS 服务器的解析结果,使用户访问的域名指向错误的 IP 地址,从而导致用户无法访问正常的网站,或者被引导到恶意的网站。DNS 劫持有时也被称为 DNS 重定向、DNS 欺骗或 DNS 污染。
+
+## 参考
+
+- 《图解 HTTP》
+- 《计算机网络自顶向下方法》(第七版)
+- 详解 HTTP/2.0 及 HTTPS 协议:
+- HTTP 请求头字段大全| HTTP Request Headers:
+- HTTP1、HTTP2、HTTP3:
+- 如何看待 HTTP/3 ? - 车小胖的回答 - 知乎:
+
+
diff --git a/docs/cs-basics/network/other-network-questions2.md b/docs/cs-basics/network/other-network-questions2.md
new file mode 100644
index 00000000000..e98ece86cde
--- /dev/null
+++ b/docs/cs-basics/network/other-network-questions2.md
@@ -0,0 +1,276 @@
+---
+title: 计算机网络常见面试题总结(下)
+description: 最新计算机网络高频面试题总结(下):TCP/UDP深度对比、三次握手四次挥手、HTTP/3 QUIC优化、IPv6优势、NAT/ARP详解,附表格+⭐️重点标注,一文掌握传输层&网络层核心考点,快速通关后端技术面试!
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP vs UDP,TCP三次握手,HTTP/3 QUIC,IPv4 vs IPv6,TCP可靠性,IP地址,NAT协议,ARP协议,传输层面试,网络层高频题,基于TCP协议,基于UDP协议,队头阻塞,四次挥手
+---
+
+
+
+计算机网络面试题里,真正容易被追问到细节的部分,往往集中在 **TCP、UDP、IP、ARP、NAT、IPv4/IPv6** 这些传输层和网络层知识点上。比如:为什么 TCP 可靠?为什么要三次握手和四次挥手?HTTP/3 为什么改用基于 UDP 的 QUIC?这些问题不仅考概念,也考你对网络通信过程的理解。
+
+这篇《计算机网络常见面试题总结(下)》会重点梳理 TCP 与 UDP、TCP 连接管理、可靠传输、IP 地址、ARP、NAT 等后端面试高频内容,帮助你把传输层和网络层的核心考点串起来。
+
+## TCP 与 UDP
+
+### ⭐️TCP 与 UDP 的区别(重要)
+
+1. **是否面向连接**:
+ - TCP 是面向连接的。在传输数据之前,必须先通过“三次握手”建立连接;数据传输完成后,还需要通过“四次挥手”来释放连接。这保证了双方都准备好通信。
+ - UDP 是无连接的。发送数据前不需要建立任何连接,直接把数据包(数据报)扔出去。
+2. **是否是可靠传输**:
+ - TCP 提供可靠的数据传输服务。它通过序列号、确认应答 (ACK)、超时重传、流量控制、拥塞控制等一系列机制,来确保数据能够无差错、不丢失、不重复且按顺序地到达目的地。
+ - UDP 提供不可靠的传输。它尽最大努力交付 (best-effort delivery),但不保证数据一定能到达,也不保证到达的顺序,更不会自动重传。收到报文后,接收方也不会主动发确认。
+3. **是否有状态**:
+ - TCP 是有状态的。因为要保证可靠性,TCP 需要在连接的两端维护连接状态信息,比如序列号、窗口大小、哪些数据发出去了、哪些收到了确认等。
+ - UDP 是无状态的。它不维护连接状态,发送方发出数据后就不再关心它是否到达以及如何到达,因此开销更小(**这很“渣男”!**)。
+4. **传输效率**:
+ - TCP 因为需要建立连接、发送确认、处理重传等,其开销较大,传输效率相对较低。
+ - UDP 结构简单,没有复杂的控制机制,开销小,传输效率更高,速度更快。
+5. **传输形式**:
+ - TCP 是面向字节流 (Byte Stream) 的。它将应用程序交付的数据视为一连串无结构的字节流,可能会对数据进行拆分或合并。
+ - UDP 是面向报文 (Message Oriented) 的。应用程序交给 UDP 多大的数据块,UDP 就照样发送,既不拆分也不合并,保留了应用程序消息的边界。
+6. **首部开销**:
+ - TCP 的头部至少需要 20 字节,如果包含选项字段,最多可达 60 字节。
+ - UDP 的头部非常简单,固定只有 8 字节。
+7. **是否提供广播或多播服务**:
+ - TCP 只支持点对点 (Point-to-Point) 的单播通信。
+ - UDP 支持一对一 (单播)、一对多 (多播/Multicast) 和一对所有 (广播/Broadcast) 的通信方式。
+8. ……
+
+为了更直观地对比,可以看下面这个表格:
+
+| 特性 | TCP | UDP |
+| ------------ | -------------------------- | ----------------------------------- |
+| **连接性** | 面向连接 | 无连接 |
+| **可靠性** | 可靠 | 不可靠 (尽力而为) |
+| **状态维护** | 有状态 | 无状态 |
+| **传输效率** | 较低 | 较高 |
+| **传输形式** | 面向字节流 | 面向数据报 (报文) |
+| **头部开销** | 20 - 60 字节 | 8 字节 |
+| **通信模式** | 点对点 (单播) | 单播、多播、广播 |
+| **常见应用** | HTTP/HTTPS, FTP, SMTP, SSH | DNS, DHCP, SNMP, TFTP, VoIP, 视频流 |
+
+### ⭐️什么时候选择 TCP,什么时候选 UDP?
+
+选择 TCP 还是 UDP,主要取决于你的应用**对数据传输的可靠性要求有多高,以及对实时性和效率的要求有多高**。
+
+当**数据准确性和完整性至关重要,一点都不能出错**时,通常选择 TCP。因为 TCP 提供了一整套机制(三次握手、确认应答、重传、流量控制等)来保证数据能够可靠、有序地送达。典型应用场景如下:
+
+- **Web 浏览 (HTTP/HTTPS):** 网页内容、图片、脚本必须完整加载才能正确显示。
+- **文件传输 (FTP, SCP):** 文件内容不允许有任何字节丢失或错序。
+- **邮件收发 (SMTP, POP3, IMAP):** 邮件内容需要完整无误地送达。
+- **远程登录 (SSH, Telnet):** 命令和响应需要准确传输。
+- ……
+
+当**实时性、速度和效率优先,并且应用能容忍少量数据丢失或乱序**时,通常选择 UDP。UDP 开销小、传输快,没有建立连接和保证可靠性的复杂过程。典型应用场景如下:
+
+- **实时音视频通信 (VoIP, 视频会议, 直播):** 偶尔丢失一两个数据包(可能导致画面或声音短暂卡顿)通常比因为等待重传(TCP 机制)导致长时间延迟更可接受。应用层可能会有自己的补偿机制。
+- **在线游戏:** 需要快速传输玩家位置、状态等信息,对实时性要求极高,旧的数据很快就没用了,丢失少量数据影响通常不大。
+- **DHCP (动态主机配置协议):** 客户端在请求 IP 时自身没有 IP 地址,无法满足 TCP 建立连接的前提条件,并且 DHCP 有广播需求、交互模式简单以及自带可靠性机制。
+- **物联网 (IoT) 数据上报:** 某些场景下,传感器定期上报数据,丢失个别数据点可能不影响整体趋势分析。
+- ……
+
+### HTTP 基于 TCP 还是 UDP?
+
+~~**HTTP 协议是基于 TCP 协议的**,所以发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。~~
+
+🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):
+
+HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** :
+
+- **HTTP/1.x 和 HTTP/2.0**:这两个版本的 HTTP 协议都明确建立在 TCP 之上。TCP 提供了可靠的、面向连接的传输,确保数据按序、无差错地到达,这对于网页内容的正确展示非常重要。发送 HTTP 请求前,需要先通过 TCP 的三次握手建立连接。
+- **HTTP/3.0**:这是一个重大的改变。HTTP/3 弃用了 TCP,转而使用 QUIC 协议,而 QUIC 是构建在 UDP 之上的。
+
+
+
+**为什么 HTTP/3 要做这个改变呢?主要有两大原因:**
+
+1. 解决队头阻塞 (Head-of-Line Blocking,简写:HOL blocking) 问题。
+2. 减少连接建立的延迟。
+
+下面我们来详细介绍这两大优化。
+
+在 HTTP/2 中,虽然可以在一个 TCP 连接上并发传输多个请求/响应流(多路复用),但 TCP 本身的特性(保证有序、可靠)意味着如果其中一个流的某个 TCP 报文丢失或延迟,整个 TCP 连接都会被阻塞,等待该报文重传。这会导致所有在这个 TCP 连接上的 HTTP/2 流都受到影响,即使其他流的数据包已经到达。**QUIC (运行在 UDP 上) 解决了这个问题**。QUIC 内部实现了自己的多路复用和流控制机制。不同的 HTTP 请求/响应流在 QUIC 层面是真正独立的。如果一个流的数据包丢失,它只会阻塞该流,而不会影响同一 QUIC 连接上的其他流(本质上是多路复用+轮询),大大提高了并发传输的效率。
+
+除了解决队头阻塞问题,HTTP/3.0 还可以减少握手过程的延迟。在 HTTP/2.0 中,如果要建立一个安全的 HTTPS 连接,需要经过 TCP 三次握手和 TLS 握手:
+
+1. TCP 三次握手:客户端和服务器交换 SYN 和 ACK 包,建立一个 TCP 连接。这个过程需要 1.5 个 RTT(round-trip time),即一个数据包从发送到接收的时间。
+2. TLS 握手:客户端和服务器交换密钥和证书,建立一个 TLS 加密层。这个过程需要至少 1 个 RTT(TLS 1.3)或者 2 个 RTT(TLS 1.2)。
+
+所以,HTTP/2.0 的连接建立就至少需要 2.5 个 RTT(TLS 1.3)或者 3.5 个 RTT(TLS 1.2)。而在 HTTP/3.0 中,使用的 QUIC 协议(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
+
+相关证明可以参考下面这两个链接:
+
+-
+-
+
+### 你知道哪些基于 TCP/UDP 的协议?
+
+TCP (传输控制协议) 和 UDP (用户数据报协议) 是互联网传输层的两大核心协议,它们为各种应用层协议提供了基础的通信服务。以下是一些常见的、分别构建在 TCP 和 UDP 之上的应用层协议:
+
+**运行于 TCP 协议之上的协议 (强调可靠、有序传输):**
+
+| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
+| -------------------------- | ---------------------------------- | ---------------------------- | --------------------------------------------------------------------------------------------------------------------------- |
+| 超文本传输协议 (HTTP) | HyperText Transfer Protocol | 传输网页、超文本、多媒体内容 | **HTTP/1.x 和 HTTP/2 基于 TCP**。早期版本不加密,是 Web 通信的基础。 |
+| 安全超文本传输协议 (HTTPS) | HyperText Transfer Protocol Secure | 加密的网页传输 | 在 HTTP 和 TCP 之间增加了 SSL/TLS 加密层,确保数据传输的机密性和完整性。 |
+| 文件传输协议 (FTP) | File Transfer Protocol | 文件传输 | 传统的 FTP **明文传输**,不安全。推荐使用其安全版本 **SFTP (SSH File Transfer Protocol)** 或 **FTPS (FTP over SSL/TLS)** 。 |
+| 简单邮件传输协议 (SMTP) | Simple Mail Transfer Protocol | **发送**电子邮件 | 负责将邮件从客户端发送到服务器,或在邮件服务器之间传递。可通过 **STARTTLS** 升级到加密传输。 |
+| 邮局协议第 3 版 (POP3) | Post Office Protocol version 3 | **接收**电子邮件 | 通常将邮件从服务器**下载到本地设备后删除服务器副本** (可配置保留)。**POP3S** 是其 SSL/TLS 加密版本。 |
+| 互联网消息访问协议 (IMAP) | Internet Message Access Protocol | **接收和管理**电子邮件 | 邮件保留在服务器,支持多设备同步邮件状态、文件夹管理、在线搜索等。**IMAPS** 是其 SSL/TLS 加密版本。现代邮件服务首选。 |
+| 远程终端协议 (Telnet) | Teletype Network | 远程终端登录 | **明文传输**所有数据 (包括密码),安全性极差,基本已被 SSH 完全替代。 |
+| 安全外壳协议 (SSH) | Secure Shell | 安全远程管理、加密数据传输 | 提供了加密的远程登录和命令执行,以及安全的文件传输 (SFTP) 等功能,是 Telnet 的安全替代品。 |
+
+**运行于 UDP 协议之上的协议 (强调快速、低开销传输):**
+
+| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
+| ----------------------- | ------------------------------------- | -------------------------- | ------------------------------------------------------------------------------------------------------------ |
+| 超文本传输协议 (HTTP/3) | HyperText Transfer Protocol version 3 | 新一代网页传输 | 基于 **QUIC** 协议 (QUIC 本身构建于 UDP 之上),旨在减少延迟、解决 TCP 队头阻塞问题,支持 0-RTT 连接建立。 |
+| 动态主机配置协议 (DHCP) | Dynamic Host Configuration Protocol | 动态分配 IP 地址及网络配置 | 客户端从服务器自动获取 IP 地址、子网掩码、网关、DNS 服务器等信息。 |
+| 域名系统 (DNS) | Domain Name System | 域名到 IP 地址的解析 | **通常使用 UDP** 进行快速查询。当响应数据包过大或进行区域传送 (AXFR) 时,会**切换到 TCP** 以保证数据完整性。 |
+| 实时传输协议 (RTP) | Real-time Transport Protocol | 实时音视频数据流传输 | 常用于 VoIP、视频会议、直播等。追求低延迟,允许少量丢包。通常与 RTCP 配合使用。 |
+| RTP 控制协议 (RTCP) | RTP Control Protocol | RTP 流的质量监控和控制信息 | 配合 RTP 工作,提供丢包、延迟、抖动等统计信息,辅助流量控制和拥塞管理。 |
+| 简单文件传输协议 (TFTP) | Trivial File Transfer Protocol | 简化的文件传输 | 功能简单,常用于局域网内无盘工作站启动、网络设备固件升级等小文件传输场景。 |
+| 简单网络管理协议 (SNMP) | Simple Network Management Protocol | 网络设备的监控与管理 | 允许网络管理员查询和修改网络设备的状态信息。 |
+| 网络时间协议 (NTP) | Network Time Protocol | 同步计算机时钟 | 用于在网络中的计算机之间同步时间,确保时间的一致性。 |
+
+**总结一下:**
+
+- **TCP** 更适合那些对数据**可靠性、完整性和顺序性**要求高的应用,如网页浏览 (HTTP/HTTPS)、文件传输 (FTP/SFTP)、邮件收发 (SMTP/POP3/IMAP)。
+- **UDP** 则更适用于那些对**实时性要求高、能容忍少量数据丢失**的应用,如域名解析 (DNS)、实时音视频 (RTP)、在线游戏、网络管理 (SNMP) 等。
+
+### ⭐️TCP 三次握手和四次挥手(非常重要)
+
+**相关面试题**:
+
+- 为什么要三次握手?
+- 第 2 次握手传回了 ACK,为什么还要传回 SYN?
+- 为什么要四次挥手?
+- 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
+- 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
+- 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
+
+**参考答案**:[TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html) 。
+
+### ⭐️TCP 如何保证传输的可靠性?(重要)
+
+[TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
+
+## IP
+
+### IP 协议的作用是什么?
+
+**IP(Internet Protocol,网际协议)** 是 TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。
+
+目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+
+### 什么是 IP 地址?IP 寻址如何工作?
+
+每个连入互联网的设备或域(如计算机、服务器、路由器等)都被分配一个 **IP 地址(Internet Protocol address)**,作为唯一标识符。每个 IP 地址都是一个字符序列,如 192.168.1.1(IPv4)、2001:0db8:85a3:0000:0000:8a2e:0370:7334(IPv6) 。
+
+当网络设备发送 IP 数据包时,数据包中包含了 **源 IP 地址** 和 **目的 IP 地址** 。源 IP 地址用于标识数据包的发送方设备或域,而目的 IP 地址则用于标识数据包的接收方设备或域。这类似于一封邮件中同时包含了目的地地址和回邮地址。
+
+网络设备根据目的 IP 地址来判断数据包的目的地,并将数据包转发到正确的目的地网络或子网络,从而实现了设备间的通信。
+
+这种基于 IP 地址的寻址方式是互联网通信的基础,它允许数据包在不同的网络之间传递,从而实现了全球范围内的网络互联互通。IP 地址的唯一性和全局性保证了网络中的每个设备都可以通过其独特的 IP 地址进行标识和寻址。
+
+
+
+### 什么是 IP 地址过滤?
+
+**IP 地址过滤(IP Address Filtering)** 简单来说就是限制或阻止特定 IP 地址或 IP 地址范围的访问。例如,你有一个图片服务突然被某一个 IP 地址攻击,那我们就可以禁止这个 IP 地址访问图片服务。
+
+IP 地址过滤是一种简单的网络安全措施,实际应用中一般会结合其他网络安全措施,如认证、授权、加密等一起使用。单独使用 IP 地址过滤并不能完全保证网络的安全。
+
+### ⭐️IPv4 和 IPv6 有什么区别?
+
+**IPv4(Internet Protocol version 4)** 是目前广泛使用的 IP 地址版本,其格式是四组由点分隔的数字,例如:123.89.46.72。IPv4 使用 32 位地址作为其 Internet 地址,这意味着共有约 42 亿( 2^32)个可用 IP 地址。
+
+
+
+这么少当然不够用啦!为了解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议 - **IPv6(Internet Protocol version 6)**。IPv6 地址使用更复杂的格式,该格式使用由单或双冒号分隔的一组数字和字母,例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334 。IPv6 使用 128 位互联网地址,这意味着越有 2^128(3 开头的 39 位数字,恐怖如斯) 个可用 IP 地址。
+
+
+
+除了更大的地址空间之外,IPv6 的优势还包括:
+
+- **无状态地址自动配置(Stateless Address Autoconfiguration,简称 SLAAC)**:主机可以直接通过根据接口标识和网络前缀生成全局唯一的 IPv6 地址,而无需依赖 DHCP(Dynamic Host Configuration Protocol)服务器,简化了网络配置和管理。
+- **NAT(Network Address Translation,网络地址转换) 成为可选项**:IPv6 地址资源充足,可以给全球每个设备一个独立的地址。
+- **对标头结构进行了改进**:IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
+- **可选的扩展头**:允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
+- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
+- ……
+
+### 如何获取客户端真实 IP?
+
+获取客户端真实 IP 的方法有多种,主要分为应用层方法、传输层方法和网络层方法。
+
+**应用层方法**:
+
+通过 [X-Forwarded-For](https://en.wikipedia.org/wiki/X-Forwarded-For) 请求头获取,简单方便。不过,这种方法无法保证获取到的是真实 IP,这是因为 X-Forwarded-For 字段可能会被伪造。如果经过多个代理服务器,X-Forwarded-For 字段可能会有多个值(附带了整个请求链中的所有代理服务器 IP 地址)。并且,这种方法只适用于 HTTP 和 SMTP 协议。
+
+**传输层方法**:
+
+利用 TCP Options 字段承载真实源 IP 信息。这种方法适用于任何基于 TCP 的协议,不受应用层的限制。不过,这并非是 TCP 标准所支持的,所以需要通信双方都进行改造。也就是:对于发送方来说,需要有能力把真实源 IP 插入到 TCP Options 里面。对于接收方来说,需要有能力把 TCP Options 里面的 IP 地址读取出来。
+
+也可以通过 Proxy Protocol 协议来传递客户端 IP 和 Port 信息。这种方法可以利用 Nginx 或者其他支持该协议的反向代理服务器来获取真实 IP 或者在业务服务器解析真实 IP。
+
+**网络层方法**:
+
+隧道 + DSR 模式。这种方法可以适用于任何协议,就是实施起来会比较麻烦,也存在一定限制,实际应用中一般不会使用这种方法。
+
+### NAT 的作用是什么?
+
+**NAT(Network Address Translation,网络地址转换)** 主要用于在不同网络之间转换 IP 地址。它允许将私有 IP 地址(如在局域网中使用的 IP 地址)映射为公有 IP 地址(在互联网中使用的 IP 地址)或者反向映射,从而实现局域网内的多个设备通过单一公有 IP 地址访问互联网。
+
+NAT 不光可以缓解 IPv4 地址资源短缺的问题,还可以隐藏内部网络的实际拓扑结构,使得外部网络无法直接访问内部网络中的设备,从而提高了内部网络的安全性。
+
+
+
+相关阅读:[NAT 协议详解(网络层)](https://javaguide.cn/cs-basics/network/nat.html)。
+
+## ARP
+
+### 什么是 Mac 地址?
+
+MAC 地址的全称是 **媒体访问控制地址(Media Access Control Address)**。如果说,互联网中每一个资源都由 IP 地址唯一标识(IP 协议内容),那么一切网络设备都由 MAC 地址唯一标识。
+
+
+
+可以理解为,MAC 地址是一个网络设备真正的身份证号,IP 地址只是一种不重复的定位方式(比如说住在某省某市某街道的张三,这种逻辑定位是 IP 地址,他的身份证号才是他的 MAC 地址),也可以理解为 MAC 地址是身份证号,IP 地址是邮政地址。MAC 地址也有一些别称,如 LAN 地址、物理地址、以太网地址等。
+
+> 还有一点要知道的是,不仅仅是网络资源才有 IP 地址,网络设备也有 IP 地址,比如路由器。但从结构上说,路由器等网络设备的作用是组成一个网络,而且通常是内网,所以它们使用的 IP 地址通常是内网 IP,内网的设备在与内网以外的设备进行通信时,需要用到 NAT 协议。
+
+MAC 地址的长度为 6 字节(48 比特),地址空间大小有 280 万亿之多( $2^{48}$ ),MAC 地址由 IEEE 统一管理与分配,理论上,一个网络设备中的网卡上的 MAC 地址是永久的。不同的网卡生产商从 IEEE 那里购买自己的 MAC 地址空间(MAC 的前 24 比特),也就是前 24 比特由 IEEE 统一管理,保证不会重复。而后 24 比特,由各家生产商自己管理,同样保证生产的两块网卡的 MAC 地址不会重复。
+
+MAC 地址具有可携带性、永久性,身份证号永久地标识一个人的身份,不论他到哪里都不会改变。而 IP 地址不具有这些性质,当一台设备更换了网络,它的 IP 地址也就可能发生改变,也就是它在互联网中的定位发生了变化。
+
+最后,记住,MAC 地址有一个特殊地址:FF-FF-FF-FF-FF-FF(全 1 地址),该地址表示广播地址。
+
+### ⭐️ARP 协议解决了什么问题?
+
+ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
+
+### ARP 协议的工作原理?
+
+[ARP 协议详解(网络层)](https://javaguide.cn/cs-basics/network/arp.html)
+
+## 复习建议
+
+非常推荐大家看一下 《图解 HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
+
+## 参考
+
+- 《图解 HTTP》
+- 《计算机网络自顶向下方法》(第七版)
+- 什么是 Internet 协议(IP)?:
+- 透传真实源 IP 的各种方法 - 极客时间:
+- What Is NAT and What Are the Benefits of NAT Firewalls?:
+
+
diff --git a/docs/cs-basics/network/tcp-byte-stream-udp-datagram.md b/docs/cs-basics/network/tcp-byte-stream-udp-datagram.md
new file mode 100644
index 00000000000..e3e9fa99205
--- /dev/null
+++ b/docs/cs-basics/network/tcp-byte-stream-udp-datagram.md
@@ -0,0 +1,162 @@
+---
+title: 为什么 TCP 是面向字节流,UDP 是面向报文?(传输层)
+description: 讲清 TCP 字节流与 UDP 报文的本质差异,解析粘包/拆包成因与解决方案,覆盖 Nagle、Delayed ACK 等常见面试考点。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,UDP,字节流,报文,粘包,拆包,消息边界,Nagle,Delayed ACK,TCP_NODELAY
+---
+
+前面说 TCP 是面向字节流,UDP 是面向报文。这个点看起来像一句定义,但很多粘包、拆包问题,其实都藏在这里。
+
+先说结论:**TCP 只保证字节可靠、有序地到达,不保证应用层消息边界;UDP 会保留应用层交给它的报文边界。**
+
+这篇文章主要回答几个问题:
+
+1. 为什么说 TCP 是面向字节流,UDP 是面向报文?
+2. TCP 粘包、拆包到底是怎么产生的?
+3. 应用层应该如何定义消息边界?
+4. Nagle 算法和 Delayed ACK 为什么可能让小包变慢?
+
+举个例子,应用层连续发送两条消息:
+
+```
+消息 1:hello
+消息 2:world
+```
+
+如果用 UDP 发送,通常会对应两个 UDP 数据报。接收方调用 `recvfrom()` 时,也是按数据报来读:一次读取一个 UDP 报文,不会把两次发送的报文合成一个流。UDP 的接收队列里,一个元素就是一个数据报,消息边界天然保留了下来。
+
+不过这里也有一个细节:UDP 保留的是传输层报文边界,不代表它适合发送任意大的消息。数据报太大时,底层 IP 层仍可能分片;接收端缓冲区太小时,也可能出现截断。所以 UDP 的“面向报文”不是“随便发多大都没事”,而是说它不会像 TCP 那样把应用数据抽象成一条连续字节流。RFC 768 对 UDP 的定义就是 datagram mode,并说明它提供的是最小协议机制,不保证可靠交付和去重。
+
+如果用 TCP 发送,就不能这么理解。应用层调用两次 `send()`,只是把两段字节写进内核发送缓冲区。至于这些字节什么时候发、合成几个 TCP 段发、对端一次 `recv()` 能读到多少,都不是由这两次 `send()` 直接决定的。
+
+比如,接收端可能一次读到(粘包):
+
+```
+helloworld
+```
+
+也可能分几次读到(拆包):
+
+```
+hel
+lowor
+ld
+```
+
+这不是 TCP 出错,而是 TCP 的工作方式本来就是这样。TCP 处理的是连续字节流,它只关心这些字节是否可靠、有序地到达,不关心应用层定义的“第几条消息”从哪里开始、到哪里结束。RFC 9293 也明确提到,TCP segment 和应用层 `send()` / socket write 的边界通常不是一一对应的,TCP 不保证应用读写缓冲区边界和网络分段边界相关。
+
+
+
+所以,“TCP 粘包/拆包”这个说法更像是应用层视角下的现象。严格来说,TCP 没有“包”的概念,它传的是连续字节流。真正需要解决的是:**应用层协议如何定义消息边界**。
+
+#### 为什么会出现粘包和拆包?
+
+常见原因有这几个。
+
+**1. TCP 是字节流协议,没有应用层消息边界。**
+
+TCP 负责把字节可靠、有序地送到对端,但不会记录“这 20 个字节是第一条消息,那 30 个字节是第二条消息”。
+
+**2. 一次 `send()` 不等于一次网络发送。**
+
+`send()` 成功通常只表示数据从应用进程拷贝到了内核发送缓冲区。至于什么时候真正发出去、拆成几个 TCP 段发,要看 MSS、发送窗口、拥塞窗口、Nagle 算法、网卡队列等因素。
+
+**3. 一次 `recv()` 也不等于读到一条完整消息。**
+
+接收端只是从 TCP 接收缓冲区取字节。缓冲区里可能已经堆了多条消息,也可能只有半条消息。`recv()` 只会把当前可读的数据拷贝给应用,不会帮你按业务消息切分。
+
+**4. 小包优化可能改变发送时机。**
+
+Nagle 算法、Delayed ACK、Linux 自动合并小写入等机制,都可能影响小数据的发送时机。比如 Linux 从 3.14 开始有 `tcp_autocorking`,内核会尽量合并连续的小写入,减少发送包数量;应用也可以用 `TCP_CORK` 明确控制何时“拔塞”发送。
+
+这也是为什么在 Netty、Dubbo、自定义 RPC、IM 网关、游戏服务里,协议编解码都很重要。只要底层用的是 TCP,就必须在应用层定义清楚消息边界。
+
+
+
+#### 怎么解决 TCP 粘包/拆包?
+
+核心思路只有一个:**让接收方知道一条消息到哪里结束。**
+
+
+
+常见做法有三种。
+
+**1. 固定长度**
+
+规定每条消息都是固定长度,比如 64 字节。接收方每读满 64 字节,就认为读到了一条完整消息。
+
+这种方式实现简单,但灵活性差。消息短了要补齐,浪费空间;消息长了又要额外拆分。它适合消息格式非常固定的场景,不太适合通用业务协议。
+
+**2. 分隔符**
+
+在消息之间加特殊分隔符,比如换行符 `\n`、`\r\n`,或者自定义结束标记。
+
+```
+hello\n
+world\n
+```
+
+接收方不断从缓冲区读数据,只要遇到分隔符,就切出一条完整消息。很多文本协议都会用类似思路。
+
+这种方式直观,但要注意两个问题:第一,分隔符可能刚好出现在消息体里,这时需要转义;第二,分隔符本身也可能被拆在两次读取里,所以接收端解析时不能假设一次 `recv()` 就能读到完整分隔符。
+
+**3. 长度头**
+
+这是工程里更常见的一种方式。协议头里固定放一个长度字段,表示后面的消息体有多少字节。
+
+```
+| 4 字节长度 | 消息体 |
+```
+
+接收方先读固定长度的协议头,解析出消息体长度,再继续读取指定字节数。只要没有读满,就继续等待;如果读多了,就把多出来的字节留在缓冲区,作为下一条消息的开头。
+
+很多二进制协议、RPC 协议都会用这种方式。实际设计时,协议头里通常不只放长度,还会放魔数、版本号、消息类型、序列号、序列化方式等字段。
+
+长度头方案也有坑。长度字段要约定字节序,通常使用网络字节序;还要限制最大包体长度,避免对端传一个特别大的长度值,把内存撑爆。线上做协议解析时,不能只考虑正常路径,还要处理半包、异常长度、连接中途关闭、恶意构造请求等情况。
+
+#### Nagle 算法和 Delayed ACK 为什么会让小包变慢?
+
+讲粘包时,经常会顺带问到 Nagle 算法。
+
+Nagle 算法的目标是减少小包数量。早期网络带宽有限,如果应用每次只写 1 个字节,TCP/IP 头部却有几十个字节,网络里就会充满“小包”,效率很低。RFC 896 讨论的就是这类 small-packet problem,并提出当连接上还有未确认数据时,新的小数据可以先暂缓发送,等 ACK 到来后再继续发送。
+
+Delayed ACK 是接收端的优化。接收端收到数据后,不一定立刻发 ACK,而是等一小段时间,看能不能把 ACK 和要返回的数据一起发出去,减少纯 ACK 包数量。RFC 9293 也把这种“少于每个数据段一个 ACK”的策略称为 delayed ACK。
+
+这两个机制单独看都有道理,放在一起就可能放大延迟。典型场景是:
+
+```
+客户端 write 小数据 A
+客户端马上 write 小数据 B
+客户端等待服务端响应
+```
+
+
+
+小数据 A 发出去了,小数据 B 可能因为 Nagle 算法暂存在发送缓冲区里,等待 A 的 ACK。服务端收到 A 后,如果暂时没有业务响应要返回,Delayed ACK 又可能延迟发送 ACK。于是发送端等 ACK,接收端等更多数据或等延迟确认定时器,延迟就被放大了。
+
+这类问题在短小 RPC、交互式协议、游戏同步、远程终端里更容易被感知。
+
+解决思路不是“无脑关 Nagle”。更稳的做法是:
+
+- 能合并的小写入,在应用层先合并成一次完整消息,再调用一次 `write()`。
+- 请求/响应模型里,尽量避免连续多次小 `write()` 后马上等待响应。
+- 对延迟敏感、消息很小的连接,可以评估开启 `TCP_NODELAY`,让小数据尽快发送。
+- 对吞吐优先、希望攒够数据再发的场景,可以在 Linux 上评估 `TCP_CORK`,但它不适合写跨平台代码。
+- 调参前先抓包确认,不要看到“慢”就直接改 socket 选项。
+
+在 Java 里,很多网络框架都会暴露 `TCP_NODELAY` 配置,例如 Netty 的 `ChannelOption.TCP_NODELAY`。它确实能降低小消息的等待时间,但也可能增加小包数量。对高 QPS 服务来说,这个 trade-off 要结合消息大小、RTT、吞吐、CPU 和网卡包量一起看。Linux `tcp(7)` 也说明,`TCP_NODELAY` 会关闭 Nagle 算法,而 `TCP_CORK` 则用于避免发送不完整帧、等应用确认“可以发了”再发送。
+
+#### 面试时怎么回答?
+
+可以这么回答:
+
+TCP 是面向字节流的。应用层写入的数据会进入内核缓冲区,TCP 只保证这些字节可靠、有序地到达对端,不保证一次 `send()` 对应一次 `recv()`,也不保留应用层消息边界。因此接收方可能一次读到多条消息,也可能只读到半条消息,这就是常说的粘包、拆包现象。
+
+UDP 是面向报文的。应用层交给 UDP 的一次数据会作为一个 UDP 数据报发送,接收端也是按数据报读取,所以天然保留消息边界。不过 UDP 不保证可靠到达,也不保证顺序。
+
+解决 TCP 粘包/拆包,本质是应用层协议自己定义消息边界。常见方案有固定长度、分隔符、长度头。工程里更常用长度头,因为它对二进制协议和变长消息更友好,但要处理字节序、最大长度限制、半包缓存和异常连接关闭等问题。
diff --git a/docs/cs-basics/network/tcp-connection-and-disconnection.md b/docs/cs-basics/network/tcp-connection-and-disconnection.md
new file mode 100644
index 00000000000..ddc092ba7cc
--- /dev/null
+++ b/docs/cs-basics/network/tcp-connection-and-disconnection.md
@@ -0,0 +1,452 @@
+---
+title: TCP 三次握手和四次挥手(传输层)
+description: 一文讲清 TCP 三次握手与四次挥手:SEQ/ACK/SYN/FIN 如何同步,TIME_WAIT 与 2MSL 的原因,半连接队列(SYN Queue)与全连接队列(Accept Queue)的工作机制,以及 backlog/somaxconn/syncookies 在高并发与 SYN Flood 下的影响。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,三次握手,四次挥手,三次握手为什么,四次挥手为什么,TIME_WAIT,CLOSE_WAIT,2MSL,状态机,SEQ,ACK,SYN,FIN,RST,半连接队列,全连接队列,SYN队列,Accept队列,backlog,somaxconn,SYN Flood,syncookies
+---
+
+TCP(Transmission Control Protocol)是一种**面向连接**、**可靠**的传输层协议。这里的“可靠”,通常体现在按序交付、差错检测、丢包重传、流量控制和拥塞控制等方面。
+
+TCP 连接的建立和释放,最常被问到的就是三次握手和四次挥手。它们看起来像固定流程,背后其实是在同步序列号、确认双方收发能力,并尽量安全地释放连接状态。
+
+这篇文章主要回答几个问题:
+
+1. TCP 三次握手每一步分别做了什么?
+2. 为什么建立连接需要三次握手,而不是两次或四次?
+3. TCP 四次挥手每一步分别做了什么?
+4. `TIME_WAIT`、`CLOSE_WAIT`、半连接队列和全连接队列分别该怎么理解?
+
+> **术语约定**:本文正文统一使用 `SYN_RCVD`、`TIME_WAIT` 这类下划线写法;RFC 中常写作 `SYN-RECEIVED`、`TIME-WAIT`,Linux `ss` 命令中常显示为 `syn-recv`、`time-wait`。它们指向的是同一类 TCP 状态,只是不同语境下的写法不同。
+
+## 建立连接:TCP 三次握手
+
+
+
+在最常见的“一端主动发起连接、一端被动监听”的场景下,TCP 连接通常通过三次握手建立:
+
+1. **第一次握手(SYN)**:客户端向服务端发送一个 SYN(Synchronize Sequence Numbers)报文段,其中包含客户端生成的初始序列号(Initial Sequence Number,ISN),例如 `seq=x`。发送后,客户端进入 `SYN_SENT` 状态,等待服务端确认。
+2. **第二次握手(SYN+ACK)**:服务端收到 SYN 后,如果同意建立连接,会回复一个 SYN+ACK 报文段。这个报文段包含两个关键信息:
+ - **SYN**:服务端也需要同步自己的初始序列号,因此会携带服务端生成的 ISN,例如 `seq=y`。
+ - **ACK**:用于确认收到客户端的 SYN,确认号设置为客户端初始序列号加一,即 `ack=x+1`。
+ - 发送该报文段后,服务端进入 `SYN_RCVD` 状态。
+3. **第三次握手(ACK)**:客户端收到服务端的 SYN+ACK 后,会向服务端发送最终确认报文段,确认号为 `ack=y+1`。发送后,客户端进入 `ESTABLISHED` 状态。服务端收到这个 ACK 后,也进入 `ESTABLISHED` 状态。
+
+至此,双方完成初始序列号同步,并确认这条连接可以开始双向传输数据。
+
+### 什么是半连接队列和全连接队列?
+
+```mermaid
+sequenceDiagram
+ autonumber
+ participant C as 客户端 Client
+ participant K as 服务端内核 TCP
+ box 服务端内核队列
+ participant SQ as 半连接队列 SYN queue
+ participant AQ as 全连接队列 Accept queue
+ end
+ participant App as 用户态应用 Server app
+
+ C->>K: SYN
+ K-->>C: SYN+ACK
+ Note over SQ: 内核为该连接创建请求条目
连接状态 SYN_RCVD
放入 SYN queue
+
+ C->>K: ACK 第三次握手
+ Note over SQ,AQ: 内核收到 ACK 后完成握手
将连接从 SYN queue 迁移到 Accept queue
队列未满才可进入
+ Note over AQ: 连接已完成 可被 accept
连接状态 ESTABLISHED
+
+ App->>K: accept
+ K-->>App: 返回已就绪的 socket
+ Note over AQ: 该连接从 Accept queue 移除
+```
+
+在 TCP 三次握手过程中,服务端内核通常会用两个队列来管理连接请求。下面以常见 Linux 行为为例,不同操作系统、内核版本、socket 选项和部署环境可能会有细节差异。
+
+1. **半连接队列(SYN Queue)**:
+ - 保存“握手未完成”的请求。服务端收到 SYN 并回复 SYN+ACK 后,连接进入 `SYN_RCVD`,等待客户端最终 ACK。
+ - 如果一直收不到 ACK,内核会按重传策略重发 SYN+ACK,最终超时清理。
+ - 常见相关参数包括 `net.ipv4.tcp_max_syn_backlog`。在 SYN Flood 场景下,还会涉及 `net.ipv4.tcp_syncookies`。
+2. **全连接队列(Accept Queue)**:
+
+ - 保存“握手已完成但应用还没有 accept”的连接。服务端收到最终 ACK 后,连接变为 `ESTABLISHED`,并进入全连接队列,等待应用层 `accept()` 取走。
+ - 队列容量受 `listen(fd, backlog)` 和系统上限 `net.core.somaxconn` 共同影响。实践中常见有效上限可以近似理解为 `min(backlog, somaxconn)`,具体行为仍要看内核版本和应用配置。
+
+ 总结一下:
+
+| 队列 | 作用 | 状态 | 移出条件 |
+| -------------------------- | -------------------------------------- | ------------- | ------------------------ |
+| 半连接队列(SYN Queue) | 保存未完成握手的连接 | `SYN_RCVD` | 收到 ACK / 超时重传失败 |
+| 全连接队列(Accept Queue) | 保存已完成握手、等待应用 accept 的连接 | `ESTABLISHED` | 被应用层 `accept()` 取出 |
+
+当全连接队列满时,`net.ipv4.tcp_abort_on_overflow` 会影响处理策略:
+
+- `0`(默认):Linux 通常不会立即返回 RST,而可能丢弃第三次握手 ACK,使服务端继续停留在握手未完全完成的状态,并重传 SYN+ACK。客户端侧可能已经认为 `connect()` 成功,但首包发送后迟迟没有响应,最终表现为首包阻塞、读超时或重试。
+- `1`:直接对客户端回复 `RST`,让连接快速失败。
+
+排查时可以用 `ss -ltn` 看监听 socket。对于 `LISTEN` 状态,`Recv-Q` 通常表示当前 backlog 中等待应用 accept 的连接数,`Send-Q` 表示 socket backlog 上限。如果 `Recv-Q` 长时间接近 `Send-Q`,就要重点怀疑应用 accept 不及时、backlog 偏小、线程池卡住、GC 抖动或者短时间连接突刺。
+
+当半连接队列满时,如果 `tcp_syncookies=1`,Linux 会在 SYN backlog 溢出时启用 SYN Cookie:服务端把必要信息编码进返回的 SYN+ACK 中,而不是为每个请求都保留完整的半连接状态。只有收到合法的最终 ACK 后,内核才会重建连接所需的信息。
+
+但 SYN Cookie 是防护手段,不是扩容手段。它能缓解 SYN Flood 对半连接队列的冲击,但仍会消耗 CPU;如果攻击流量已经打满带宽,SYN Cookie 也无法从根本上恢复可用性。另外,SYN Cookie 模式下部分 TCP 扩展能力可能受限,在高延迟、高带宽链路下可能出现性能退化。`tcp_syncookies=2` 更偏测试用途,不建议作为生产环境默认配置。
+
+### 为什么要三次握手?
+
+TCP 三次握手主要做两件事:**同步双方的初始序列号**,并且**确认双方的收发路径是可用的**。真正的数据可靠交付,还要依赖后续传输过程中的确认、重传、窗口控制和拥塞控制。
+
+#### 1. 确认双方收发能力,并同步初始序列号
+
+```mermaid
+sequenceDiagram
+ autonumber
+ participant C as 客户端 Client
+ participant S as 服务端 Server
+
+ Note over C,S: 目标 同步双方 ISN 并确认双向可达
+
+ C->>S: SYN seq=ISN_C
+ Note right of S: 服务端知道 C→S 方向可达
客户端能发 服务端能收
+ Note right of S: 服务端状态 SYN_RCVD
+
+ S->>C: SYN+ACK seq=ISN_S ack=ISN_C+1
+ Note left of C: 客户端知道 S→C 方向可达
也知道服务端收到了自己的 SYN
+
+ C->>S: ACK seq=ISN_C+1 ack=ISN_S+1
+ Note left of C: 客户端状态 ESTABLISHED
+ Note right of S: 服务端知道客户端收到了 SYN+ACK
握手闭环 双方 ISN 同步完成
+ Note right of S: 服务端状态 ESTABLISHED
+
+ Note over C,S: 连接建立 可以开始传输数据
+```
+
+TCP 依赖序列号(SEQ)和确认号(ACK)来保证数据有序、去重和重传。三次握手通过交换并确认双方的 ISN,让两端对“从哪个序号开始收发数据”达成一致,同时避免只凭单向信息就进入已建立状态。
+
+可以用下面这张表来记:
+
+| 步骤 | 报文 | 能确认什么 |
+| ---- | ------------ | ---------------------------------------------------------------------- |
+| 1 | C→S:SYN | 服务端知道:客户端能发,服务端能收,C→S 方向可达 |
+| 2 | S→C:SYN+ACK | 客户端知道:服务端能发,客户端能收;同时确认服务端收到了自己的 SYN |
+| 3 | C→S:ACK | 服务端知道:客户端收到了 SYN+ACK,S→C 方向也被服务端确认;至此握手闭环 |
+
+注意,第 2 步之后只是客户端确认了双向可达,服务端还不知道客户端是否收到了 SYN+ACK。服务端只有收到第 3 次握手的 ACK 后,才真正确认这个闭环。
+
+#### 2. 防止已失效的连接请求被错误建立
+
+```mermaid
+sequenceDiagram
+ participant C as 客户端 Client
+ participant S as 服务端 Server
+
+ Note over C,S: 场景 旧的 SYN 报文在网络中滞留
+
+ C->>S: 1. 发送 SYN 旧请求 滞留中
+ Note over C: 客户端超时 放弃该请求
+
+ C->>S: 2. 发送 SYN 新请求
+ S-->>C: 3. 建立连接并正常释放
+
+ rect rgb(255, 240, 240)
+ Note right of S: 此时旧 SYN 终于到达服务端
+ S->>C: 4. 发送 SYN+ACK 针对旧请求
+
+ alt 如果是两次握手
+ Note right of S: 假设服务端回复 SYN+ACK 后
就认为连接建立
+ Note right of S: 错误建立连接
分配资源 造成浪费
+ else 如果是三次握手
+ Note left of C: 客户端无该连接状态
或认为这是非期望报文
+ C->>S: 5. 发送 RST 或直接丢弃
+ Note right of S: 收到 RST 立即清理
或等不到 ACK 后超时清理
+ end
+ end
+```
+
+设想一个场景:客户端发送的第一个连接请求 SYN1 因网络延迟而滞留。客户端超时后,重新发送 SYN2,并成功建立连接,数据传输完毕后连接也释放了。此时,延迟的 SYN1 才到达服务端。
+
+- **如果是两次握手**:服务端收到这个失效的 SYN1 后,可能误认为这是一个新的连接请求,并立即分配资源、建立连接。但客户端已经没有这个连接意图,不会继续配合传输,服务端就会单方面维持一个无效连接。
+- **有了第三次握手**:服务端收到失效的 SYN1 并回复 SYN+ACK 后,还要等待客户端最终 ACK。由于客户端当前没有这个连接状态,它可能直接丢弃,也可能发送 RST。服务端收不到合法 ACK,最终就会清理这个错误连接。
+
+所以,三次握手不是“多发一次包而已”,它让连接建立过程形成闭环,避免网络中的延迟、重复历史请求干扰新的连接。
+
+### 第 2 次握手已经传回 ACK,为什么还要传回 SYN?
+
+第二次握手里的 ACK 是为了确认“服务端收到了客户端的 SYN”,也就是确认 C→S 方向的请求已经到达。
+
+同时携带 SYN,是因为服务端也需要把自己的 ISN 同步给客户端,并要求客户端确认。只有双方的 ISN 都完成同步,后续可靠传输才有共同的序列号起点。
+
+简言之:ACK 表示“我收到了你的 SYN”,SYN 表示“我也要同步我的初始序列号,请你确认”。
+
+> SYN(Synchronize Sequence Numbers)是 TCP 建立连接时使用的同步信号。客户端先发送 SYN,服务端使用 SYN+ACK 应答,最后客户端再用 ACK 确认。这样双方才能完成初始序列号同步,建立一条可用于可靠数据传输的 TCP 连接。
+
+### 三次握手过程中可以携带数据吗?
+
+普通 TCP 中,第三次握手的 ACK 可以携带数据。RFC 9293 也允许连接同步阶段出现携带数据的报文,但接收端在确认数据有效前,不能把这部分数据交付给应用;通常需要等连接进入 `ESTABLISHED` 后,应用层才能读到这些数据。
+
+如果第三次握手的 ACK 丢失,但客户端随后发送了一个携带数据且带 ACK 标志的报文,服务端收到后可以把它视为有效的第三次握手确认。连接被认为建立后,服务端再继续处理该数据。
+
+需要注意,这和 TCP Fast Open(TFO)不是一回事。TFO 讨论的是第一次 SYN 就携带应用数据,需要客户端、服务端和系统配置共同支持,不是普通 TCP 默认行为。
+
+## 断开连接:TCP 四次挥手
+
+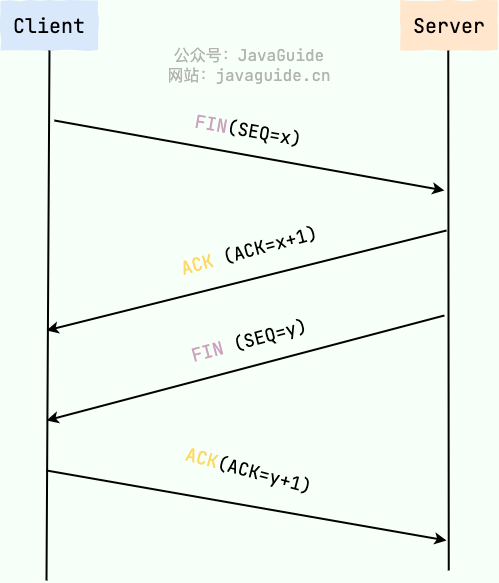
+
+TCP 是全双工通信,两端的发送方向彼此独立。关闭连接时,通常需要两个方向分别完成“我不发了”和“我确认你不发了”的过程,所以逻辑上常被讲成“四次挥手”。
+
+不过要注意:四次挥手说的是逻辑动作,不一定意味着抓包时总能看到 4 个独立报文段。在某些场景下,ACK 和 FIN 可以合并在同一个报文段里。
+
+典型流程如下:
+
+1. **第一次挥手(FIN)**:客户端,或者任意一方,决定关闭自己的发送方向时,会发送一个 FIN 报文段,表示自己已经没有数据要发送了。该报文段包含一个序列号,例如 `seq=u`。发送后,主动关闭方进入 `FIN_WAIT_1` 状态。
+2. **第二次挥手(ACK)**:服务端收到 FIN 后,会回复 ACK,确认号为 `ack=u+1`。发送后,服务端进入 `CLOSE_WAIT` 状态。客户端收到 ACK 后,进入 `FIN_WAIT_2` 状态。此时连接处于**半关闭(Half-Close)**状态:客户端到服务端的发送方向已关闭,但服务端仍然可以继续向客户端发送剩余数据。
+3. **第三次挥手(FIN)**:当服务端确认剩余数据都发送完毕后,也会发送 FIN,表示自己也准备关闭发送方向。该报文段同样包含一个序列号,例如 `seq=y`。发送后,服务端进入 `LAST_ACK` 状态,等待客户端最终确认。
+4. **第四次挥手(ACK)**:客户端收到服务端的 FIN 后,回复最终 ACK,确认号为 `ack=y+1`。发送后,客户端进入 `TIME_WAIT` 状态。服务端收到这个 ACK 后进入 `CLOSED`。客户端则在 `TIME_WAIT` 状态等待 2MSL 后,最终进入 `CLOSED`。
+
+> 注意区分:**半关闭(Half-Close)**指一个方向已经发送 FIN,另一个方向仍可继续发送数据;**半开连接(Half-Open Connection)**通常指一端崩溃、重启或状态丢失后,另一端仍以为连接存在。两者不是同一个概念。
+
+TCP 连接建立与关闭的常见状态迁移路径如下。图中省略了同时打开、同时关闭、RST、CLOSING 等少见或异常分支。
+
+
+
+### 为什么要四次挥手?
+
+因为 TCP 是全双工的。A 不想发了,不代表 B 也立刻没有数据要发。
+
+举个例子,A 和 B 打电话,通话即将结束:
+
+1. A 说:“我没什么要说的了。”(A 发 FIN)
+2. B 回答:“我知道了。”但 B 可能还有话要说。(B 回 ACK)
+3. B 继续说完剩下的话,最后说:“我也说完了。”(B 发 FIN)
+4. A 回答:“知道了。”(A 回 ACK)
+
+这对应到 TCP 中,就是两个方向分别关闭、分别确认。
+
+### 为什么不能把服务端发送的 ACK 和 FIN 合并起来,变成三次挥手?
+
+```mermaid
+sequenceDiagram
+ autonumber
+ participant C as 客户端
+ participant K as 服务端内核
+ participant A as 服务端应用
+
+ Note over C,K: 客户端发起关闭
+ C->>K: FIN
+ Note right of K: 内核立即回复 ACK
用于确认对端 FIN
+ K-->>C: ACK
+ Note right of K: 服务端状态变为 CLOSE_WAIT
+
+ Note over K,A: 应用处理阶段
+ K->>A: 通知本端应用
对端已关闭发送方向 例如 read 返回 0
+ A->>A: 读取和处理剩余数据
+ A->>A: 发送最后响应
+ A->>K: 调用 close 或 shutdown
+
+ Note right of K: 发送本端 FIN
并进入 LAST_ACK
+ K-->>C: FIN
+ Note left of C: 客户端回复 ACK
并进入 TIME_WAIT
+ C->>K: ACK
+ Note right of K: 服务端收到最终 ACK
进入 CLOSED
+```
+
+关键原因是:**回复 ACK** 和 **发送 FIN** 的触发时机通常不同。
+
+- 当服务端收到客户端 FIN 时,内核协议栈会立即回复 ACK,确认“我收到了你要关闭发送方向的请求”。此时服务端进入 `CLOSE_WAIT`,等待本端应用处理剩余数据。
+- 只有当服务端应用处理完毕,并调用 `close()` 或 `shutdown()` 后,内核才会发送本端 FIN。
+- 因此,“内核自动回 ACK”和“应用决定发 FIN”在时间上是解耦的,通常无法合并。只有在服务端恰好也准备立即关闭时,才可能出现 FIN+ACK 合并在一个报文段中的情况。
+
+### 如果第二次挥手时服务端的 ACK 没有送达客户端,会怎样?
+
+客户端发送第一次 FIN 后进入 `FIN_WAIT_1`,并启动重传计时器。如果在超时时间内没有收到对端对 FIN 的确认 ACK,客户端会重传 FIN。
+
+服务端如果收到重复 FIN,通常会再次发送 ACK。如果由于网络问题 ACK 一直无法送达,客户端在达到一定重试或超时阈值后,可能报错或放弃。具体行为受实现和参数影响,例如 Linux 中的 `tcp_retries2` 等。
+
+### 为什么第四次挥手后要等待 2MSL?
+
+第四次挥手时,主动关闭方发送给被动关闭方的最后一个 ACK 可能丢失。如果被动关闭方没有收到 ACK,就会重传 FIN。主动关闭方还在 `TIME_WAIT` 里,就能再次回复 ACK。
+
+如果主动关闭方发完最后一个 ACK 后立刻进入 `CLOSED`,当对端重传 FIN 到达时,本端可能已经没有对应连接状态,只能回复 RST,导致对端看到异常关闭或连接被重置。
+
+```mermaid
+sequenceDiagram
+ participant A as 主动关闭方
+ participant B as 被动关闭方
+
+ B->>A: FIN
+ A-->>B: ACK 丢失
+ Note over A: A 进入 TIME_WAIT
没有立刻释放连接
+ B->>A: 重传 FIN
+ A-->>B: 再次 ACK
+ Note over B: B 收到 ACK 后进入 CLOSED
+```
+
+**MSL(Maximum Segment Lifetime)** 是报文段在网络中的最大生存时间。2MSL 不是一次请求-响应的最大 RTT,而是一个保守等待窗口:既给最后 ACK 丢失后的 FIN 重传留出处理机会,也尽量保证旧连接中的延迟报文从网络中消失。
+
+需要注意,RFC 里的 MSL 是协议层概念,具体系统实现可能不同。Linux 常见实现中,`TIME_WAIT` 保留时间通常是 60 秒。还有一个常见误区:`tcp_fin_timeout` 控制的是 orphaned connection 的 `FIN_WAIT_2` 超时,不是 `TIME_WAIT`。想缓解 `TIME_WAIT` 带来的端口压力,优先看连接复用、端口范围、主动关闭方和 `tcp_tw_reuse` 条件,而不是试图用 `tcp_fin_timeout` 缩短 `TIME_WAIT`。
+
+## TIME_WAIT 常见问题:为什么要等、会不会出问题、能不能复用?
+
+> 这部分内容已单独成文,详见 [TCP TIME_WAIT 详解:为什么要等、会不会出问题、能不能复用?](./tcp-time-wait.md)。
+
+上一节讲了为什么四次挥手最后要等 2MSL,这一节继续回答几个线上最常见的问题:大量 `TIME_WAIT` 会不会拖垮系统,为什么不建议随便开 `tcp_tw_reuse`,以及 `TIME_WAIT` 和 `CLOSE_WAIT` 到底怎么区分。
+
+### TIME_WAIT 不只是“等一会儿再关”
+
+ACK 都已经发出去了,为什么还要占着端口等几十秒?
+
+主动关闭方发出最后一个 ACK 后,不会立刻释放连接,而是进入 `TIME_WAIT`。RFC 9293 的连接状态图里也能看到,`TIME_WAIT` 会在 2MSL 超时后删除 TCB,并进入 `CLOSED`。
+
+这里要注意一个细节:不是“谁收到 FIN 谁就一定进入 TIME_WAIT”。被动关闭方收到 FIN 后,通常会先进入 `CLOSE_WAIT`,等待本端应用处理完剩余数据并调用 `close()` 或 `shutdown()`。更常见的情况是,主动关闭方收到对端最后的 FIN,并回复最后一个 ACK 后,进入 `TIME_WAIT`。
+
+一般来说,**谁主动关闭连接,谁就更容易进入 TIME_WAIT**。比如客户端主动断开 HTTP 短连接,`TIME_WAIT` 往往出现在客户端;如果服务端主动断开连接,服务端也可能堆出大量 `TIME_WAIT`。
+
+看起来像是多等了一会儿,实际上是在解决两个问题。
+
+### 第一个原因:让最后一个 ACK 有补救机会
+
+主动关闭方发送最后一个 ACK 后,如果这个 ACK 在网络中丢了,被动关闭方会以为自己的 FIN 没被确认,于是重发 FIN。主动关闭方还在 `TIME_WAIT` 里,就能再次回复 ACK;如果它已经进入 `CLOSED`,就可能回 RST,让对端感知为异常关闭或连接被重置。
+
+### 第二个原因:别让旧连接的包混进新连接
+
+TCP 连接靠四元组定位:源 IP、源端口、目的 IP、目的端口。如果旧连接刚关闭,立刻用同一个四元组建立新连接,旧连接里延迟到达的数据包可能刚好落在新连接接收窗口里,被当成新连接的数据处理。
+
+举个例子:
+
+```text
+旧连接:client:50000 -> server:443
+服务端发出的 SEQ=301 数据包在网络里绕了一圈,迟迟没到。
+
+旧连接关闭后,客户端很快复用了同一个源端口:
+新连接:client:50000 -> server:443
+
+这时旧的 SEQ=301 抵达客户端。
+如果它刚好落在新连接接收窗口里,就有可能被误收。
+```
+
+TCP 序列号空间是 0 到 2^32 - 1,会按模 2^32 回绕,所以不能只靠序列号永久区分新老报文。实际系统还有时间戳、PAWS(Protection Against Wrapped Sequences)、随机 ISN 等保护,但它们不是“完全替代 TIME_WAIT”的万能方案。RFC 1337 也讨论过旧重复报文导致的 TIME_WAIT 风险。
+
+### 大量 TIME_WAIT 到底有没有问题?
+
+`TIME_WAIT` 本身是正常状态。真正的问题通常出现在主动关闭方短时间内创建大量到同一个目标 IP + 目标端口的连接,导致本地临时端口被占住。
+
+Linux 本地临时端口范围可通过 `net.ipv4.ip_local_port_range` 查看和调整。上游内核文档里的默认范围是 `32768 60999`,实际环境以本机输出为准:
+
+```bash
+cat /proc/sys/net/ipv4/ip_local_port_range
+```
+
+如果客户端短时间内反复连接同一个目标 IP + 目标端口,旧连接又都停在 `TIME_WAIT`,本地可用临时端口可能被占满,导致新连接无法分配源端口,常见报错如:
+
+```text
+Cannot assign requested address
+```
+
+可以按这个思路判断:
+
+- **如果服务端上看到很多 TIME_WAIT**:先看是不是服务端主动关闭了连接,比如服务端主动断开短连接、网关主动关闭上游连接、连接池主动淘汰连接。
+- **如果客户端或网关上看到很多 TIME_WAIT**:重点看是否存在短连接风暴、连接池未复用、HTTP keep-alive 没打开、上游频繁断连。
+
+还可以做一个粗略估算:
+
+```text
+同一目标 IP:Port 的短连接上限 ≈ 可用临时端口数 / TIME_WAIT 保留时间
+```
+
+比如默认端口范围 `32768~60999`,大约 2.8 万个端口。如果 `TIME_WAIT` 保留约 60 秒,那么同一目标 IP:Port 上持续新建短连接的上限大约是数百 QPS 量级。实际结果还会受到连接复用、端口保留、NAT、内核策略和不同远端四元组复用规则影响,不能只看 `TIME_WAIT` 总数就下结论。
+
+### 为什么不建议随便开 tcp_tw_reuse?
+
+`tcp_tw_reuse` 允许在协议认为安全的条件下,为新的主动连接复用 `TIME_WAIT` socket。它看起来像是缓解端口压力的捷径,但这类参数改变的是 TCP 对旧连接报文的等待策略,不能当成通用开关。
+
+这里要分三层看:
+
+1. **它依赖时间戳等条件判断“新报文是否足够新”**。时间戳可以过滤一部分旧报文,但不是所有异常都能覆盖。RFC 1337 重点讨论过 `TIME_WAIT` 状态被旧 RST 等报文提前终止的风险。旧数据段如果落入新连接可接受窗口,可能造成新旧数据混淆;旧 ACK 的影响则依赖序列号、窗口和实现细节,不宜和旧 RST 直接并列成同一种断连风险。
+2. **当前上游 Linux 文档中,`tcp_tw_reuse` 可取 0/1/2,默认值为 2**,表示仅允许 loopback 流量复用;`1` 才是全局开启。但旧版内核文档、发行版 man page 或历史资料可能仍写作“默认关闭”,实际机器必须以 `sysctl net.ipv4.tcp_tw_reuse` 为准。内核文档也明确提示,不要在没有专家建议或明确需求时修改。
+3. **不要把 `tcp_tw_reuse` 和已经废弃的 `tcp_tw_recycle` 搞混**。`tcp_tw_recycle` 在 NAT 环境下会导致时间戳冲突,大量连接被异常丢弃,Linux 4.12 之后已经被移除。网上很多老文章仍然会建议同时打开 `tcp_tw_reuse` 和 `tcp_tw_recycle`,这类配置不要照搬。
+
+一句话:`tcp_tw_reuse` 可以讨论,但必须结合 Linux 版本、是否 loopback、是否经过 NAT、是否启用时间戳、是否真的存在端口耗尽来判断。能在应用层解决的,优先在应用层解决。
+
+### TIME_WAIT 和 CLOSE_WAIT:一个正常等待,一个更像应用没收尾
+
+排查连接状态时,`CLOSE_WAIT` 通常比 `TIME_WAIT` 更值得警惕。
+
+收到对端 FIN 后,本端内核会回 ACK,然后进入 `CLOSE_WAIT`,等待应用处理完剩余数据并调用 `close()` 或 `shutdown()`。在 Java 服务里,`CLOSE_WAIT` 堆积经常和连接没有正确关闭有关。比如手写 Socket、HTTP 客户端响应体没有 close、异常分支提前 return、连接池连接没有归还,都可能让内核已经 ACK 了对端 FIN,但应用迟迟不调用 close。
+
+可以先按这个思路判断:
+
+- **TIME_WAIT**:主动关闭方在等 2MSL,通常是协议设计的一部分。
+- **CLOSE_WAIT**:被动关闭方已经知道对端不发了,但本端应用还没关闭 socket。大量堆积时,优先怀疑应用代码没释放连接、线程卡住、连接池归还异常、读写流程没有走到 finally。
+
+| 状态 | 常见出现方 | 含义 | 排查方向 |
+| ---------- | ---------- | ----------------------------------- | ------------------------------------------------- |
+| TIME_WAIT | 主动关闭方 | 等最后 ACK 重传机会,也等旧报文消失 | 短连接、连接池、keep-alive、端口范围 |
+| CLOSE_WAIT | 被动关闭方 | 对端已关闭,本端应用还没 close | 代码是否释放 socket、线程是否卡住、连接池是否泄漏 |
+
+### 排查时别只盯着数量,要先看谁在主动关闭
+
+TIME_WAIT 与 CLOSE_WAIT 排查思路。TIME_WAIT 重点看谁在主动关闭连接,CLOSE_WAIT 则优先排查应用是否正确释放 socket 或归还连接。
+
+
+
+看到大量 `TIME_WAIT` 或 `CLOSE_WAIT`,可以先用下面几条命令定位方向:
+
+`ss` 是 Linux 上 `iproute2` 提供的命令,macOS 默认没有。如果你的开发环境是 macOS,可以用 `netstat` 和 `lsof` 替代。
+
+```bash
+# Linux:查看各 TCP 状态数量
+ss -ant | awk 'NR>1 {cnt[$1]++} END {for (s in cnt) print s, cnt[s]}'
+
+# macOS:查看各 TCP 状态数量
+netstat -anp tcp | awk '$1 ~ /^tcp/ {cnt[$NF]++} END {for (s in cnt) print s, cnt[s]}'
+
+# Linux:查看 TIME-WAIT 主要集中在哪些目标
+ss -ant state time-wait | awk 'NR>1 {print $5}' | sort | uniq -c | sort -nr | head
+
+# macOS:查看 TIME-WAIT 主要集中在哪些远端
+netstat -anp tcp | awk '$1 ~ /^tcp/ && $NF=="TIME_WAIT" {print $(NF-1)}' | sort | uniq -c | sort -nr | head
+
+# Linux:查看 CLOSE-WAIT 对应哪个进程(需要 sudo 才能看到进程信息)
+sudo ss -tanp state close-wait
+
+# macOS:查看 CLOSE-WAIT 对应哪个进程
+sudo lsof -nP -iTCP -sTCP:CLOSE_WAIT
+
+# Linux:查看监听 socket 的 accept queue 情况
+ss -ltn
+```
+
+
+
+命令背后的判断:
+
+- **TIME_WAIT 集中在某个远端服务**:检查是否短连接太多、HTTP 连接复用没生效、连接池配置过小、连接池被频繁销毁,或者对端频繁主动断开。
+- **CLOSE_WAIT 集中在某个本地进程**:优先查应用代码,尤其是异常分支有没有关闭响应体、socket 或连接对象。
+- **LISTEN socket 的 Recv-Q 长时间接近 Send-Q**:重点排查 accept queue 堆积,看看应用 accept 是否及时、线程池是否卡住、backlog 配置是否过小。
+- 如果是网关、代理、爬虫、压测客户端,`TIME_WAIT` 更常见;如果是 Java 服务端内部依赖调用泄漏,`CLOSE_WAIT` 更常见。
+
+### 克制的优化建议
+
+按优先级排查:
+
+1. **优先减少不必要的短连接**:开启 HTTP keep-alive,复用连接池。
+2. **确认谁在主动关闭连接**:服务端、客户端、网关、连接池都有可能成为主动关闭方。
+3. **检查应用侧资源释放**:尤其是 HTTP 响应体、Socket、数据库连接、连接池连接归还。
+4. **扩大本地端口范围**:在客户端短连接确实很高、且存在端口耗尽证据时,再考虑调整 `ip_local_port_range`。
+5. **最后才看内核参数**:`tcp_tw_reuse`、`tcp_abort_on_overflow`、`tcp_syncookies` 都要结合 Linux 版本、业务连接模型、是否经过 NAT、是否被攻击、是否有真实观测数据来判断,不建议直接照抄网上配置。
+
+`TIME_WAIT` 多,不一定是故障;`CLOSE_WAIT` 多,通常要先看代码。这两个状态看起来都像“连接没关干净”,但问题方向完全不同。
+
+## 参考
+
+- 《计算机网络(第 7 版)》
+- 《图解 HTTP》
+- TCP and UDP Tutorial:
+- 从一次线上问题说起,详解 TCP 半连接队列、全连接队列:
+- RFC 9293: Transmission Control Protocol (TCP):
+- RFC 1337: TIME-WAIT Assassination Hazards in TCP:
+- Linux 内核 ip-sysctl 文档:
+- SoByte - 为什么 TCP 需要 TIME_WAIT 状态:
+
+
diff --git a/docs/cs-basics/network/tcp-reliability-guarantee.md b/docs/cs-basics/network/tcp-reliability-guarantee.md
new file mode 100644
index 00000000000..202112ee981
--- /dev/null
+++ b/docs/cs-basics/network/tcp-reliability-guarantee.md
@@ -0,0 +1,144 @@
+---
+title: TCP 传输可靠性保障(传输层)
+description: 系统梳理 TCP 的可靠性保障机制,覆盖重传/选择确认、流量与拥塞控制,明确端到端可靠传输的实现要点。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,可靠性,重传,SACK,流量控制,拥塞控制,滑动窗口,校验和
+---
+
+TCP 常被说成可靠传输协议,但“可靠”不是一句抽象承诺,而是一组具体机制共同配合出来的结果。
+
+丢包要重传,乱序要重排,接收方处理不过来要流量控制,网络拥塞时要主动降速。把这些机制串起来,才能真正理解 TCP 为什么能在不可靠的 IP 网络之上提供可靠传输。
+
+这篇文章主要回答几个问题:
+
+1. TCP 通过哪些机制保证数据可靠到达?
+2. 超时重传、快速重传、SACK、D-SACK 分别解决什么问题?
+3. TCP 如何通过滑动窗口实现流量控制?
+4. 拥塞控制中的慢开始、拥塞避免、快重传、快恢复分别怎么理解?
+
+## TCP 如何保证传输的可靠性?
+
+1. **基于数据块传输**:应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
+2. **对失序数据包重新排序以及去重**:TCP 为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据就可以实现数据包去重。
+3. **校验和**:TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
+4. **重传机制**:在数据包丢失或延迟的情况下,重新发送数据包,直到收到对方的确认应答(ACK)。TCP 重传机制主要有:基于计时器的重传(也就是超时重传)、快速重传(基于接收端的反馈信息来引发重传)、SACK(在快速重传的基础上,返回最近收到的报文段的序列号范围,这样客户端就知道,哪些数据包已经到达服务器了)、D-SACK(重复 SACK,在 SACK 的基础上,额外携带信息,告知发送方有哪些数据包自己重复接收了)。关于重传机制的详细介绍,可以查看[详解 TCP 超时与重传机制](https://zhuanlan.zhihu.com/p/101702312)这篇文章。
+5. **流量控制**:TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议(TCP 利用滑动窗口实现流量控制)。
+6. **拥塞控制**:当网络拥塞时,减少数据的发送。TCP 在发送数据的时候,需要考虑两个因素:一是接收方的接收能力,二是网络的拥塞程度。接收方的接收能力由滑动窗口表示,表示接收方还有多少缓冲区可以用来接收数据。网络的拥塞程度由拥塞窗口表示,它是发送方根据网络状况自己维护的一个值,表示发送方认为可以在网络中传输的数据量。发送方发送数据的大小是滑动窗口和拥塞窗口的最小值,这样可以保证发送方既不会超过接收方的接收能力,也不会造成网络的过度拥塞。
+
+## TCP 如何实现流量控制?
+
+**TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。** 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
+
+**为什么需要流量控制?** 这是因为双方在通信的时候,发送方的速率与接收方的速率是不一定相等,如果发送方的发送速率太快,会导致接收方处理不过来。如果接收方处理不过来的话,就只能把处理不过来的数据存在 **接收缓冲区(Receiving Buffers)** 里(失序的数据包也会被存放在缓存区里)。如果缓存区满了发送方还在狂发数据的话,接收方只能把收到的数据包丢掉。出现丢包问题的同时又疯狂浪费着珍贵的网络资源。因此,我们需要控制发送方的发送速率,让接收方与发送方处于一种动态平衡才好。
+
+这里需要注意的是(常见误区):
+
+- 发送端不等同于客户端
+- 接收端不等同于服务端
+
+TCP 为全双工(Full-Duplex,FDX)通信,双方可以进行双向通信,客户端和服务端既可能是发送端又可能是服务端。因此,两端各有一个发送缓冲区与接收缓冲区,两端都各自维护一个发送窗口和一个接收窗口。接收窗口大小取决于应用、系统、硬件的限制(TCP 传输速率不能大于应用的数据处理速率)。通信双方的发送窗口和接收窗口的要求相同。
+
+**TCP 发送窗口可以划分成四个部分**:
+
+1. 已经发送并且确认的 TCP 段(已经发送并确认);
+2. 已经发送但是没有确认的 TCP 段(已经发送未确认);
+3. 未发送但是接收方准备接收的 TCP 段(可以发送);
+4. 未发送并且接收方也并未准备接受的 TCP 段(不可发送)。
+
+**TCP 发送窗口结构图示**:
+
+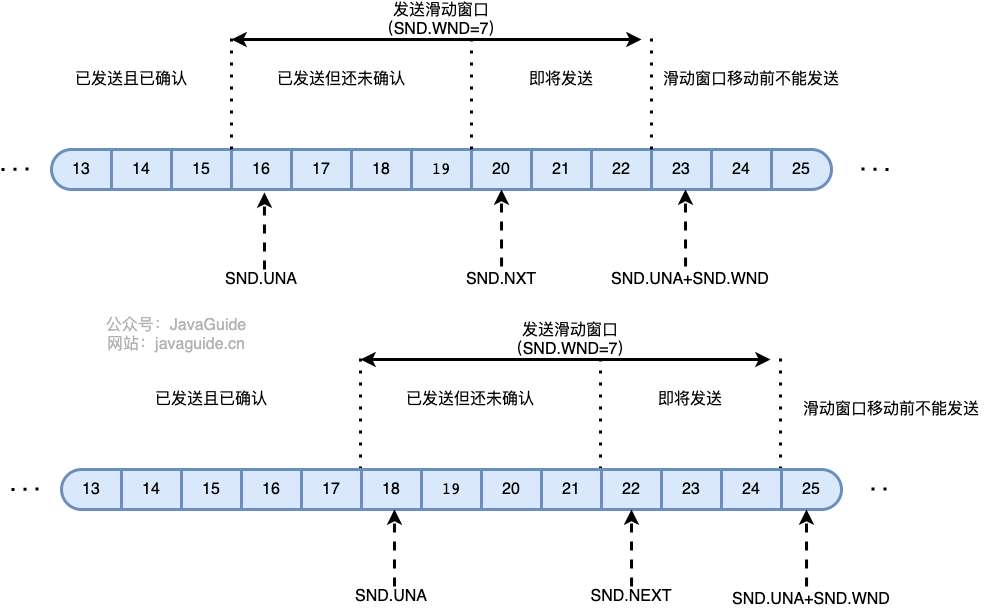
+
+- **SND.WND**:发送窗口。
+- **SND.UNA**:Send Unacknowledged 指针,指向发送窗口的第一个字节。
+- **SND.NXT**:Send Next 指针,指向可用窗口的第一个字节。
+
+**可用窗口大小** = `SND.UNA + SND.WND - SND.NXT` 。
+
+**TCP 接收窗口可以划分成三个部分**:
+
+1. 已经接收并且已经确认的 TCP 段(已经接收并确认);
+2. 等待接收且允许发送方发送 TCP 段(可以接收未确认);
+3. 不可接收且不允许发送方发送 TCP 段(不可接收)。
+
+**TCP 接收窗口结构图示**:
+
+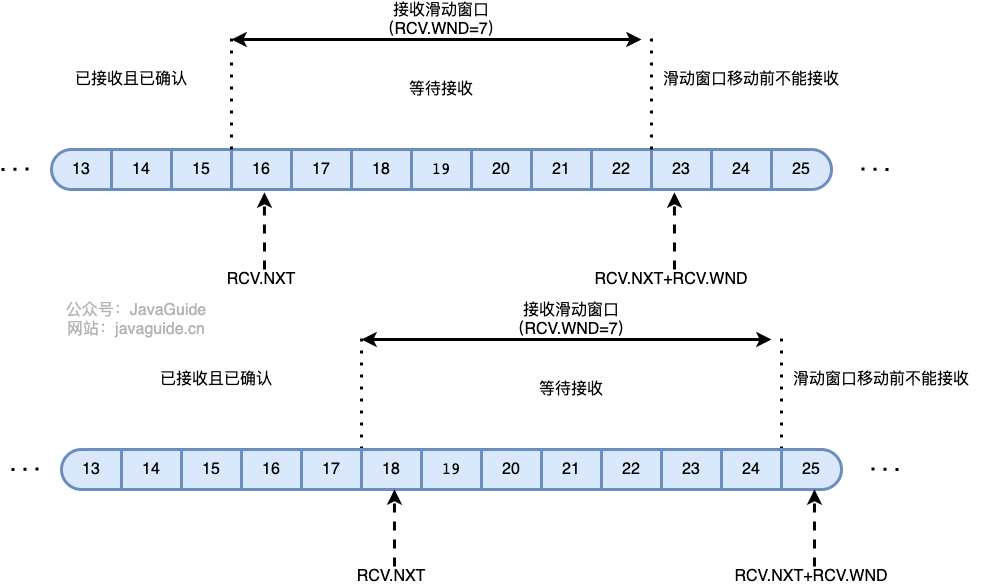
+
+**接收窗口的大小是根据接收端处理数据的速度动态调整的。** 如果接收端读取数据快,接收窗口可能会扩大。 否则,它可能会缩小。
+
+另外,这里的滑动窗口大小只是为了演示使用,实际窗口大小通常会远远大于这个值。
+
+## TCP 的拥塞控制是怎么实现的?
+
+在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
+
+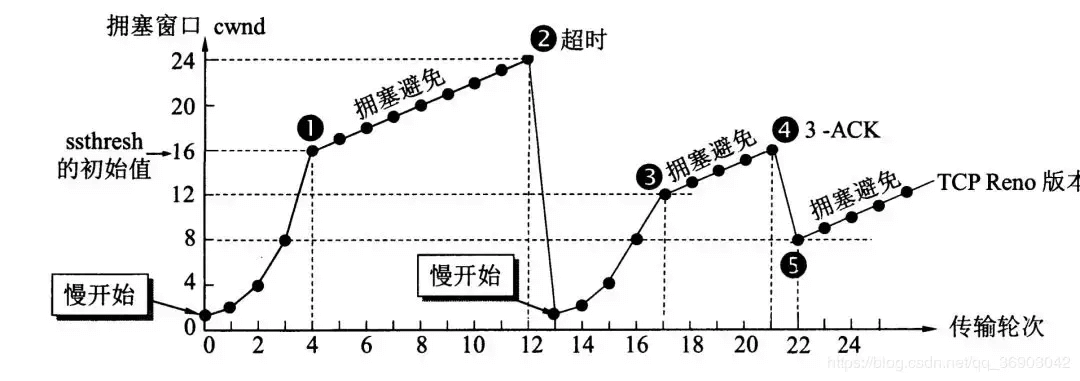
+
+为了进行拥塞控制,TCP 发送方要维持一个 **拥塞窗口(cwnd)** 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
+
+TCP 的拥塞控制采用了四种算法,即 **慢开始**、**拥塞避免**、**快重传** 和 **快恢复**。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
+
+- **慢开始**:慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的负荷情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。
+- **拥塞避免**:拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢增大,即每经过一个往返时间 RTT 就把发送方的 cwnd 加 1。
+- **快重传与快恢复**:在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
+
+## ARQ 协议了解吗?
+
+**自动重传请求**(Automatic Repeat-reQuest,ARQ)是 OSI 模型中数据链路层和传输层的错误纠正协议之一。它通过使用确认和超时这两个机制,在不可靠服务的基础上实现可靠的信息传输。如果发送方在发送后一段时间之内没有收到确认信息(Acknowledgements,就是我们常说的 ACK),它通常会重新发送,直到收到确认或者重试超过一定的次数。
+
+ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
+
+### 停止等待 ARQ 协议
+
+停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认(回复 ACK)。如果过了一段时间(超时时间后),还是没有收到 ACK 确认,说明没有发送成功,需要重新发送,直到收到确认后再发下一个分组。
+
+在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认。
+
+**1)无差错情况:**
+
+发送方发送分组,接收方在规定时间内收到,并且回复确认。发送方再次发送。
+
+**2)出现差错情况(超时重传):**
+
+停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为 **自动重传请求 ARQ** 。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。
+
+**3)确认丢失和确认迟到**
+
+- **确认丢失**:确认消息在传输过程丢失。当 A 发送 M1 消息,B 收到后,B 向 A 发送了一个 M1 确认消息,但却在传输过程中丢失。而 A 并不知道,在超时计时过后,A 重传 M1 消息,B 再次收到该消息后采取以下两点措施:1. 丢弃这个重复的 M1 消息,不向上层交付。 2. 向 A 发送确认消息。(不会认为已经发送过了,就不再发送。A 能重传,就证明 B 的确认消息丢失)。
+- **确认迟到**:确认消息在传输过程中迟到。A 发送 M1 消息,B 收到并发送确认。在超时时间内没有收到确认消息,A 重传 M1 消息,B 仍然收到并继续发送确认消息(B 收到了 2 份 M1)。此时 A 收到了 B 第二次发送的确认消息。接着发送其他数据。过了一会,A 收到了 B 第一次发送的对 M1 的确认消息(A 也收到了 2 份确认消息)。处理如下:1. A 收到重复的确认后,直接丢弃。2. B 收到重复的 M1 后,也直接丢弃重复的 M1。
+
+### 连续 ARQ 协议
+
+连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
+
+- **优点**:信道利用率高,容易实现,即使确认丢失,也不必重传。
+- **缺点**:不能向发送方反映出接收方已经正确收到的所有分组的信息。比如:发送方发送了 5 条消息,中间第三条丢失(3 号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
+
+## 超时重传如何实现?超时重传时间怎么确定?
+
+当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为已丢失并进行重传。
+
+- RTT(Round Trip Time):往返时间,也就是数据包从发出去到收到对应 ACK 的时间。
+- RTO(Retransmission Time Out):重传超时时间,即从数据发送时刻算起,超过这个时间便执行重传。
+
+RTO 的确定是一个关键问题,因为它直接影响到 TCP 的性能和效率。如果 RTO 设置得太小,会导致不必要的重传,增加网络负担;如果 RTO 设置得太大,会导致数据传输的延迟,降低吞吐量。因此,RTO 应该根据网络的实际状况,动态地进行调整。
+
+RTT 的值会随着网络的波动而变化,所以 TCP 不能直接使用 RTT 作为 RTO。为了动态地调整 RTO,TCP 协议采用了一些算法,如加权移动平均(EWMA)算法、Karn 算法、Jacobson 算法等,这些算法都是根据往返时延(RTT)的测量和变化来估计 RTO 的值。
+
+## 参考
+
+1. 《计算机网络(第 7 版)》
+2. 《图解 HTTP》
+3. TCP and UDP Tutorial:
+4. Computer Network:
+5. TCP Flow Control:
+6. TCP 流量控制(Flow Control):
+7. TCP 之滑动窗口原理:
+
+
diff --git a/docs/cs-basics/network/tcp-time-wait.md b/docs/cs-basics/network/tcp-time-wait.md
new file mode 100644
index 00000000000..a2caf125c7f
--- /dev/null
+++ b/docs/cs-basics/network/tcp-time-wait.md
@@ -0,0 +1,192 @@
+---
+title: TCP TIME_WAIT 详解:为什么要等、会不会出问题、能不能复用?
+description: 深入分析 TCP TIME_WAIT 状态的两个存在原因(最后 ACK 补救机会 + 防旧包混入新连接),大量 TIME_WAIT 的危害边界与粗略估算,tcp_tw_reuse 的正确使用姿势,以及 TIME_WAIT 与 CLOSE_WAIT 的区分与线上排查思路。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,TIME_WAIT,CLOSE_WAIT,2MSL,tcp_tw_reuse,tcp_tw_recycle,四次挥手,端口耗尽,连接复用,MSL,PAWS
+---
+
+TCP 四次挥手的最后一步,主动关闭方发完 ACK 后不是立刻关闭,而是进入 `TIME_WAIT` 状态,默认要等上 60 秒。
+
+这 60 秒经常被误解:有人觉得是浪费资源,有人想着用内核参数强行关掉,有人把 `CLOSE_WAIT` 和 `TIME_WAIT` 混着排查。
+
+这篇文章回答线上最常见的几个问题:
+
+1. `TIME_WAIT` 到底在等什么?
+2. `TIME_WAIT` 大量堆积会不会真的出问题?
+3. `tcp_tw_reuse` 能不能随便开?
+4. `TIME_WAIT` 和 `CLOSE_WAIT` 怎么区分?
+
+## TIME_WAIT 不只是“等一会儿再关”
+
+ACK 都已经发出去了,为什么还要占着端口等几十秒?
+
+主动关闭方发出最后一个 ACK 后,不会立刻释放连接,而是进入 `TIME_WAIT`。RFC 9293 的连接状态图里也能看到,`TIME_WAIT` 会在 2MSL 超时后删除 TCB,并进入 `CLOSED`。
+
+这里要注意一个细节:不是“谁收到 FIN 谁就一定进入 TIME_WAIT”。被动关闭方收到 FIN 后,通常会先进入 `CLOSE_WAIT`,等待本端应用处理完剩余数据并调用 `close()` 或 `shutdown()`。更常见的情况是,主动关闭方收到对端最后的 FIN,并回复最后一个 ACK 后,进入 `TIME_WAIT`。
+
+**谁主动关闭连接,谁就更容易进入 TIME_WAIT。** 比如客户端主动断开 HTTP 短连接,`TIME_WAIT` 往往出现在客户端;如果服务端主动断开连接,服务端也可能堆出大量 `TIME_WAIT`。
+
+看起来像是多等了一会儿,实际上是在解决两个问题。
+
+## 第一个原因:让最后一个 ACK 有补救机会
+
+主动关闭方发送最后一个 ACK 后,如果这个 ACK 在网络中丢了,被动关闭方会以为自己的 FIN 没被确认,于是重发 FIN。主动关闭方还在 `TIME_WAIT` 里,就能再次回复 ACK;如果它已经进入 `CLOSED`,就可能回 RST,让对端感知为异常关闭或连接被重置。
+
+```mermaid
+sequenceDiagram
+ participant A as 主动关闭方
+ participant B as 被动关闭方
+
+ B->>A: FIN
+ A-->>B: ACK 丢失
+ Note over A: A 进入 TIME_WAIT
没有立刻释放连接
+ B->>A: 重传 FIN
+ A-->>B: 再次 ACK
+ Note over B: B 收到 ACK 后进入 CLOSED
+```
+
+**MSL(Maximum Segment Lifetime)** 是报文段在网络中的最大生存时间。2MSL 不是一次请求-响应的最大 RTT,而是一个保守等待窗口:既给最后 ACK 丢失后的 FIN 重传留出处理机会,也尽量保证旧连接中的延迟报文从网络中消失。
+
+需要注意,RFC 里的 MSL 是协议层概念,具体系统实现可能不同。Linux 常见实现中,`TIME_WAIT` 保留时间通常是 60 秒。还有一个常见误区:`tcp_fin_timeout` 控制的是 orphaned connection 的 `FIN_WAIT_2` 超时,不是 `TIME_WAIT`。想缓解 `TIME_WAIT` 带来的端口压力,优先看连接复用、端口范围、主动关闭方和 `tcp_tw_reuse` 条件,而不是试图用 `tcp_fin_timeout` 缩短 `TIME_WAIT`。
+
+## 第二个原因:别让旧连接的包混进新连接
+
+TCP 连接靠四元组定位:源 IP、源端口、目的 IP、目的端口。如果旧连接刚关闭,立刻用同一个四元组建立新连接,旧连接里延迟到达的数据包可能刚好落在新连接接收窗口里,被当成新连接的数据处理。
+
+举个例子:
+
+```text
+旧连接:client:50000 -> server:443
+服务端发出的 SEQ=301 数据包在网络里绕了一圈,迟迟没到。
+
+旧连接关闭后,客户端很快复用了同一个源端口:
+新连接:client:50000 -> server:443
+
+这时旧的 SEQ=301 抵达客户端。
+如果它刚好落在新连接接收窗口里,就有可能被误收。
+```
+
+TCP 序列号空间是 0 到 2^32 - 1,会按模 2^32 回绕,所以不能只靠序列号永久区分新老报文。实际系统还有时间戳、PAWS(Protection Against Wrapped Sequences)、随机 ISN 等保护,但它们不是“完全替代 TIME_WAIT”的万能方案。RFC 1337 也讨论过旧重复报文导致的 TIME_WAIT 风险。
+
+## 大量 TIME_WAIT 到底有没有问题?
+
+`TIME_WAIT` 本身是正常状态。真正的问题通常出现在主动关闭方短时间内创建大量到同一个目标 IP + 目标端口的连接,导致本地临时端口被占住。
+
+Linux 本地临时端口范围可通过 `net.ipv4.ip_local_port_range` 查看和调整。上游内核文档里的默认范围是 `32768 60999`,实际环境以本机输出为准:
+
+```bash
+cat /proc/sys/net/ipv4/ip_local_port_range
+```
+
+如果客户端短时间内反复连接同一个目标 IP + 目标端口,旧连接又都停在 `TIME_WAIT`,本地可用临时端口可能被占满,导致新连接无法分配源端口,常见报错如:
+
+```text
+Cannot assign requested address
+```
+
+可以按这个思路判断:
+
+- **如果服务端上看到很多 TIME_WAIT**:先看是不是服务端主动关闭了连接,比如服务端主动断开短连接、网关主动关闭上游连接、连接池主动淘汰连接。
+- **如果客户端或网关上看到很多 TIME_WAIT**:重点看是否存在短连接风暴、连接池未复用、HTTP keep-alive 没打开、上游频繁断连。
+
+还可以做一个粗略估算:
+
+```text
+同一目标 IP:Port 的短连接上限 ≈ 可用临时端口数 / TIME_WAIT 保留时间
+```
+
+比如默认端口范围 `32768~60999`,大约 2.8 万个端口。如果 `TIME_WAIT` 保留约 60 秒,那么同一目标 IP:Port 上持续新建短连接的上限大约是数百 QPS 量级。实际结果还会受到连接复用、端口保留、NAT、内核策略和不同远端四元组复用规则影响,不能只看 `TIME_WAIT` 总数就下结论。
+
+## 为什么不建议随便开 tcp_tw_reuse?
+
+`tcp_tw_reuse` 允许在协议认为安全的条件下,为新的主动连接复用 `TIME_WAIT` socket。它看起来像是缓解端口压力的捷径,但这类参数改变的是 TCP 对旧连接报文的等待策略,不能当成通用开关。
+
+这里要分三层看:
+
+1. **它依赖时间戳等条件判断“新报文是否足够新”**。时间戳可以过滤一部分旧报文,但不是所有异常都能覆盖。RFC 1337 重点讨论过 `TIME_WAIT` 状态被旧 RST 等报文提前终止的风险。旧数据段如果落入新连接可接受窗口,可能造成新旧数据混淆;旧 ACK 的影响则依赖序列号、窗口和实现细节,不宜和旧 RST 直接并列成同一种断连风险。
+2. **当前上游 Linux 文档中,`tcp_tw_reuse` 可取 0/1/2,默认值为 2**,表示仅允许 loopback 流量复用;`1` 才是全局开启。但旧版内核文档、发行版 man page 或历史资料可能仍写作“默认关闭”,实际机器必须以 `sysctl net.ipv4.tcp_tw_reuse` 为准。内核文档也明确提示,不要在没有专家建议或明确需求时修改。
+3. **不要把 `tcp_tw_reuse` 和已经废弃的 `tcp_tw_recycle` 搞混**。`tcp_tw_recycle` 在 NAT 环境下会导致时间戳冲突,大量连接被异常丢弃,Linux 4.12 之后已经被移除。网上很多老文章仍然会建议同时打开 `tcp_tw_reuse` 和 `tcp_tw_recycle`,这类配置不要照搬。
+
+一句话:`tcp_tw_reuse` 可以讨论,但必须结合 Linux 版本、是否 loopback、是否经过 NAT、是否启用时间戳、是否真的存在端口耗尽来判断。能在应用层解决的,优先在应用层解决。
+
+## TIME_WAIT 和 CLOSE_WAIT:一个正常等待,一个更像应用没收尾
+
+排查连接状态时,`CLOSE_WAIT` 通常比 `TIME_WAIT` 更值得警惕。
+
+收到对端 FIN 后,本端内核会回 ACK,然后进入 `CLOSE_WAIT`,等待应用处理完剩余数据并调用 `close()` 或 `shutdown()`。在 Java 服务里,`CLOSE_WAIT` 堆积经常和连接没有正确关闭有关。比如手写 Socket、HTTP 客户端响应体没有 close、异常分支提前 return、连接池连接没有归还,都可能让内核已经 ACK 了对端 FIN,但应用迟迟不调用 close。
+
+可以先按这个思路判断:
+
+- **TIME_WAIT**:主动关闭方在等 2MSL,通常是协议设计的一部分。
+- **CLOSE_WAIT**:被动关闭方已经知道对端不发了,但本端应用还没关闭 socket。大量堆积时,优先怀疑应用代码没释放连接、线程卡住、连接池归还异常、读写流程没有走到 finally。
+
+| 状态 | 常见出现方 | 含义 | 排查方向 |
+| ---------- | ---------- | ----------------------------------- | ------------------------------------------------- |
+| TIME_WAIT | 主动关闭方 | 等最后 ACK 重传机会,也等旧报文消失 | 短连接、连接池、keep-alive、端口范围 |
+| CLOSE_WAIT | 被动关闭方 | 对端已关闭,本端应用还没 close | 代码是否释放 socket、线程是否卡住、连接池是否泄漏 |
+
+## 排查时别只盯着数量,要先看谁在主动关闭
+
+
+
+看到大量 `TIME_WAIT` 或 `CLOSE_WAIT`,可以先用下面几条命令定位方向:
+
+`ss` 是 Linux 上 `iproute2` 提供的命令,macOS 默认没有。如果你的开发环境是 macOS,可以用 `netstat` 和 `lsof` 替代。
+
+```bash
+# Linux:查看各 TCP 状态数量
+ss -ant | awk 'NR>1 {cnt[$1]++} END {for (s in cnt) print s, cnt[s]}'
+
+# macOS:查看各 TCP 状态数量
+netstat -anp tcp | awk '$1 ~ /^tcp/ {cnt[$NF]++} END {for (s in cnt) print s, cnt[s]}'
+
+# Linux:查看 TIME-WAIT 主要集中在哪些目标
+ss -ant state time-wait | awk 'NR>1 {print $5}' | sort | uniq -c | sort -nr | head
+
+# macOS:查看 TIME-WAIT 主要集中在哪些远端
+netstat -anp tcp | awk '$1 ~ /^tcp/ && $NF=="TIME_WAIT" {print $(NF-1)}' | sort | uniq -c | sort -nr | head
+
+# Linux:查看 CLOSE-WAIT 对应哪个进程(需要 sudo 才能看到进程信息)
+sudo ss -tanp state close-wait
+
+# macOS:查看 CLOSE-WAIT 对应哪个进程
+sudo lsof -nP -iTCP -sTCP:CLOSE_WAIT
+
+# Linux:查看监听 socket 的 accept queue 情况
+ss -ltn
+```
+
+
+
+命令背后的判断:
+
+- **TIME_WAIT 集中在某个远端服务**:检查是否短连接太多、HTTP 连接复用没生效、连接池配置过小、连接池被频繁销毁,或者对端频繁主动断开。
+- **CLOSE_WAIT 集中在某个本地进程**:优先查应用代码,尤其是异常分支有没有关闭响应体、socket 或连接对象。
+- **LISTEN socket 的 Recv-Q 长时间接近 Send-Q**:重点排查 accept queue 堆积,看看应用 accept 是否及时、线程池是否卡住、backlog 配置是否过小。
+- 如果是网关、代理、爬虫、压测客户端,`TIME_WAIT` 更常见;如果是 Java 服务端内部依赖调用泄漏,`CLOSE_WAIT` 更常见。
+
+## 克制的优化建议
+
+按优先级排查:
+
+1. **优先减少不必要的短连接**:开启 HTTP keep-alive,复用连接池。
+2. **确认谁在主动关闭连接**:服务端、客户端、网关、连接池都有可能成为主动关闭方。
+3. **检查应用侧资源释放**:尤其是 HTTP 响应体、Socket、数据库连接、连接池连接归还。
+4. **扩大本地端口范围**:在客户端短连接确实很高、且存在端口耗尽证据时,再考虑调整 `ip_local_port_range`。
+5. **最后才看内核参数**:`tcp_tw_reuse`、`tcp_abort_on_overflow`、`tcp_syncookies` 都要结合 Linux 版本、业务连接模型、是否经过 NAT、是否被攻击、是否有真实观测数据来判断,不建议直接照抄网上配置。
+
+`TIME_WAIT` 多,不一定是故障;`CLOSE_WAIT` 多,通常要先看代码。这两个状态看起来都像“连接没关干净”,但问题方向完全不同。
+
+## 参考
+
+- RFC 9293: Transmission Control Protocol (TCP):
+- RFC 1337: TIME-WAIT Assassination Hazards in TCP:
+- Linux 内核 ip-sysctl 文档:
+- SoByte - 为什么 TCP 需要 TIME_WAIT 状态:
+
+
diff --git a/docs/cs-basics/network/the-whole-process-of-accessing-web-pages.md b/docs/cs-basics/network/the-whole-process-of-accessing-web-pages.md
new file mode 100644
index 00000000000..69cdea6342a
--- /dev/null
+++ b/docs/cs-basics/network/the-whole-process-of-accessing-web-pages.md
@@ -0,0 +1,343 @@
+---
+title: 从输入 URL 到页面展示到底发生了什么?
+description: 串联从输入 URL 到页面渲染的完整链路,涵盖 DNS、TCP、HTTP、TLS、ARP、数据封装与浏览器渲染,助力面试与实践理解。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 访问网页流程,DNS,TCP 建连,HTTP 请求,TLS 握手,ARP,资源加载,浏览器渲染,关闭连接
+---
+
+在浏览器地址栏输入 URL 到页面展示,背后会串起 DNS、TCP、TLS、HTTP、ARP、数据封装与浏览器渲染等多个环节。
+
+这道题经常被用来考察计网整体理解,因为它能把应用层、传输层、网络层和链路层的知识点都串起来。只背单个协议容易断片,按访问网页的全过程走一遍,会清楚很多。
+
+这篇文章主要回答几个问题:
+
+1. 输入 URL 后,浏览器会先做哪些本地处理?
+2. DNS 解析域名的过程是怎样的?
+3. TCP 连接如何建立?如果用了 HTTPS,TLS 握手又做了什么?
+4. HTTP 请求和响应的交互流程是什么?
+5. 数据包从主机到服务器,经过了哪些层的封装和转发?
+6. 浏览器拿到 HTML 后,如何继续加载 CSS、JS、图片等资源并渲染页面?
+7. 页面加载完成后,连接会如何复用或关闭?
+
+总的来说,网络通信模型可以用下图来表示。访问网页的过程,就是数据从应用层逐层向下封装,经物理网络传输到对端,再逐层向上解封装的过程。
+
+
+
+开始之前,先简单过一遍完整流程:
+
+1. **浏览器解析 URL 并检查缓存**:浏览器解析 URL 的各组成部分,并检查 HTTP 缓存(强缓存、协商缓存)是否已有该资源的有效副本。
+2. **DNS 解析**:浏览器通过 DNS 协议,获取域名对应的 IP 地址。
+3. **建立 TCP 连接**:浏览器根据 IP 地址和端口号,向目标服务器发起 TCP 三次握手,建立可靠传输通道。
+4. **TLS 握手(HTTPS)**:如果使用 HTTPS,在 TCP 连接建立后还要进行 TLS 握手,协商加密密钥并验证服务器身份。
+5. **发送 HTTP 请求**:浏览器在连接上向服务器发送 HTTP 请求报文,请求获取网页内容。
+6. **服务器处理并返回响应**:服务器收到请求后处理并返回 HTTP 响应报文。
+7. **浏览器解析与渲染**:浏览器解析 HTML、CSS,执行 JavaScript,并加载页面中引用的其他资源(图片、字体等)。
+8. **连接管理**:页面加载完成后,连接根据 keep-alive 策略复用或关闭。
+
+下面按这个流程逐一展开。
+
+## 第一步:解析 URL 与检查缓存
+
+打开浏览器,在地址栏输入 URL 并回车。浏览器做的第一件事不是发请求,而是解析 URL 并检查是否可以直接使用本地缓存。
+
+### URL 是什么
+
+URL(Uniform Resource Locator,统一资源定位符)是互联网上资源的唯一地址。网络上的每个可访问资源都对应一个 URL,理论上文件和 URL 一一对应。实际上也有例外,比如重定向或 CDN 场景下,多个 URL 可能指向同一份资源。
+
+### URL 的组成结构
+
+
+
+一个完整的 URL 由以下几部分组成:
+
+1. **协议**(Scheme):URL 的前缀表示采用的协议,最常见的是 `http` 和 `https`,也有文件传输的 `ftp:` 等。
+2. **域名**(Host):访问目标的通用名,也可以直接使用 IP 地址。域名本质上是 IP 地址的可读版本。
+3. **端口**(Port):紧跟域名后面,用冒号隔开。HTTP 默认 80,HTTPS 默认 443,如果使用默认端口可以省略。
+4. **资源路径**(Path):从第一个 `/` 开始,表示服务器上的资源位置。早期设计中路径对应服务器上的物理文件,现在通常是后端路由映射的虚拟路径。
+5. **查询参数**(Query):`?` 之后的部分,采用 `key=value` 键值对形式,多个参数用 `&` 隔开。服务器解析请求时会提取这些参数。
+6. **锚点**(Fragment):`#` 之后的部分,用于定位到页面内的某个位置。锚点**不会**作为请求的一部分发送给服务端,仅由浏览器本地处理。
+
+### 浏览器缓存检查
+
+解析完 URL 之后,浏览器会先检查 HTTP 缓存,看是否已经有该资源的有效副本:
+
+1. **强缓存**:检查 `Cache-Control`(如 `max-age`)或 `Expires` 头,判断缓存是否仍在有效期内。如果有效,直接使用缓存,跳过后续所有网络请求。
+2. **协商缓存**:强缓存未命中时,浏览器向服务器发送验证请求(携带 `If-Modified-Since` 或 `If-None-Match`),服务器判断资源是否变化。如果未变化,返回 `304 Not Modified`,浏览器继续使用本地缓存;如果已变化,返回 `200 OK` 和新资源。
+
+HTTP 缓存命中时,整个访问过程在此结束,无需发起网络请求。
+
+### 域名解析准备
+
+如果 HTTP 缓存未命中,浏览器需要向服务器发起网络请求,首先要拿到域名对应的 IP 地址。在正式发起 DNS 查询之前,浏览器还会依次检查:
+
+1. **浏览器 DNS 缓存**:浏览器自身维护了一份 DNS 缓存,先看有没有该域名的记录。
+2. **操作系统 DNS 缓存**:浏览器缓存未命中时,查询操作系统的 DNS 缓存。
+3. **hosts 文件**:操作系统会检查本地 `hosts` 文件,看是否有域名到 IP 地址的直接映射。如果有,直接使用该 IP 地址,跳过 DNS 解析。
+
+如果以上都没有命中,浏览器就需要发起完整的 DNS 查询。
+
+## 第二步:DNS 解析
+
+DNS(Domain Name System,域名系统)要解决的是**域名和 IP 地址的映射问题**。域名只是便于人类记忆的名字,网络通信真正需要的是 IP 地址。
+
+### DNS 解析过程
+
+浏览器拿到域名后,DNS 解析通常按以下步骤进行:
+
+1. **浏览器 DNS 缓存**:浏览器自身维护了一份 DNS 缓存,先检查缓存中是否有该域名的记录且未过期。
+2. **操作系统 DNS 缓存**:浏览器缓存未命中时,向操作系统发起 DNS 查询请求。操作系统也有自己的 DNS 缓存。
+3. **本地 DNS 服务器**:操作系统配置的本地 DNS 服务器(通常由 ISP 提供,或使用公共 DNS 如 `8.8.8.8`、`114.114.114.114`)。本地 DNS 服务器如果有缓存且未过期,直接返回结果。
+4. **递归/迭代查询**:本地 DNS 服务器缓存未命中时,它会代替客户端发起迭代查询——先问根 DNS 服务器,再问顶级域 DNS 服务器(如 `.com`),最后问权威 DNS 服务器,逐级获取目标 IP 地址。
+5. **返回结果并缓存**:本地 DNS 服务器拿到最终结果后返回给客户端,同时在本地缓存一份,供后续查询使用。
+
+下图展示了一个典型的 DNS 迭代查询过程:
+
+
+
+实际场景中,本地 DNS 服务器通常已经缓存了大量 TLD 服务器地址,多数查询不需要从根服务器开始,跳过根服务器直接查 TLD 的情况非常普遍。
+
+> 关于 DNS 的更多细节(DNS 服务器层级、递归/迭代查询的区别、DNS 记录类型、为什么通常用 UDP 等),可以参考 [DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html) 这篇文章。
+
+## 第三步:建立 TCP 连接
+
+拿到目标服务器的 IP 地址后,浏览器需要与服务器建立一个可靠的传输通道。HTTP 基于 TCP 协议,所以在发送 HTTP 请求之前必须先完成 TCP 三次握手。
+
+### TCP 三次握手
+
+TCP 三次握手的目的是**同步双方的初始序列号**,并**确认双方的收发路径是可用的**。
+
+
+
+1. **第一次握手(SYN)**:客户端发送 SYN 报文段,携带自己的初始序列号 `seq=x`,进入 `SYN_SENT` 状态。
+2. **第二次握手(SYN+ACK)**:服务端收到后回复 SYN+ACK,携带自己的初始序列号 `seq=y`,确认号 `ack=x+1`,进入 `SYN_RCVD` 状态。
+3. **第三次握手(ACK)**:客户端收到后发送 ACK,确认号 `ack=y+1`,双方进入 `ESTABLISHED` 状态,连接建立完成。
+
+三次握手的设计不是为了「多走一次」,而是让双方都能确认:对方能收到自己的数据,自己也能收到对方的数据。两次握手做不到这一点——服务端在第二次握手后,还不知道客户端是否收到了自己的 SYN+ACK。
+
+> 关于三次握手的详细分析、半连接队列/全连接队列、SYN Flood 防护等内容,可以参考 [TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html)。
+
+### 如果是 HTTPS:TLS 握手
+
+如果 URL 的协议是 HTTPS,TCP 连接建立之后还要进行 TLS 握手。TLS 的核心目标是三个:**加密**(防窃听)、**认证**(防冒充)、**完整性校验**(防篡改)。
+
+TLS 握手大致流程(以 TLS 1.2 RSA 密钥交换为例):
+
+1. **Client Hello**:客户端发送支持的 TLS 版本、加密套件列表和一个随机数。
+2. **Server Hello**:服务端从中选择一个加密套件,返回自己的证书、另一个随机数。
+3. **密钥交换**:客户端验证服务端证书的合法性(通过 CA 签名验证),然后生成预主密钥(Pre-Master Secret),用服务端公钥加密后发送给服务端。双方根据预主密钥和之前交换的两个随机数,计算出对称加密的会话密钥。
+4. **完成**:双方用会话密钥加密通信,握手结束。
+
+需要注意的是,上述流程描述的是 TLS 1.2 中基于 RSA 的密钥交换方式。现代 HTTPS 主流采用的是 ECDHE 密钥交换(TLS 1.2 和 TLS 1.3 均支持),密钥材料不是直接用公钥加密传输的,而是通过椭圆曲线 Diffie-Hellman 交换各自生成,并且具备前向安全性(Forward Secrecy)——即使服务端私钥泄露,历史通信也不会被解密。TLS 1.3 进一步简化了握手流程,将往返次数从 2-RTT 减少到 1-RTT,并移除了 RSA 静态密钥交换等不安全的密码套件。
+
+TLS 握手完成后,后续的 HTTP 请求和响应都会使用协商好的对称密钥进行加密传输。HTTPS 的安全性来自 TLS 层,而不是 HTTP 协议本身的改变。
+
+> 关于 TLS 的加密原理(非对称加密、对称加密、数字签名、CA 证书)的详细分析,可以参考 [HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html)。关于 RSA 和 ECDHE 两种密钥交换方式的区别,可以参考 [HTTPS RSA vs ECDHE 握手过程](https://javaguide.cn/cs-basics/network/https-rsa-vs-ecdhe.html)。
+
+## 第四步:发送 HTTP 请求
+
+TCP 连接(以及可能的 TLS 通道)建立好之后,浏览器就可以发送 HTTP 请求了。
+
+### HTTP 请求报文结构
+
+一个典型的 HTTP/1.1 请求报文如下:
+
+```http
+GET /index.html HTTP/1.1
+Host: www.example.com
+User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)
+Accept: text/html,application/xhtml+xml
+Accept-Encoding: gzip, deflate, br
+Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
+Connection: keep-alive
+Cookie: session_id=abc123
+```
+
+各部分含义:
+
+- **请求行**:`GET /index.html HTTP/1.1` —— 请求方法(GET)、资源路径(`/index.html`)、协议版本(HTTP/1.1)。
+- **Host 头**:指定目标主机名。这是 HTTP/1.1 的强制要求,因为同一台服务器(同一个 IP)可能通过虚拟主机托管多个网站。
+- **其他请求头**:`User-Agent`(客户端信息)、`Accept`(可接受的响应类型)、`Accept-Encoding`(支持的压缩方式)、`Cookie`(携带的状态信息)等。
+
+### 服务器处理请求
+
+服务器收到请求后,经过一系列处理生成响应:
+
+1. **接收请求**:Web 服务器(如 Nginx、Tomcat)接收并解析 HTTP 请求报文。
+2. **路由分发**:根据 URL 路径将请求路由到对应的后端处理逻辑(Controller、Servlet 等)。
+3. **业务处理**:执行具体的业务逻辑,可能涉及数据库查询、缓存读取、调用其他服务等。
+4. **构建响应**:将处理结果封装成 HTTP 响应报文。
+
+### HTTP 响应报文结构
+
+```http
+HTTP/1.1 200 OK
+Content-Type: text/html; charset=UTF-8
+Content-Encoding: gzip
+Content-Length: 1256
+Cache-Control: max-age=3600
+Set-Cookie: session_id=xyz789; Path=/
+
+
+
+...
+
+```
+
+各部分含义:
+
+- **状态行**:`HTTP/1.1 200 OK` —— 协议版本、状态码(200)、状态描述。
+- **响应头**:`Content-Type`(响应体类型)、`Content-Encoding`(压缩方式)、`Cache-Control`(缓存策略)、`Set-Cookie`(设置 Cookie)等。
+- **响应体**:请求的实际内容,如 HTML 文档、JSON 数据、图片二进制数据等。
+
+常见的状态码:
+
+| 状态码 | 类别 | 常见示例 |
+| ------ | ---------- | --------------------------------------------- |
+| 2xx | 成功 | 200 OK、206 Partial Content |
+| 3xx | 重定向 | 301 永久重定向、302 临时重定向、304 未修改 |
+| 4xx | 客户端错误 | 400 Bad Request、403 Forbidden、404 Not Found |
+| 5xx | 服务端错误 | 500 Internal Server Error、502 Bad Gateway |
+
+> 关于 HTTP 常见状态码的详细总结,可以参考 [HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)。
+
+## 第五步:数据包的封装与转发
+
+HTTP 请求从浏览器发出后,数据并不是直接「飞」到服务器的。它需要经过协议栈的逐层封装,在物理网络上一跳一跳地转发到目的地。
+
+### 数据封装过程
+
+应用层的 HTTP 报文,经过传输层、网络层、链路层的逐层封装,最终变成能在物理介质上传输的比特流:
+
+
+
+每一层只关心自己要添加的头部信息,并使用下层提供的服务来传输数据:
+
+- **传输层(TCP)**:添加源端口和目的端口,用序列号和确认号保证可靠传输。
+- **网络层(IP)**:添加源 IP 和目的 IP,负责寻址和路由,决定数据包从源到目的经过的路径。
+- **链路层**:添加源 MAC 和目的 MAC 地址,负责在相邻节点之间传输数据帧。
+
+### 网络层的路由转发
+
+数据包从源主机到目的主机,通常需要经过多个路由器中转。网络层的核心功能就是**路由与转发**:
+
+- **路由**:确定分组从源到目的经过的路径(由路由协议如 OSPF、BGP 等计算)。
+- **转发**:将分组从路由器的输入端口转移到合适的输出端口。
+
+每个路由器维护一张路由表,根据目的 IP 地址查表决定下一跳。数据包在网络中就像快递包裹,每一站只看「下一站发到哪里」,不用关心全程路径。
+
+### ARP 协议:从 IP 地址到 MAC 地址
+
+数据帧在链路层传输时,需要知道下一跳设备的 MAC 地址,而不能只用 IP 地址。ARP(Address Resolution Protocol,地址解析协议)就是解决「已知 IP 地址,如何获取对应 MAC 地址」的问题。
+
+ARP 的工作方式是**广播问询、单播响应**:
+
+1. 主机先查本地 ARP 缓存表,看是否已有目标 IP 对应的 MAC 地址。
+2. 缓存未命中时,在局域网内广播一个 ARP 请求:「谁的 IP 是 xxx.xxx.xxx.xxx?请告诉我你的 MAC地址。」
+3. 目标设备(或路由器接口)收到后,以单播方式回复自己的 MAC 地址。
+4. 请求方收到响应后,将 IP-MAC 映射存入 ARP 缓存表,后续通信直接使用。
+
+如果目标主机不在同一子网,主机不需要知道最终目标的 MAC 地址,只需要知道**本地网关(路由器)的 MAC 地址**即可。数据包先发给网关,网关再逐跳转发到目标网络。
+
+> 关于 ARP 的详细工作原理(同子网/跨子网寻址、ARP 表、常见攻击),可以参考 [ARP 协议详解(网络层)](https://javaguide.cn/cs-basics/network/arp.html)。
+
+### 网络地址转换(NAT)
+
+在大多数家庭和企业网络中,内网主机使用的是私有 IP 地址(如 `192.168.x.x`),不能直接在公网上路由。NAT(Network Address Translation)协议负责在内网和公网之间转换 IP 地址。
+
+当内网主机发送数据包到公网时,NAT 设备(通常是路由器)会将源 IP 地址从私有地址替换为公网地址,并记录端口映射关系。响应数据包返回时,NAT 再根据映射表把目的地址转换回内网主机的私有地址。
+
+## 第六步:浏览器解析与渲染
+
+服务器返回 HTML 响应后,浏览器的工作才真正开始。浏览器需要解析 HTML、构建 DOM 树、加载子资源、计算样式、布局并最终渲染到屏幕上。
+
+### HTML 解析与 DOM 构建
+
+浏览器拿到 HTML 文档后,从上到下逐行解析:
+
+1. **构建 DOM 树**:解析 HTML 标签,生成文档对象模型(DOM)树,表示页面的结构。
+2. **构建 CSSOM 树**:遇到 `` 引用的 CSS 文件或 `
 -
-
-
-


 -
-  +
+
diff --git a/README_EN.md b/README_EN.md
new file mode 100644
index 00000000000..ec1366de844
--- /dev/null
+++ b/README_EN.md
@@ -0,0 +1,452 @@
+Recommended to read through online reading platforms for better experience and faster speed! Link: [javaguide.cn](https://javaguide.cn/).
+
+
+
+
diff --git a/README_EN.md b/README_EN.md
new file mode 100644
index 00000000000..ec1366de844
--- /dev/null
+++ b/README_EN.md
@@ -0,0 +1,452 @@
+Recommended to read through online reading platforms for better experience and faster speed! Link: [javaguide.cn](https://javaguide.cn/).
+
+ +
+ +
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
diff --git a/docs/about-the-author/dog-that-copies-other-people-essay.md b/docs/about-the-author/dog-that-copies-other-people-essay.md
index 0587d0ee1ea..2ae67150843 100644
--- a/docs/about-the-author/dog-that-copies-other-people-essay.md
+++ b/docs/about-the-author/dog-that-copies-other-people-essay.md
@@ -1,34 +1,40 @@
-# 抄袭狗,你冬天睡觉脚必冷!!!
+---
+title: 抄袭狗,你冬天睡觉脚必冷!!!
+description: 原创文章被抄袭的无奈经历,知乎、CSDN多平台盗文现象吐槽,分享如何屏蔽低质量内容和维护原创权益。
+category: 走近作者
+tag:
+ - 杂谈
+---
抄袭狗真的太烦了。。。
听朋友说我的文章在知乎又被盗了,原封不动地被别人用来引流。
-
+
而且!!!这还不是最气的。
这人还在文末注明的原出处还不是我的。。。
-
+
也就是说 CSDN 有另外一位抄袭狗盗了我的这篇文章并声明了原创,知乎抄袭狗又原封不动地搬运了这位 CSDN 抄袭狗的文章。
真可谓离谱他妈给离谱开门,离谱到家了。
-
+
我打开知乎抄袭狗注明的原出处链接,好家伙,一模一样的内容,还表明了原创。
-
+
看了一下 CSDN 这位抄袭狗的文章,好家伙,把我高赞回答搬运了一个遍。。。真是很勤奋了。。。
CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范转载,各种收费下载的垃圾资源。这号称国内流量最大的技术网站贼恶心,吃香太难看,能不用就不要用吧!
-像我自己平时用 Google 搜索的时候,都是直接屏蔽掉 CSDN 这个站点的。只需要下载一个叫做 Personal Blocklist 的 Chrome 插件,然后将 blog.csdn.net 添加进黑名单就可以了。
+像我自己平时用 Google 搜索的时候,都是直接屏蔽掉 CSDN 这个站点的。只需要下载一个叫做 Personal Blocklist 的 Chrome 插件,然后将 blog.csdn.net 添加进黑名单就可以了。
-
+
我的文章基本被盗完了,关键是我自己发没有什么流量,反而是盗我文章的那些人比我这个原作者流量还大。
@@ -38,7 +44,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
看看 CSDN 热榜上的文章都是一些什么垃圾,不是各种广告就是一些毫无质量的拼凑文。
-
+
当然了,也有极少部分的高质量文章,比如涛哥、二哥、冰河、微观技术等博主的文章。
@@ -46,7 +52,6 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
今天提到的这篇被盗的文章曾经就被一个培训机构拿去做成了视频用来引流。
-
+
作为个体,咱也没啥办法,只能遇到一个举报一个。。。
-
diff --git a/docs/about-the-author/feelings-after-one-month-of-induction-training.md b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
index 9f81220150f..8ea32dd5c74 100644
--- a/docs/about-the-author/feelings-after-one-month-of-induction-training.md
+++ b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
@@ -1,19 +1,25 @@
-# 入职培训一个月后的感受
+---
+title: 入职培训一个月后的感受
+description: ThoughtWorks入职培训一个月感受,从Windows切换到Mac的适应、TWU培训内容、Feedback反馈文化等新人入职体验分享。
+category: 走近作者
+tag:
+ - 个人经历
+---
不知不觉已经入职一个多月了,在入职之前我没有在某个公司实习过或者工作过,所以很多东西刚入职工作的我来说还是比较新颖的。学校到职场的转变,带来了角色的转变,其中的差别因人而异。对我而言,在学校的时候课堂上老师课堂上教的东西,自己会根据自己的兴趣选择性接受,甚至很多课程你不想去上的话,还可以逃掉。到了公司就不一样了,公司要求你会的技能你不得不学,除非你不想干了。在学校的时候大部分人编程的目的都是为了通过考试或者找到一份好工作,真正靠自己兴趣支撑起来的很少,到了工作岗位之后我们编程更多的是因为工作的要求,相比于学校的来说会一般会更有挑战而且压力更大。在学校的时候,我们最重要的就是对自己负责,我们不断学习知识去武装自己,但是到了公司之后我们不光要对自己负责,更要对公司负责,毕竟公司出钱请你过来,不是让你一直 on beach 的。
-刚来公司的时候,因为公司要求,我换上了 Mac 电脑。由于之前一直用的是 Windows 系统,所以非常不习惯。刚开始用 Mac 系统的时候笨手笨脚,自己会很明显的感觉自己的编程效率降低了至少 3 成。当时内心还是挺不爽的,心里也总是抱怨为什么不直接用 Windows 系统或者 Linux 系统。不过也挺奇怪,大概一个星期之后,自己就开始慢慢适应使用 Mac 进行编程,甚至非常喜欢。我这里不想对比 Mac 和 Windows 编程体验哪一个更好,我觉得还是因人而异,相同价位的 Mac 的配置相比于 Windows确实要被甩几条街。不过 Mac 的编程和使用体验确实不错,当然你也可以选择使用 Linux 进行日常开发,相信一定很不错。 另外,Mac 不能玩一些主流网络游戏,对于一些克制不住自己想玩游戏的朋友是一个不错的选择。
+刚来公司的时候,因为公司要求,我换上了 Mac 电脑。由于之前一直用的是 Windows 系统,所以非常不习惯。刚开始用 Mac 系统的时候笨手笨脚,自己会很明显的感觉自己的编程效率降低了至少 3 成。当时内心还是挺不爽的,心里也总是抱怨为什么不直接用 Windows 系统或者 Linux 系统。不过也挺奇怪,大概一个星期之后,自己就开始慢慢适应使用 Mac 进行编程,甚至非常喜欢。我这里不想对比 Mac 和 Windows 编程体验哪一个更好,我觉得还是因人而异,相同价位的 Mac 的配置相比于 Windows 确实要被甩几条街。不过 Mac 的编程和使用体验确实不错,当然你也可以选择使用 Linux 进行日常开发,相信一定很不错。 另外,Mac 不能玩一些主流网络游戏,对于一些克制不住自己想玩游戏的朋友是一个不错的选择。
-不得不说 ThoughtWorks 的培训机制还是很不错的。应届生入职之后一般都会安排培训,与往年不同的是,今年的培训多了中国本地班(TWU-C)。作为本地班的第一期学员,说句心里话还是很不错。8周的培训,除了工作需要用到的基本技术比如ES6、SpringBoot等等之外,还会增加一些新员工基本技能的培训比如如何高效开会、如何给别人正确的提 Feedback、如何对代码进行重构、如何进行 TDD 等等。培训期间不定期的有活动,比如Weekend Trip、 City Tour、Cake time等等。最后三周还会有一个实际的模拟项目,这个项目基本和我们正式工作的实际项目差不多,我个人感觉很不错。目前这个项目已经正式完成了一个迭代,我觉得在做项目的过程中,收获最大的不是项目中使用的技术,而是如何进行团队合作、如何正确使用 Git 团队协同开发、一个完成的迭代是什么样子的、做项目的过程中可能遇到那些问题、一个项目运作的完整流程等等。
+不得不说 ThoughtWorks 的培训机制还是很不错的。应届生入职之后一般都会安排培训,与往年不同的是,今年的培训多了中国本地班(TWU-C)。作为本地班的第一期学员,说句心里话还是很不错。8 周的培训,除了工作需要用到的基本技术比如 ES6、SpringBoot 等等之外,还会增加一些新员工基本技能的培训比如如何高效开会、如何给别人正确的提 Feedback、如何对代码进行重构、如何进行 TDD 等等。培训期间不定期的有活动,比如 Weekend Trip、 City Tour、Cake time 等等。最后三周还会有一个实际的模拟项目,这个项目基本和我们正式工作的实际项目差不多,我个人感觉很不错。目前这个项目已经正式完成了一个迭代,我觉得在做项目的过程中,收获最大的不是项目中使用的技术,而是如何进行团队合作、如何正确使用 Git 团队协同开发、一个完成的迭代是什么样子的、做项目的过程中可能遇到那些问题、一个项目运作的完整流程等等。
-ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司的这段时间深有感触。培训期间,我们每个人会有一个 Trainer 负责,Trainer 就是日常带我们上课和做项目的同事,一个 Trainer 大概会负责5-6个人。Trainer不定期都会给我们最近表现的 Feedback( 反馈) ,我个人觉得这个并不是这是走走形式,Trainer 们都很负责,很多时候都是在下班之后找我们聊天。同事们也都很热心,如果你遇到问题,向别人询问,其他人如果知道的话一般都会毫无保留的告诉你,如果遇到大部分都不懂的问题,甚至会组织一次技术 Session 分享。上周五我在我们小组内进行了一次关于 Feign 远程调用的技术分享,因为 team 里面大家对这部分知识都不太熟悉,但是后面的项目进展大概率会用到这部分知识。我刚好研究了这部分内容,所以就分享给了组内的其他同事,以便于项目更好的进行。
+ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司的这段时间深有感触。培训期间,我们每个人会有一个 Trainer 负责,Trainer 就是日常带我们上课和做项目的同事,一个 Trainer 大概会负责 5 - 6 个人。Trainer 不定期都会给我们最近表现的 Feedback (反馈) ,我个人觉得这个并不是这是走走形式,Trainer 们都很负责,很多时候都是在下班之后找我们聊天。同事们也都很热心,如果你遇到问题,向别人询问,其他人如果知道的话一般都会毫无保留的告诉你,如果遇到大部分都不懂的问题,甚至会组织一次技术 Session 分享。上周五我在我们小组内进行了一次关于 Feign 远程调用的技术分享,因为 team 里面大家对这部分知识都不太熟悉,但是后面的项目进展大概率会用到这部分知识。我刚好研究了这部分内容,所以就分享给了组内的其他同事,以便于项目更好的进行。
- 另外,ThoughtWorks 也是一家非常提倡 Feedback( 反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
+另外,ThoughtWorks 也是一家非常提倡 Feedback (反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
-
+
-工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 pr 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
+工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 PR 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
-工作之后身边也会有很多厉害的人,多从他人身上学习我觉得是每个职场人都应该做的。这一届和我们一起培训的同事中,有一些技术很厉害的,也有一些技术虽然不是那么厉害,但是组织能力以及团队协作能力特别厉害的。有一个特别厉害的同事,在我们还在学 SpringBoot 各种语法的时候,他自己利用业余时间写了一个简化版的 SpringBoot ,涵盖了 Spring 的一些常用注解比如 `@RestController`、`@Autowried`、`@Pathvairable`、`@RestquestParam`等等(已经联系这位同事,想让他开源一下,后面会第一时间同步到公众号,期待一下吧!)。我觉得这位同事对于编程是真的有兴趣,他好像从初中就开始接触编程了,对于各种底层知识也非常感兴趣,自己写过实现过很多比较底层的东西。他的梦想是在 Github 上造一个 20k Star 以上的轮子。我相信以这位同事的能力一定会达成目标的,在这里祝福这位同事,希望他可以尽快实现这个目标。
+工作之后身边也会有很多厉害的人,多从他人身上学习我觉得是每个职场人都应该做的。这一届和我们一起培训的同事中,有一些技术很厉害的,也有一些技术虽然不是那么厉害,但是组织能力以及团队协作能力特别厉害的。有一个特别厉害的同事,在我们还在学 SpringBoot 各种语法的时候,他自己利用业余时间写了一个简化版的 SpringBoot ,涵盖了 Spring 的一些常用注解比如 `@RestController`、`@Autowried`、`@Pathvairable`、`@RestquestParam`等等(已经联系这位同事,想让他开源一下,后面会第一时间同步到公众号,期待一下吧!)。我觉得这位同事对于编程是真的有兴趣,他好像从初中就开始接触编程了,对于各种底层知识也非常感兴趣,自己写过实现过很多比较底层的东西。他的梦想是在 Github 上造一个 20k Star 以上的轮子。我相信以这位同事的能力一定会达成目标的,在这里祝福这位同事,希望他可以尽快实现这个目标。
-这是我入职一个多月之后的个人感受,很多地方都是一带而过,后面我会抽时间分享自己在公司或者业余学到的比较有用的知识给各位,希望看过的人都能有所收获。
\ No newline at end of file
+这是我入职一个多月之后的个人感受,很多地方都是一带而过,后面我会抽时间分享自己在公司或者业余学到的比较有用的知识给各位,希望看过的人都能有所收获。
diff --git a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
index 369c220f297..d737f1a10b4 100644
--- a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
+++ b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
@@ -1,24 +1,30 @@
-# 从毕业到入职半年的感受
+---
+title: 从毕业到入职半年的感受
+description: 应届生入职半年的工作感受,CRUD业务代码的价值、技术积累靠工作之余、从学校到职场的转变心得分享。
+category: 走近作者
+tag:
+ - 个人经历
+---
-如果大家看过我之前的介绍的话,就会知道我是 19 年毕业的几百万应届毕业生中的一员。这篇文章主要讲了一下我入职大半年的感受,文中有很多自己的主观感受,如果你们有任何不认同的地方都可以直接在评论区说出来, 会很尊重其他人的想法。
+如果大家看过我之前的介绍的话,就会知道我是 19 年毕业的几百万应届毕业生中的一员。这篇文章主要讲了一下我入职大半年的感受,文中有很多自己的主观感受,如果你们有任何不认同的地方都可以直接在评论区说出来,会很尊重其他人的想法。
简单说一下自己的情况吧!我目前是在一家外企,每天的工作和大部分人一样就是做开发。毕业到现在,差不多也算是工作半年多了,也已经过了公司 6 个月的试用期。目前在公司做过两个偏向于业务方向的项目,其中一个正在做。你很难想象我在公司做的两个业务项目的后端都没有涉及到分布式/微服务,没有接触到 Redis、Kafka 等等比较“高大上”的技术在项目中的实际运用。
-第一个项目做的是公司的内部项目——员工成长系统。抛去员工成长系统这个名字,实际上这个系统做的就是绩效考核比如你在某个项目组的表现。这个项目的技术是 Spring Boot+ JPA+Spring Security + K8S+Docker+React。第二个目前正在做的是一个集成游戏(cocos)、Web 管理端(Spring Boot+Vue)和小程序(Taro)项目。
+第一个项目做的是公司的内部项目——员工成长系统。抛去员工成长系统这个名字,实际上这个系统做的就是绩效考核比如你在某个项目组的表现。这个项目的技术是 Spring Boot+ JPA + Spring Security + K8S + Docker + React。第二个目前正在做的是一个集成游戏 (cocos)、Web 管理端 (Spring Boot + Vue) 和小程序 (Taro) 项目。
是的,我在工作中的大部分时间都和 CRUD 有关,每天也会写前端页面。之前我认识的一个朋友 ,他听说我做的项目中大部分内容都是写业务代码之后就非常纳闷,他觉得单纯写业务代码得不到提升?what?你一个应届生,连业务代码都写不好你给我说这个!所以,**我就很纳闷不知道为什么现在很多连业务代码都写不好的人为什么人听到 CRUD 就会反感?至少我觉得在我工作这段时间我的代码质量得到了提升、定位问题的能力有了很大的改进、对于业务有了更深的认识,自己也可以独立完成一些前端的开发了。**
其实,我个人觉得能把业务代码写好也没那么容易,抱怨自己天天做 CRUD 工作之前,看看自己 CRUD 的代码写好没。再换句话说,单纯写 CRUD 的过程中你搞懂了哪些你常用的注解或者类吗?这就像一个只会 `@Service`、`@Autowired`、`@RestController`等等最简单的注解的人说我已经掌握了 Spring Boot 一样。
-不知道什么时候开始大家都会觉得有实际使用 Redis、MQ 的经验就很牛逼了, 这可能和当前的面试环境有关系。你需要和别人有差异,你想进大厂的话,好像就必须要这些技术比较在行,好吧,没有好像,自信点来说对于大部分求职者这些技术都是默认你必备的了。
+不知道什么时候开始大家都会觉得有实际使用 Redis、MQ 的经验就很牛逼了,这可能和当前的面试环境有关系。你需要和别人有差异,你想进大厂的话,好像就必须要这些技术比较在行,好吧,没有好像,自信点来说对于大部分求职者这些技术都是默认你必备的了。
**实话实说,我在大学的时候就陷入过这个“伪命题”中**。在大学的时候,我大二因为加入了一个学校的偏技术方向的校媒才接触到 Java ,当时我们学习 Java 的目的就是开发一个校园通。 大二的时候,编程相当于才入门水平的我才接触 Java,花了一段时间才掌握 Java 基础。然后,就开始学习安卓开发。
-到了大三上学期,我才真正确定要走 Java 后台的方向,找 Java 后台的开发工作。学习了 3 个月左右的 WEB 开发基础之后,我就开始学习分布式方面内容比如 Redis、Dubbo 这些。我当时是通过看书+视频+博客的方式学习的,自学过程中通过看视频自己做过两个完整的项目,一个普通的业务系统,一个是分布式的系统。**我当时以为自己做完之后就很牛逼了,我觉得普通的 CRUD 工作已经不符合我当前的水平了。哈哈!现在看来,当时的我过于哈皮!**
+到了大三上学期,我才真正确定要走 Java 后台的方向,找 Java 后台的开发工作。学习了 3 个月左右的 WEB 开发基础之后,我就开始学习分布式方面内容比如 Redis、Dubbo 这些。我当时是通过看书 + 视频 + 博客的方式学习的,自学过程中通过看视频自己做过两个完整的项目,一个普通的业务系统,一个是分布式的系统。**我当时以为自己做完之后就很牛逼了,我觉得普通的 CRUD 工作已经不符合我当前的水平了。哈哈!现在看来,当时的我过于哈皮!**
-这不!到了大三暑假跟着老师一起做项目的时候就出问题了。大三的时候,我们跟着老师做的是一个绩效考核系统,业务复杂程度中等。这个项目的技术用的是:SSM+Shiro+JSP。当时,做这个项目的时候我遇到各种问题,各种我以为我会写的代码都不会写了,甚至我写一个简单的 CRUD 都要花费好几天的时间。所以,那时候我都是边复习边学习边写代码。虽然很累,但是,那时候学到了很多,也让我在技术面前变得更加踏实。我觉得这“**这个项目已经没有维护的可能性**”这句话是我对我过的这个项目最大的否定了。
+这不!到了大三暑假跟着老师一起做项目的时候就出问题了。大三的时候,我们跟着老师做的是一个绩效考核系统,业务复杂程度中等。这个项目的技术用的是:SSM + Shiro + JSP。当时,做这个项目的时候我遇到各种问题,各种我以为我会写的代码都不会写了,甚至我写一个简单的 CRUD 都要花费好几天的时间。所以,那时候我都是边复习边学习边写代码。虽然很累,但是,那时候学到了很多,也让我在技术面前变得更加踏实。我觉得这“**这个项目已经没有维护的可能性**”这句话是我对我过的这个项目最大的否定了。
-技术千变万化,掌握最核心的才是王道。我们前几年可能还在用 Spring 基于传统的 XML 开发,现在几乎大家都会用 Spring Boot 这个开发利器来提升开发速度,再比如几年前我们使用消息队列可能还在用 ActiveMQ,到今天几乎都没有人用它了,现在比较常用的就是 Rocket MQ、Kafka 。技术更新换代这么快的今天,你是无法把每一个框架/工具都学习一遍的, 。
+技术千变万化,掌握最核心的才是王道。我们前几年可能还在用 Spring 基于传统的 XML 开发,现在几乎大家都会用 Spring Boot 这个开发利器来提升开发速度,再比如几年前我们使用消息队列可能还在用 ActiveMQ,到今天几乎都没有人用它了,现在比较常用的就是 Rocket MQ、Kafka 。技术更新换代这么快的今天,你是无法把每一个框架/工具都学习一遍的。
**很多初学者上来就想通过做项目学习,特别是在公司,我觉得这个是不太可取的。** 如果的 Java 基础或者 Spring Boot 基础不好的话,建议自己先提前学习一下之后再开始看视频或者通过其他方式做项目。 **还有一点就是,我不知道为什么大家都会说边跟着项目边学习做的话效果最好,我觉得这个要加一个前提是你对这门技术有基本的了解或者说你对编程有了一定的了解。**
@@ -26,9 +32,9 @@
不知道其他公司的程序员是怎么样的?我感觉技术积累很大程度在乎平时,单纯依靠工作绝大部分情况只会加快自己做需求的熟练度,当然,写多了之后或多或少也会提升你对代码质量的认识(前提是你有这个意识)。
-工作之余,我会利用业余时间来学习自己想学的东西。工作中的例子就是我刚进公司的第一个项目用到了 Spring Security+JWT ,因为当时自己对于这个技术不太了解,然后就在工作之外大概花了一周的时间学习写了一个 Demo 分享了出来,Github 地址:https://github.com/Snailclimb/spring-security-jwt-guide 。以次为契机,我还分享了
+工作之余,我会利用业余时间来学习自己想学的东西。工作中的例子就是我刚进公司的第一个项目用到了 Spring Security + JWT ,因为当时自己对于这个技术不太了解,然后就在工作之外大概花了一周的时间学习写了一个 Demo 分享了出来,GitHub 地址:
+
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
diff --git a/docs/about-the-author/dog-that-copies-other-people-essay.md b/docs/about-the-author/dog-that-copies-other-people-essay.md
index 0587d0ee1ea..2ae67150843 100644
--- a/docs/about-the-author/dog-that-copies-other-people-essay.md
+++ b/docs/about-the-author/dog-that-copies-other-people-essay.md
@@ -1,34 +1,40 @@
-# 抄袭狗,你冬天睡觉脚必冷!!!
+---
+title: 抄袭狗,你冬天睡觉脚必冷!!!
+description: 原创文章被抄袭的无奈经历,知乎、CSDN多平台盗文现象吐槽,分享如何屏蔽低质量内容和维护原创权益。
+category: 走近作者
+tag:
+ - 杂谈
+---
抄袭狗真的太烦了。。。
听朋友说我的文章在知乎又被盗了,原封不动地被别人用来引流。
-
+
而且!!!这还不是最气的。
这人还在文末注明的原出处还不是我的。。。
-
+
也就是说 CSDN 有另外一位抄袭狗盗了我的这篇文章并声明了原创,知乎抄袭狗又原封不动地搬运了这位 CSDN 抄袭狗的文章。
真可谓离谱他妈给离谱开门,离谱到家了。
-
+
我打开知乎抄袭狗注明的原出处链接,好家伙,一模一样的内容,还表明了原创。
-
+
看了一下 CSDN 这位抄袭狗的文章,好家伙,把我高赞回答搬运了一个遍。。。真是很勤奋了。。。
CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范转载,各种收费下载的垃圾资源。这号称国内流量最大的技术网站贼恶心,吃香太难看,能不用就不要用吧!
-像我自己平时用 Google 搜索的时候,都是直接屏蔽掉 CSDN 这个站点的。只需要下载一个叫做 Personal Blocklist 的 Chrome 插件,然后将 blog.csdn.net 添加进黑名单就可以了。
+像我自己平时用 Google 搜索的时候,都是直接屏蔽掉 CSDN 这个站点的。只需要下载一个叫做 Personal Blocklist 的 Chrome 插件,然后将 blog.csdn.net 添加进黑名单就可以了。
-
+
我的文章基本被盗完了,关键是我自己发没有什么流量,反而是盗我文章的那些人比我这个原作者流量还大。
@@ -38,7 +44,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
看看 CSDN 热榜上的文章都是一些什么垃圾,不是各种广告就是一些毫无质量的拼凑文。
-
+
当然了,也有极少部分的高质量文章,比如涛哥、二哥、冰河、微观技术等博主的文章。
@@ -46,7 +52,6 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
今天提到的这篇被盗的文章曾经就被一个培训机构拿去做成了视频用来引流。
-
+
作为个体,咱也没啥办法,只能遇到一个举报一个。。。
-
diff --git a/docs/about-the-author/feelings-after-one-month-of-induction-training.md b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
index 9f81220150f..8ea32dd5c74 100644
--- a/docs/about-the-author/feelings-after-one-month-of-induction-training.md
+++ b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
@@ -1,19 +1,25 @@
-# 入职培训一个月后的感受
+---
+title: 入职培训一个月后的感受
+description: ThoughtWorks入职培训一个月感受,从Windows切换到Mac的适应、TWU培训内容、Feedback反馈文化等新人入职体验分享。
+category: 走近作者
+tag:
+ - 个人经历
+---
不知不觉已经入职一个多月了,在入职之前我没有在某个公司实习过或者工作过,所以很多东西刚入职工作的我来说还是比较新颖的。学校到职场的转变,带来了角色的转变,其中的差别因人而异。对我而言,在学校的时候课堂上老师课堂上教的东西,自己会根据自己的兴趣选择性接受,甚至很多课程你不想去上的话,还可以逃掉。到了公司就不一样了,公司要求你会的技能你不得不学,除非你不想干了。在学校的时候大部分人编程的目的都是为了通过考试或者找到一份好工作,真正靠自己兴趣支撑起来的很少,到了工作岗位之后我们编程更多的是因为工作的要求,相比于学校的来说会一般会更有挑战而且压力更大。在学校的时候,我们最重要的就是对自己负责,我们不断学习知识去武装自己,但是到了公司之后我们不光要对自己负责,更要对公司负责,毕竟公司出钱请你过来,不是让你一直 on beach 的。
-刚来公司的时候,因为公司要求,我换上了 Mac 电脑。由于之前一直用的是 Windows 系统,所以非常不习惯。刚开始用 Mac 系统的时候笨手笨脚,自己会很明显的感觉自己的编程效率降低了至少 3 成。当时内心还是挺不爽的,心里也总是抱怨为什么不直接用 Windows 系统或者 Linux 系统。不过也挺奇怪,大概一个星期之后,自己就开始慢慢适应使用 Mac 进行编程,甚至非常喜欢。我这里不想对比 Mac 和 Windows 编程体验哪一个更好,我觉得还是因人而异,相同价位的 Mac 的配置相比于 Windows确实要被甩几条街。不过 Mac 的编程和使用体验确实不错,当然你也可以选择使用 Linux 进行日常开发,相信一定很不错。 另外,Mac 不能玩一些主流网络游戏,对于一些克制不住自己想玩游戏的朋友是一个不错的选择。
+刚来公司的时候,因为公司要求,我换上了 Mac 电脑。由于之前一直用的是 Windows 系统,所以非常不习惯。刚开始用 Mac 系统的时候笨手笨脚,自己会很明显的感觉自己的编程效率降低了至少 3 成。当时内心还是挺不爽的,心里也总是抱怨为什么不直接用 Windows 系统或者 Linux 系统。不过也挺奇怪,大概一个星期之后,自己就开始慢慢适应使用 Mac 进行编程,甚至非常喜欢。我这里不想对比 Mac 和 Windows 编程体验哪一个更好,我觉得还是因人而异,相同价位的 Mac 的配置相比于 Windows 确实要被甩几条街。不过 Mac 的编程和使用体验确实不错,当然你也可以选择使用 Linux 进行日常开发,相信一定很不错。 另外,Mac 不能玩一些主流网络游戏,对于一些克制不住自己想玩游戏的朋友是一个不错的选择。
-不得不说 ThoughtWorks 的培训机制还是很不错的。应届生入职之后一般都会安排培训,与往年不同的是,今年的培训多了中国本地班(TWU-C)。作为本地班的第一期学员,说句心里话还是很不错。8周的培训,除了工作需要用到的基本技术比如ES6、SpringBoot等等之外,还会增加一些新员工基本技能的培训比如如何高效开会、如何给别人正确的提 Feedback、如何对代码进行重构、如何进行 TDD 等等。培训期间不定期的有活动,比如Weekend Trip、 City Tour、Cake time等等。最后三周还会有一个实际的模拟项目,这个项目基本和我们正式工作的实际项目差不多,我个人感觉很不错。目前这个项目已经正式完成了一个迭代,我觉得在做项目的过程中,收获最大的不是项目中使用的技术,而是如何进行团队合作、如何正确使用 Git 团队协同开发、一个完成的迭代是什么样子的、做项目的过程中可能遇到那些问题、一个项目运作的完整流程等等。
+不得不说 ThoughtWorks 的培训机制还是很不错的。应届生入职之后一般都会安排培训,与往年不同的是,今年的培训多了中国本地班(TWU-C)。作为本地班的第一期学员,说句心里话还是很不错。8 周的培训,除了工作需要用到的基本技术比如 ES6、SpringBoot 等等之外,还会增加一些新员工基本技能的培训比如如何高效开会、如何给别人正确的提 Feedback、如何对代码进行重构、如何进行 TDD 等等。培训期间不定期的有活动,比如 Weekend Trip、 City Tour、Cake time 等等。最后三周还会有一个实际的模拟项目,这个项目基本和我们正式工作的实际项目差不多,我个人感觉很不错。目前这个项目已经正式完成了一个迭代,我觉得在做项目的过程中,收获最大的不是项目中使用的技术,而是如何进行团队合作、如何正确使用 Git 团队协同开发、一个完成的迭代是什么样子的、做项目的过程中可能遇到那些问题、一个项目运作的完整流程等等。
-ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司的这段时间深有感触。培训期间,我们每个人会有一个 Trainer 负责,Trainer 就是日常带我们上课和做项目的同事,一个 Trainer 大概会负责5-6个人。Trainer不定期都会给我们最近表现的 Feedback( 反馈) ,我个人觉得这个并不是这是走走形式,Trainer 们都很负责,很多时候都是在下班之后找我们聊天。同事们也都很热心,如果你遇到问题,向别人询问,其他人如果知道的话一般都会毫无保留的告诉你,如果遇到大部分都不懂的问题,甚至会组织一次技术 Session 分享。上周五我在我们小组内进行了一次关于 Feign 远程调用的技术分享,因为 team 里面大家对这部分知识都不太熟悉,但是后面的项目进展大概率会用到这部分知识。我刚好研究了这部分内容,所以就分享给了组内的其他同事,以便于项目更好的进行。
+ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司的这段时间深有感触。培训期间,我们每个人会有一个 Trainer 负责,Trainer 就是日常带我们上课和做项目的同事,一个 Trainer 大概会负责 5 - 6 个人。Trainer 不定期都会给我们最近表现的 Feedback (反馈) ,我个人觉得这个并不是这是走走形式,Trainer 们都很负责,很多时候都是在下班之后找我们聊天。同事们也都很热心,如果你遇到问题,向别人询问,其他人如果知道的话一般都会毫无保留的告诉你,如果遇到大部分都不懂的问题,甚至会组织一次技术 Session 分享。上周五我在我们小组内进行了一次关于 Feign 远程调用的技术分享,因为 team 里面大家对这部分知识都不太熟悉,但是后面的项目进展大概率会用到这部分知识。我刚好研究了这部分内容,所以就分享给了组内的其他同事,以便于项目更好的进行。
- 另外,ThoughtWorks 也是一家非常提倡 Feedback( 反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
+另外,ThoughtWorks 也是一家非常提倡 Feedback (反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
-
+
-工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 pr 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
+工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 PR 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
-工作之后身边也会有很多厉害的人,多从他人身上学习我觉得是每个职场人都应该做的。这一届和我们一起培训的同事中,有一些技术很厉害的,也有一些技术虽然不是那么厉害,但是组织能力以及团队协作能力特别厉害的。有一个特别厉害的同事,在我们还在学 SpringBoot 各种语法的时候,他自己利用业余时间写了一个简化版的 SpringBoot ,涵盖了 Spring 的一些常用注解比如 `@RestController`、`@Autowried`、`@Pathvairable`、`@RestquestParam`等等(已经联系这位同事,想让他开源一下,后面会第一时间同步到公众号,期待一下吧!)。我觉得这位同事对于编程是真的有兴趣,他好像从初中就开始接触编程了,对于各种底层知识也非常感兴趣,自己写过实现过很多比较底层的东西。他的梦想是在 Github 上造一个 20k Star 以上的轮子。我相信以这位同事的能力一定会达成目标的,在这里祝福这位同事,希望他可以尽快实现这个目标。
+工作之后身边也会有很多厉害的人,多从他人身上学习我觉得是每个职场人都应该做的。这一届和我们一起培训的同事中,有一些技术很厉害的,也有一些技术虽然不是那么厉害,但是组织能力以及团队协作能力特别厉害的。有一个特别厉害的同事,在我们还在学 SpringBoot 各种语法的时候,他自己利用业余时间写了一个简化版的 SpringBoot ,涵盖了 Spring 的一些常用注解比如 `@RestController`、`@Autowried`、`@Pathvairable`、`@RestquestParam`等等(已经联系这位同事,想让他开源一下,后面会第一时间同步到公众号,期待一下吧!)。我觉得这位同事对于编程是真的有兴趣,他好像从初中就开始接触编程了,对于各种底层知识也非常感兴趣,自己写过实现过很多比较底层的东西。他的梦想是在 Github 上造一个 20k Star 以上的轮子。我相信以这位同事的能力一定会达成目标的,在这里祝福这位同事,希望他可以尽快实现这个目标。
-这是我入职一个多月之后的个人感受,很多地方都是一带而过,后面我会抽时间分享自己在公司或者业余学到的比较有用的知识给各位,希望看过的人都能有所收获。
\ No newline at end of file
+这是我入职一个多月之后的个人感受,很多地方都是一带而过,后面我会抽时间分享自己在公司或者业余学到的比较有用的知识给各位,希望看过的人都能有所收获。
diff --git a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
index 369c220f297..d737f1a10b4 100644
--- a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
+++ b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
@@ -1,24 +1,30 @@
-# 从毕业到入职半年的感受
+---
+title: 从毕业到入职半年的感受
+description: 应届生入职半年的工作感受,CRUD业务代码的价值、技术积累靠工作之余、从学校到职场的转变心得分享。
+category: 走近作者
+tag:
+ - 个人经历
+---
-如果大家看过我之前的介绍的话,就会知道我是 19 年毕业的几百万应届毕业生中的一员。这篇文章主要讲了一下我入职大半年的感受,文中有很多自己的主观感受,如果你们有任何不认同的地方都可以直接在评论区说出来, 会很尊重其他人的想法。
+如果大家看过我之前的介绍的话,就会知道我是 19 年毕业的几百万应届毕业生中的一员。这篇文章主要讲了一下我入职大半年的感受,文中有很多自己的主观感受,如果你们有任何不认同的地方都可以直接在评论区说出来,会很尊重其他人的想法。
简单说一下自己的情况吧!我目前是在一家外企,每天的工作和大部分人一样就是做开发。毕业到现在,差不多也算是工作半年多了,也已经过了公司 6 个月的试用期。目前在公司做过两个偏向于业务方向的项目,其中一个正在做。你很难想象我在公司做的两个业务项目的后端都没有涉及到分布式/微服务,没有接触到 Redis、Kafka 等等比较“高大上”的技术在项目中的实际运用。
-第一个项目做的是公司的内部项目——员工成长系统。抛去员工成长系统这个名字,实际上这个系统做的就是绩效考核比如你在某个项目组的表现。这个项目的技术是 Spring Boot+ JPA+Spring Security + K8S+Docker+React。第二个目前正在做的是一个集成游戏(cocos)、Web 管理端(Spring Boot+Vue)和小程序(Taro)项目。
+第一个项目做的是公司的内部项目——员工成长系统。抛去员工成长系统这个名字,实际上这个系统做的就是绩效考核比如你在某个项目组的表现。这个项目的技术是 Spring Boot+ JPA + Spring Security + K8S + Docker + React。第二个目前正在做的是一个集成游戏 (cocos)、Web 管理端 (Spring Boot + Vue) 和小程序 (Taro) 项目。
是的,我在工作中的大部分时间都和 CRUD 有关,每天也会写前端页面。之前我认识的一个朋友 ,他听说我做的项目中大部分内容都是写业务代码之后就非常纳闷,他觉得单纯写业务代码得不到提升?what?你一个应届生,连业务代码都写不好你给我说这个!所以,**我就很纳闷不知道为什么现在很多连业务代码都写不好的人为什么人听到 CRUD 就会反感?至少我觉得在我工作这段时间我的代码质量得到了提升、定位问题的能力有了很大的改进、对于业务有了更深的认识,自己也可以独立完成一些前端的开发了。**
其实,我个人觉得能把业务代码写好也没那么容易,抱怨自己天天做 CRUD 工作之前,看看自己 CRUD 的代码写好没。再换句话说,单纯写 CRUD 的过程中你搞懂了哪些你常用的注解或者类吗?这就像一个只会 `@Service`、`@Autowired`、`@RestController`等等最简单的注解的人说我已经掌握了 Spring Boot 一样。
-不知道什么时候开始大家都会觉得有实际使用 Redis、MQ 的经验就很牛逼了, 这可能和当前的面试环境有关系。你需要和别人有差异,你想进大厂的话,好像就必须要这些技术比较在行,好吧,没有好像,自信点来说对于大部分求职者这些技术都是默认你必备的了。
+不知道什么时候开始大家都会觉得有实际使用 Redis、MQ 的经验就很牛逼了,这可能和当前的面试环境有关系。你需要和别人有差异,你想进大厂的话,好像就必须要这些技术比较在行,好吧,没有好像,自信点来说对于大部分求职者这些技术都是默认你必备的了。
**实话实说,我在大学的时候就陷入过这个“伪命题”中**。在大学的时候,我大二因为加入了一个学校的偏技术方向的校媒才接触到 Java ,当时我们学习 Java 的目的就是开发一个校园通。 大二的时候,编程相当于才入门水平的我才接触 Java,花了一段时间才掌握 Java 基础。然后,就开始学习安卓开发。
-到了大三上学期,我才真正确定要走 Java 后台的方向,找 Java 后台的开发工作。学习了 3 个月左右的 WEB 开发基础之后,我就开始学习分布式方面内容比如 Redis、Dubbo 这些。我当时是通过看书+视频+博客的方式学习的,自学过程中通过看视频自己做过两个完整的项目,一个普通的业务系统,一个是分布式的系统。**我当时以为自己做完之后就很牛逼了,我觉得普通的 CRUD 工作已经不符合我当前的水平了。哈哈!现在看来,当时的我过于哈皮!**
+到了大三上学期,我才真正确定要走 Java 后台的方向,找 Java 后台的开发工作。学习了 3 个月左右的 WEB 开发基础之后,我就开始学习分布式方面内容比如 Redis、Dubbo 这些。我当时是通过看书 + 视频 + 博客的方式学习的,自学过程中通过看视频自己做过两个完整的项目,一个普通的业务系统,一个是分布式的系统。**我当时以为自己做完之后就很牛逼了,我觉得普通的 CRUD 工作已经不符合我当前的水平了。哈哈!现在看来,当时的我过于哈皮!**
-这不!到了大三暑假跟着老师一起做项目的时候就出问题了。大三的时候,我们跟着老师做的是一个绩效考核系统,业务复杂程度中等。这个项目的技术用的是:SSM+Shiro+JSP。当时,做这个项目的时候我遇到各种问题,各种我以为我会写的代码都不会写了,甚至我写一个简单的 CRUD 都要花费好几天的时间。所以,那时候我都是边复习边学习边写代码。虽然很累,但是,那时候学到了很多,也让我在技术面前变得更加踏实。我觉得这“**这个项目已经没有维护的可能性**”这句话是我对我过的这个项目最大的否定了。
+这不!到了大三暑假跟着老师一起做项目的时候就出问题了。大三的时候,我们跟着老师做的是一个绩效考核系统,业务复杂程度中等。这个项目的技术用的是:SSM + Shiro + JSP。当时,做这个项目的时候我遇到各种问题,各种我以为我会写的代码都不会写了,甚至我写一个简单的 CRUD 都要花费好几天的时间。所以,那时候我都是边复习边学习边写代码。虽然很累,但是,那时候学到了很多,也让我在技术面前变得更加踏实。我觉得这“**这个项目已经没有维护的可能性**”这句话是我对我过的这个项目最大的否定了。
-技术千变万化,掌握最核心的才是王道。我们前几年可能还在用 Spring 基于传统的 XML 开发,现在几乎大家都会用 Spring Boot 这个开发利器来提升开发速度,再比如几年前我们使用消息队列可能还在用 ActiveMQ,到今天几乎都没有人用它了,现在比较常用的就是 Rocket MQ、Kafka 。技术更新换代这么快的今天,你是无法把每一个框架/工具都学习一遍的, 。
+技术千变万化,掌握最核心的才是王道。我们前几年可能还在用 Spring 基于传统的 XML 开发,现在几乎大家都会用 Spring Boot 这个开发利器来提升开发速度,再比如几年前我们使用消息队列可能还在用 ActiveMQ,到今天几乎都没有人用它了,现在比较常用的就是 Rocket MQ、Kafka 。技术更新换代这么快的今天,你是无法把每一个框架/工具都学习一遍的。
**很多初学者上来就想通过做项目学习,特别是在公司,我觉得这个是不太可取的。** 如果的 Java 基础或者 Spring Boot 基础不好的话,建议自己先提前学习一下之后再开始看视频或者通过其他方式做项目。 **还有一点就是,我不知道为什么大家都会说边跟着项目边学习做的话效果最好,我觉得这个要加一个前提是你对这门技术有基本的了解或者说你对编程有了一定的了解。**
@@ -26,9 +32,9 @@
不知道其他公司的程序员是怎么样的?我感觉技术积累很大程度在乎平时,单纯依靠工作绝大部分情况只会加快自己做需求的熟练度,当然,写多了之后或多或少也会提升你对代码质量的认识(前提是你有这个意识)。
-工作之余,我会利用业余时间来学习自己想学的东西。工作中的例子就是我刚进公司的第一个项目用到了 Spring Security+JWT ,因为当时自己对于这个技术不太了解,然后就在工作之外大概花了一周的时间学习写了一个 Demo 分享了出来,Github 地址:https://github.com/Snailclimb/spring-security-jwt-guide 。以次为契机,我还分享了
+工作之余,我会利用业余时间来学习自己想学的东西。工作中的例子就是我刚进公司的第一个项目用到了 Spring Security + JWT ,因为当时自己对于这个技术不太了解,然后就在工作之外大概花了一周的时间学习写了一个 Demo 分享了出来,GitHub 地址: