diff --git "a/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-Cookie.md" "b/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-Cookie.md"
deleted file mode 100644
index fccea8ba37..0000000000
--- "a/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-Cookie.md"
+++ /dev/null
@@ -1,68 +0,0 @@
-### python高级爬虫实战之Headers信息校验-Cookie
-
-#### 一、什么是cookie
-
- 上期我们了解了User-Agent,这期我们来看下如何利用Cookie进行用户模拟登录从而进行网站数据的爬取。
-
-首先让我们来了解下什么是Cookie:
-
- Cookie指某些网站为了辨别用户身份、从而储存在用户本地终端上的数据。当客户端在第一次请求网站指定的首页或登录页进行登录之后,服务器端会返回一个Cookie值给客户端。如果客户端为浏览器,将自动将返回的cookie存储下来。当再次访问改网页的其他页面时,自动将cookie值在Headers里传递过去,服务器接受值后进行验证,如合法处理请求,否则拒绝请求。
-
-### 二、如何利用cookie
-
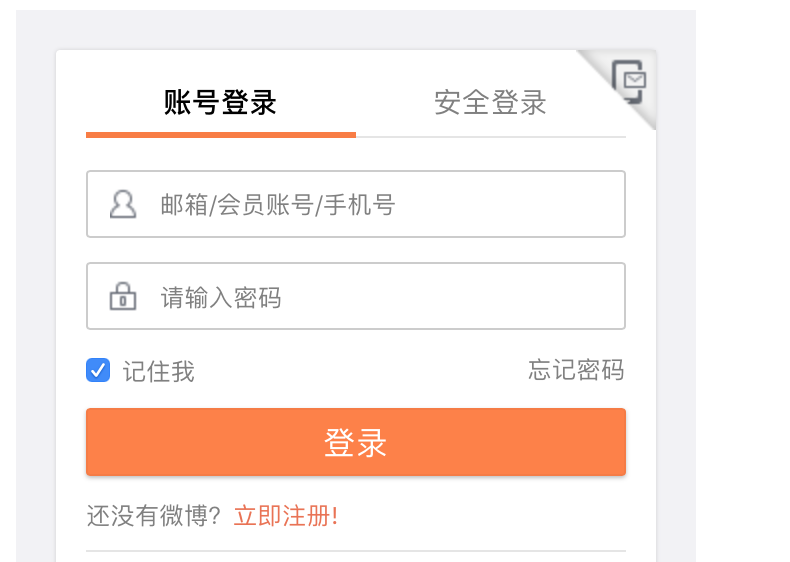
- 举个例子我们要去微博爬取相关数据,首先我们会遇到登录的问题,当然我们可以利用python其他的功能模块进行模拟登录,这里可能会涉及到验证码等一些反爬手段。
-
-
-
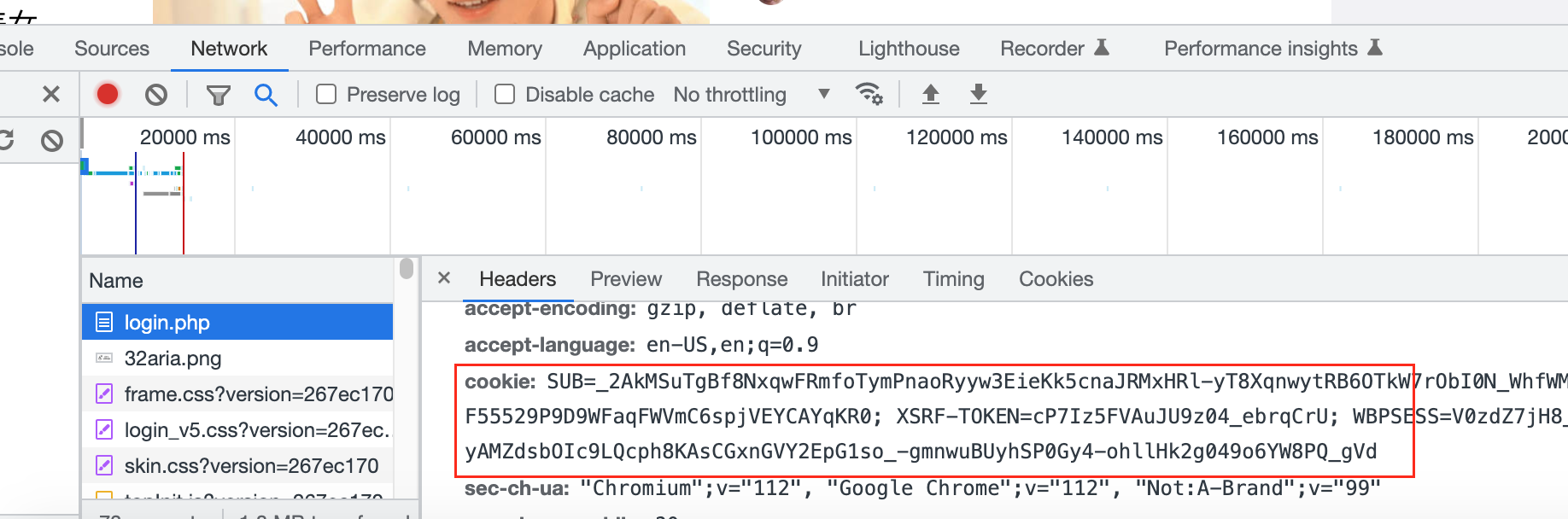
-换个思路,我们登录好了,通过开发者工具“右击” 检查(或者按F12) 获取到对应的cookie,那我们就可以绕个登录的页面,利用cookie继续用户模拟操作从而直接进行操作了。
-
-
-
-利用cookie实现模拟登录的两种方法:
-
-- [ ] 将cookie插入Headers请求头
-
- ```
- Headers={"cookie":"复制的cookie值"}
- ```
-
-
-
-- [ ] 将cookie直接作为requests方法的参数
-
-```
-cookie={"cookie":"复制的cookie值"}
-requests.get(url,cookie=cookie)
-```
-
-#### 三、利用selenium获取cookie,实现用户模拟登录
-
-实现方法:利用selenium模拟浏览器操作,输入用户名,密码 或扫码进行登录,获取到登录的cookie保存成文件,加载文件解析cookie实现用户模拟登录。
-
-```python
-from selenium import webdriver
-from time import sleep
-import json
-#selenium模拟浏览器获取cookie
-def getCookie:
- driver = webdriver.Chrome()
- driver.maximize_window()
- driver.get('https://weibo.co m/login.php')
- sleep(20) # 留时间进行扫码
- Cookies = driver.get_cookies() # 获取list的cookies
- jsCookies = json.dumps(Cookies) # 转换成字符串保存
- with open('cookies.txt', 'w') as f:
- f.write(jsCookies)
-
-def login:
- filename = 'cookies.txt'
- #创建MozillaCookieJar实例对象
- cookie = cookiejar.MozillaCookieJar()
- #从文件中读取cookie内容到变量
- cookie.load(filename, ignore_discard=True, ignore_expires=True)
- response = requests.get('https://weibo.co m/login.php',cookie=cookie)
-```
-
-#### 四、拓展思考
-
- 如果频繁使用一个账号进行登录爬取网站数据有可能导致服务器检查到异常,对当前账号进行封禁,这边我们就需要考虑cookie池的引入了。
\ No newline at end of file
diff --git "a/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-User-Agent.md" "b/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-User-Agent.md"
deleted file mode 100644
index 0fa29af29d..0000000000
--- "a/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-User-Agent.md"
+++ /dev/null
@@ -1,61 +0,0 @@
-### python高级爬虫实战之Headers信息校验-User-Agent
-
- User-agent 是当前网站反爬策略中最基础的一种反爬技术,服务器通过接收请求头中的user-agen的值来判断是否为正常用户访问还是爬虫程序。
-
- 下面举一个简单的例子 爬取我们熟悉的豆瓣网:
-
-```python
-import requests
-url='https://movie.douban.com/'
-resp=requests.get(url)
-print(resp.status_code)
-```
-
-运行结果得到status_code:418
-
-说明我们爬虫程序已经被服务器所拦截,无法正常获取相关网页数据。
-
-我们可以通过返回的状态码来了解服务器的相应情况
-
-- 100–199:信息反馈
-- 200–299:成功反馈
-- 300–399:重定向消息
-- 400–499:客户端错误响应
-- 500–599:服务器错误响应
-
-现在我们利用google chrome浏览器来打开豆瓣网,查看下网页。
-
-正常打开网页后,我们在页面任意地方右击“检查” 打开开发者工具。
-
- -
-
-
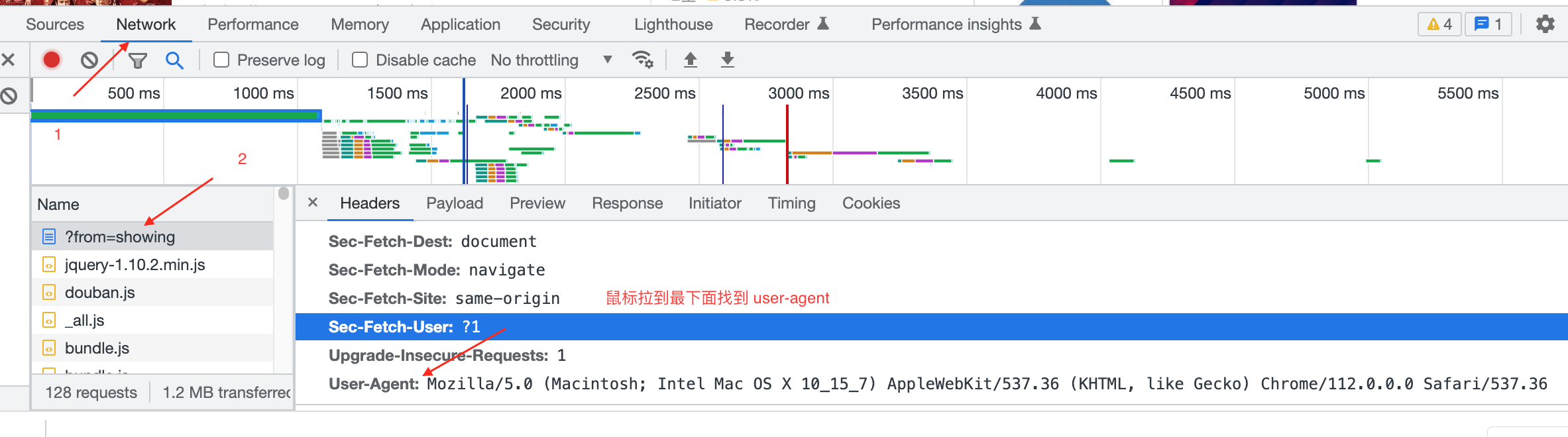
-选择:Network-在Name中随便找一个文件点击后,右边Headers显示内容,鼠标拉到最下面。
-
-
-
-User-Agent:
-
-Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
-
-我们把这段带到程序中再试下看效果如何。
-
-```python
-import requests
-url='https://movie.douban.com/'
-headers={
-"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
-}
-resp=requests.get(url,headers=headers)
-print(resp.status_code)
-```
-
-完美,执行后返回状态码200 ,说明已经成功骗过服务器拿到了想要的数据。
-
- 对于User-agent 我们可以把它当做一个身份证,这个身份证中会包含很多信息,通过这些信息可以识别出访问者。所以当服务器开启了user-agent认证时,就需要像服务器传递相关的信息进行核对。核对成功,服务器才会返回给用户正确的内容,否则就会拒绝服务。
-
-当然,对于Headers的相关信息还有很多,后续我们再一一讲解,下期见。
-
-
-
diff --git "a/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md" "b/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md"
deleted file mode 100644
index deb2f6262f..0000000000
--- "a/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md"
+++ /dev/null
@@ -1,91 +0,0 @@
-### 利用python实现小说自由
-
-#### 一、用到的相关模块
-
-1.reuqests模块
-
-安装reuqest模块,命令行输入:
-
-```
-pip install requests
-```
-
-2.xpath解析
-
- XPath 即为 XML 路径语言,它是一种用来确定 XML (标准通用标记语言子集)文档中某部分位置的语言。XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于 XPointer 与 XSL 间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
-
- 简单的来说:Xpath(XML Path Language)是一门在 XML 和 HTML 文档中查找信息的语言,可用来在 XML 和 HTML 文档中对元素和属性进行遍历。
-
- xml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
-
-安装xml:
-
-```
-pip install lxml
-```
-
-
-
-#### 二、实现步骤
-
-1.首先我们打开一个小说的网址:https://www.qu-la.com/booktxt/17437775116/
-
-2.右击“检查” 查看下这个网页的相关代码情况
-
-
-
-
-
-选择:Network-在Name中随便找一个文件点击后,右边Headers显示内容,鼠标拉到最下面。
-
-
-
-User-Agent:
-
-Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
-
-我们把这段带到程序中再试下看效果如何。
-
-```python
-import requests
-url='https://movie.douban.com/'
-headers={
-"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
-}
-resp=requests.get(url,headers=headers)
-print(resp.status_code)
-```
-
-完美,执行后返回状态码200 ,说明已经成功骗过服务器拿到了想要的数据。
-
- 对于User-agent 我们可以把它当做一个身份证,这个身份证中会包含很多信息,通过这些信息可以识别出访问者。所以当服务器开启了user-agent认证时,就需要像服务器传递相关的信息进行核对。核对成功,服务器才会返回给用户正确的内容,否则就会拒绝服务。
-
-当然,对于Headers的相关信息还有很多,后续我们再一一讲解,下期见。
-
-
-
diff --git "a/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md" "b/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md"
deleted file mode 100644
index deb2f6262f..0000000000
--- "a/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md"
+++ /dev/null
@@ -1,91 +0,0 @@
-### 利用python实现小说自由
-
-#### 一、用到的相关模块
-
-1.reuqests模块
-
-安装reuqest模块,命令行输入:
-
-```
-pip install requests
-```
-
-2.xpath解析
-
- XPath 即为 XML 路径语言,它是一种用来确定 XML (标准通用标记语言子集)文档中某部分位置的语言。XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于 XPointer 与 XSL 间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
-
- 简单的来说:Xpath(XML Path Language)是一门在 XML 和 HTML 文档中查找信息的语言,可用来在 XML 和 HTML 文档中对元素和属性进行遍历。
-
- xml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
-
-安装xml:
-
-```
-pip install lxml
-```
-
-
-
-#### 二、实现步骤
-
-1.首先我们打开一个小说的网址:https://www.qu-la.com/booktxt/17437775116/
-
-2.右击“检查” 查看下这个网页的相关代码情况
-
-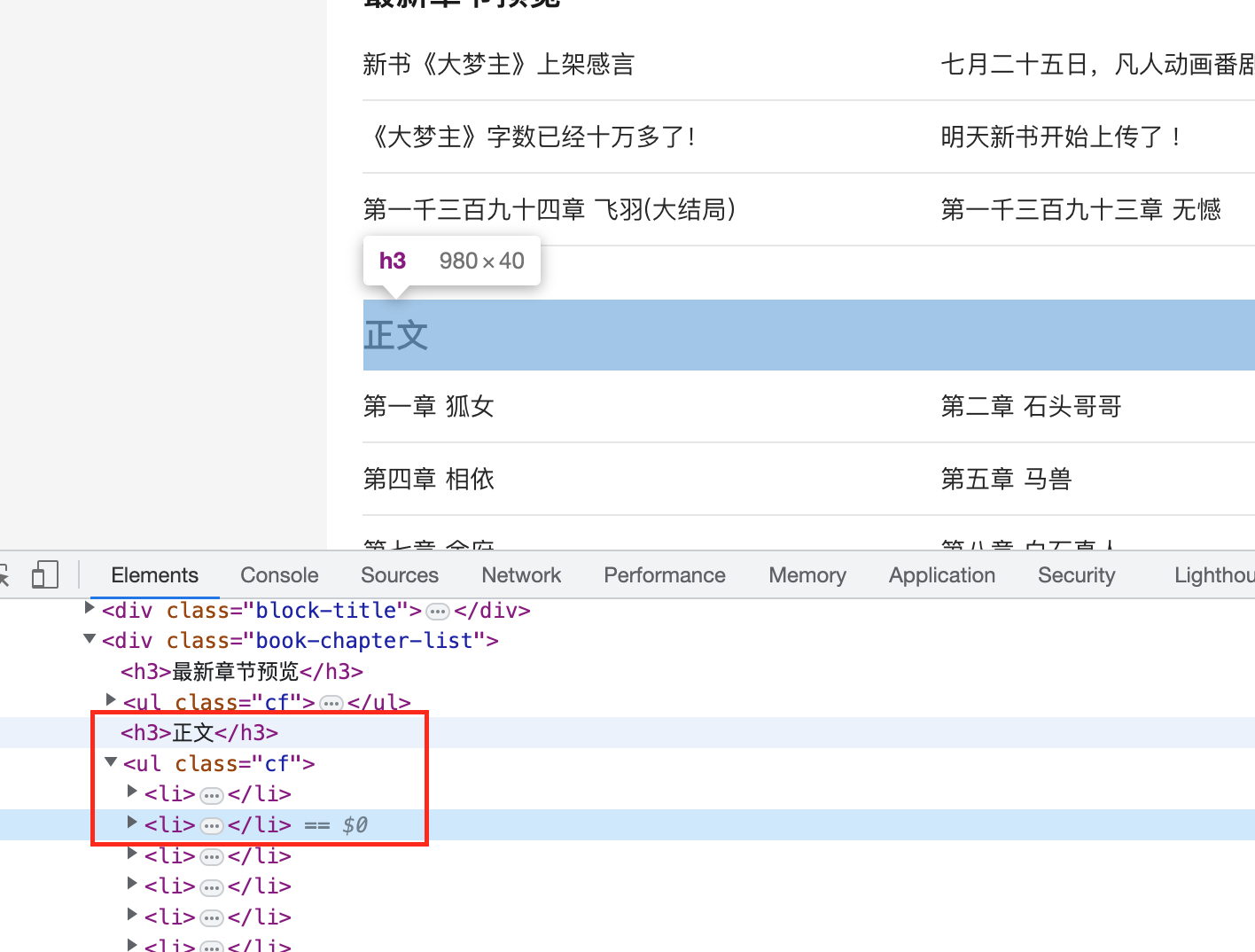 -
-我们可以发现所有的内容都被包裹在
-
-通过xpath 解析出每个章节的标题,和链接。
-
-3.根据对应的链接获取每个章节的文本。同样的方法找到章节文本的具体位置
-
-//*[@id="txt"]
-
-
-
-我们可以发现所有的内容都被包裹在
-
-通过xpath 解析出每个章节的标题,和链接。
-
-3.根据对应的链接获取每个章节的文本。同样的方法找到章节文本的具体位置
-
-//*[@id="txt"]
-
-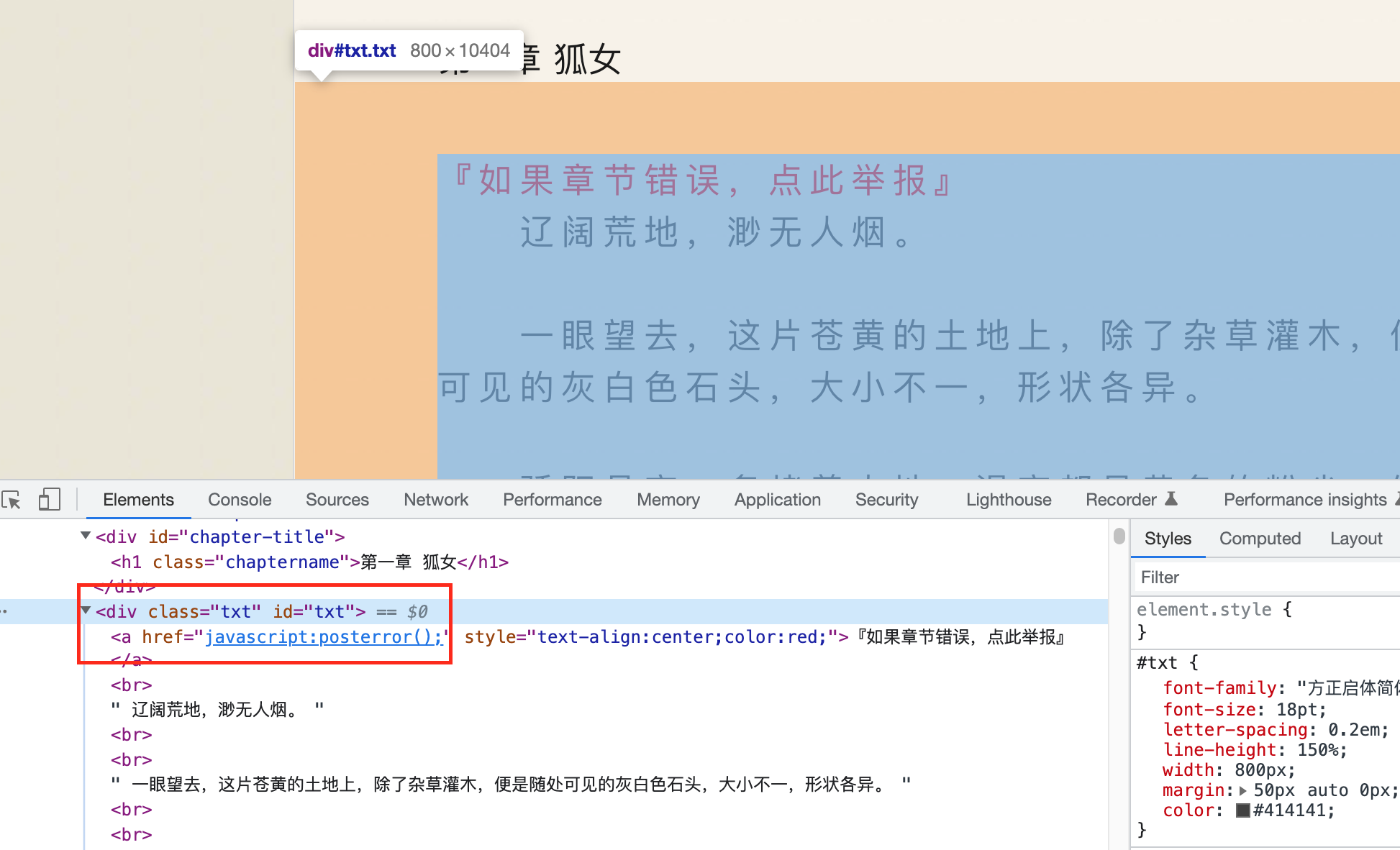 -
-3.for 循环获取所有链接的文本,保存为Txt文件。
-
-#### 三、代码展示
-
-```python
-import requests
-from lxml import etree
-def getNovel():
- headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'};
- html = requests.get('https://www.qu-la.com/booktxt/17437775116/',headers=headers).content
- doc=etree.HTML(html)
- contents=doc.xpath('//*[ @id="list"]/div[3]/ul[2]') #获取到小说的所有章节
- for content in contents:
- links=content.xpath('li/a/@href') #获取每个章节的链接
- for link in links: #循环处理每个章节
- url='https://www.qu-la.com'+link #拼接章节url
- html=requests.get(url).text
- doc=etree.HTML(html)
- content = doc.xpath('//*[@id="txt"]/text()') #获取章节的正文
- title = doc.xpath('//*[@id="chapter-title"]/h1/text()') #获取标题
- #所有的保存到一个文件里面
- with open('books/凡人修仙之仙界篇.txt', 'a') as file:
- file.write(title[0])
- print('正在下载{}'.format(title[0]))
- for items in content:
- file.write(item)
-
- print('下载完成')
-getNovel() #调用函数
-```
-
-#### 四、拓展思考
-
-1.写一个搜索界面,用户输入书名自主下载对应的小说。
-
-2.引入多进程异步下载,提高小说的下载速度。
-
-
-
diff --git a/README.md b/README.md
index 8ad293ad89..8e1fc968d4 100755
--- a/README.md
+++ b/README.md
@@ -16,14 +16,24 @@
更多精彩内容将发布在公众号 **JavaEdge**,公众号提供大量求职面试资料,后台回复 "面试" 即可领取。
本号系统整理了Java高级工程师必备技能点,帮你理清纷杂面试知识点,有的放矢。
+我本人也是基于这些知识体系,在各种求职征途中拿到百度、携程、华为、中兴、顺丰、帆软、货拉拉等offer。
+
+
-
-3.for 循环获取所有链接的文本,保存为Txt文件。
-
-#### 三、代码展示
-
-```python
-import requests
-from lxml import etree
-def getNovel():
- headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'};
- html = requests.get('https://www.qu-la.com/booktxt/17437775116/',headers=headers).content
- doc=etree.HTML(html)
- contents=doc.xpath('//*[ @id="list"]/div[3]/ul[2]') #获取到小说的所有章节
- for content in contents:
- links=content.xpath('li/a/@href') #获取每个章节的链接
- for link in links: #循环处理每个章节
- url='https://www.qu-la.com'+link #拼接章节url
- html=requests.get(url).text
- doc=etree.HTML(html)
- content = doc.xpath('//*[@id="txt"]/text()') #获取章节的正文
- title = doc.xpath('//*[@id="chapter-title"]/h1/text()') #获取标题
- #所有的保存到一个文件里面
- with open('books/凡人修仙之仙界篇.txt', 'a') as file:
- file.write(title[0])
- print('正在下载{}'.format(title[0]))
- for items in content:
- file.write(item)
-
- print('下载完成')
-getNovel() #调用函数
-```
-
-#### 四、拓展思考
-
-1.写一个搜索界面,用户输入书名自主下载对应的小说。
-
-2.引入多进程异步下载,提高小说的下载速度。
-
-
-
diff --git a/README.md b/README.md
index 8ad293ad89..8e1fc968d4 100755
--- a/README.md
+++ b/README.md
@@ -16,14 +16,24 @@
更多精彩内容将发布在公众号 **JavaEdge**,公众号提供大量求职面试资料,后台回复 "面试" 即可领取。
本号系统整理了Java高级工程师必备技能点,帮你理清纷杂面试知识点,有的放矢。
+我本人也是基于这些知识体系,在各种求职征途中拿到百度、携程、华为、中兴、顺丰、帆软、货拉拉等offer。
+
+ ## 3 笔者简介
+
### [阿里云栖社区博客专家](https://yq.aliyun.com/users/article?spm=a2c4e.8091938.headeruserinfo.3.65993d6eqaQ0O6)
+
+
### [腾讯云自媒体邀约计划作者](https://cloud.tencent.com/developer/user/1752328)
+
+
+
+
## 3 笔者简介
+
### [阿里云栖社区博客专家](https://yq.aliyun.com/users/article?spm=a2c4e.8091938.headeruserinfo.3.65993d6eqaQ0O6)
+
+
### [腾讯云自媒体邀约计划作者](https://cloud.tencent.com/developer/user/1752328)
+
+
+
+
-## 4 目录结构
+## 4 目录结构(不断优化中)
| 数据结构与算法 | 操作系统 | 网络 | 面向对象 | 数据存储 | Java | 架构设计 | 框架 | 编程规范 | 职业规划 |
| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :-------: | :-------:| :------:|
@@ -83,6 +93,15 @@
### :memo: 职业规划
+## QQ 技术交流群
+
+为大家提供一个学习交流平台,在这里你可以自由地讨论技术问题。
+
+ +
+## 微信交流群
+
+
+## 微信交流群
+ +
### 本人微信
+
### 本人微信
 @@ -95,17 +114,4 @@
### 绘图工具
- [draw.io](https://www.draw.io/)
-- keynote
-
-再分享我整理汇总的一些 Java 面试相关资料(亲自验证,严谨科学!别再看网上误导人的垃圾面试题!!!),助你拿到更多 offer!
-
-
-
-[点击获取更多经典必读电子书!](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247497273&idx=1&sn=b0f1e2e03cd7de3ce5d93cc8793d6d88&chksm=fa832459cdf4ad4fb046c0beb7e87ecea48f338278846679ef65238af45f0a135720e7061002&token=766333302&lang=zh_CN#rd)
-
-2023年最新Java学习路线一条龙:
-
-[](https://www.nowcoder.com/discuss/353159357007339520?sourceSSR=users)
-
-
-再给大家推荐一个学习 前后端软件开发 和准备Java 面试的公众号[【JavaEdge】](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247498257&idx=1&sn=b09d88691f9bfd715e000b69ef61227e&chksm=fa832871cdf4a1675d4491727399088ca488fa13e0a3cdf2ece3012265e5a3ef273dff540879&token=766333302&lang=zh_CN#rd)(强烈推荐!)
+- keynote
\ No newline at end of file
diff --git a/rename.md b/rename.md
new file mode 100644
index 0000000000..58e3cb0fb7
--- /dev/null
+++ b/rename.md
@@ -0,0 +1,403 @@
+管理类命名
+写代码,少不了对统一资源的管理,清晰的启动过程可以有效的组织代码。为了让程序运行起来,少不了各种资源的注册、调度,少不了公共集合资源的管理。
+
+Bootstrap,Starter
+一般作为程序启动器使用,或者作为启动器的基类。通俗来说,可以认为是main函数的入口。
+
+AbstractBootstrap
+ServerBootstrap
+MacosXApplicationStarter
+DNSTaskStarter
+Processor
+某一类功能的处理器,用来表示某个处理过程,是一系列代码片段的集合。如果你不知道一些顺序类的代码怎么命名,就可以使用它,显得高大上一些。
+
+CompoundProcessor
+BinaryComparisonProcessor
+DefaultDefaultValueProcessor
+Manager
+对有生命状态的对象进行管理,通常作为某一类资源的管理入口。
+
+AccountManager
+DevicePolicyManager
+TransactionManager
+Holder
+表示持有某个或者某类对象的引用,并可以对其进行统一管理。多见于不好回收的内存统一处理,或者一些全局集合容器的缓存。
+
+QueryHolder
+InstructionHolder
+ViewHolder
+Factory
+毫无疑问,工厂模式的命名,耳熟能详。尤其是Spring中,多不胜数。
+
+SessionFactory
+ScriptEngineFactory
+LiveCaptureFactory
+Provider
+Provider = Strategy + Factory Method。它更高级一些,把策略模式和方法工厂揉在了一块,让人用起来很顺手。Provider一般是接口或者抽象类,以便能够完成子实现。
+
+AccountFeatureProvider
+ApplicationFeatureProviderImpl
+CollatorProvider
+Registrar
+注册并管理一系列资源。
+
+ImportServiceRegistrar
+IKryoRegistrar
+PipelineOptionsRegistrar
+Engine
+一般是核心模块,用来处理一类功能。引擎是个非常高级的名词,一般的类是没有资格用它的。
+
+ScriptEngine
+DataQLScriptEngine
+C2DEngine
+Service
+某个服务。太简单,不忍举例。范围太广,不要滥用哦。
+
+IntegratorServiceImpl
+ISelectionService
+PersistenceService
+Task
+某个任务。通常是个runnable
+
+WorkflowTask
+FutureTask
+ForkJoinTask
+传播类命名
+为了完成一些统计类或者全局类的功能,有些参数需要一传到底。传播类的对象就可以通过统一封装的方式进行传递,并在合适的地方进行拷贝或者更新。
+
+Context
+如果你的程序执行,有一些变量,需要从函数执行的入口开始,一直传到大量子函数执行完毕之后。这些变量或者集合,如果以参数的形式传递,将会让代码变得冗长无比。这个时候,你就可以把变量统一塞到Context里面,以单个对象的形式进行传递。
+
+在Java中,由于ThreadLocal的存在,Context甚至可以不用在参数之间进行传递。
+
+AppContext
+ServletContext
+ApplicationContext
+Propagator
+传播,繁殖。用来将context中传递的值进行复制,添加,清除,重置,检索,恢复等动作。通常,它会提供一个叫做propagate的方法,实现真正的变量管理。
+
+TextMapPropagator
+FilePropagator
+TransactionPropagator
+回调类命名
+使用多核可以增加程序运行的效率,不可避免的引入异步化。我们需要有一定的手段,获取异步任务执行的结果,对任务执行过程中的关键点进行检查。回调类API可以通过监听、通知等形式,获取这些事件。
+
+Handler,Callback,Trigger,Listener
+callback通常是一个接口,用于响应某类消息,进行后续处理;Handler通常表示持有真正消息处理逻辑的对象,它是有状态的;tigger触发器代表某类事件的处理,属于Handler,通常不会出现在类的命名中;Listener的应用更加局限,通常在观察者模式中用来表示特定的含义。
+
+ChannelHandler
+SuccessCallback
+CronTrigger
+EventListener
+Aware
+Aware就是感知的意思,一般以该单词结尾的类,都实现了Aware接口。拿spring来说,Aware 的目的是为了让bean获取spring容器的服务。具体回调方法由子类实现,比如ApplicationContextAware。它有点回调的意思。
+
+ApplicationContextAware
+ApplicationStartupAware
+ApplicationEventPublisherAware
+监控类命名
+现在的程序都比较复杂,运行状态监控已经成为居家必备之良品。监控数据的收集往往需要侵入到程序的边边角角,如何有效的与正常业务进行区分,是非常有必要的。
+
+Metric
+表示监控数据。不要用Monitor了,比较丑。
+
+TimelineMetric
+HistogramMetric
+Metric
+Estimator
+估计,统计。用于计算某一类统计数值的计算器。
+
+ConditionalDensityEstimator
+FixedFrameRateEstimator
+NestableLoadProfileEstimator
+Accumulator
+累加器的意思。用来缓存累加的中间计算结果,并提供读取通道。
+
+AbstractAccumulator
+StatsAccumulator
+TopFrequencyAccumulator
+Tracker
+一般用于记录日志或者监控值,通常用于apm中。
+
+VelocityTracker
+RocketTracker
+MediaTracker
+内存管理类命名
+如果你的应用用到了自定义的内存管理,那么下面这些名词是绕不开的。比如Netty,就实现了自己的内存管理机制。
+
+Allocator
+与存储相关,通常表示内存分配器或者管理器。如果你得程序需要申请有规律得大块内存,allocator是你得不二选择。
+
+AbstractByteBufAllocator
+ArrayAllocator
+RecyclingIntBlockAllocator
+Chunk
+表示一块内存。如果你想要对一类存储资源进行抽象,并统一管理,可以采用它。
+
+EncryptedChunk
+ChunkFactory
+MultiChunk
+Arena
+英文是舞台、竞技场的意思。由于Linux把它用在内存管理上发扬光大,它普遍用于各种存储资源的申请、释放与管理。为不同规格的存储chunk提供舞台,好像也是非常形象的表示。
+
+关键是,这个词很美,作为后缀让类名显得很漂亮。
+
+BookingArena
+StandaloneArena
+PoolArena
+Pool
+表示池子。内存池,线程池,连接池,池池可用。
+
+ConnectionPool
+ObjectPool
+MemoryPool
+过滤检测类命名
+程序收到的事件和信息是非常多的,有些是合法的,有些需要过滤扔掉。根据不同的使用范围和功能性差别,过滤操作也有多种形式。你会在框架类代码中发现大量这样的名词。
+
+Pipeline,Chain
+一般用在责任链模式中。Netty,Spring MVC,Tomcat等都有大量应用。通过将某个处理过程加入到责任链的某个位置中,就可以接收前面处理过程的结果,强制添加或者改变某些功能。就像Linux的管道操作一样,最终构造出想要的结果。
+
+Pipeline
+ChildPipeline
+DefaultResourceTransformerChain
+FilterChain
+Filter
+过滤器,用来筛选某些满足条件的数据集,或者在满足某些条件的时候执行一部分逻辑。如果和责任链连接起来,则通常能够实现多级的过滤。
+
+FilenameFilter
+AfterFirstEventTimeFilter
+ScanFilter
+Interceptor
+拦截器,其实和Filter差不多。不过在Tomcat中,Interceptor可以拿到controller对象,但filter不行。拦截器是被包裹在过滤器中。
+
+HttpRequestInterceptor
+Evaluator
+英文里是评估器的意思。可用于判断某些条件是否成立,一般内部方法evaluate会返回bool类型。比如你传递进去一个非常复杂的对象,或者字符串,进行正确与否的判断。
+
+ScriptEvaluator
+SubtractionExpressionEvaluator
+StreamEvaluator
+Detector
+探测器。用来管理一系列探测性事件,并在发生的时候能够进行捕获和响应。比如Android的手势检测,温度检测等。
+
+FileHandlerReloadingDetector
+TransformGestureDetector
+ScaleGestureDetector
+结构类命名
+除了基本的数据结构,如数组、链表、队列、栈等,其他更高一层的常见抽象类,能够大量减少大家的交流,并能封装常见的变化。
+
+Cache
+这个没啥好说的,就是缓存。大块的缓存。常见的缓存算法有LRU、LFU、FIFO等。
+
+LoadingCache
+EhCacheCache
+Buffer
+buffer是缓冲,不同于缓存,它一般用在数据写入阶段。
+
+ByteBuffer
+RingBuffer
+DirectByteBuffer
+Composite
+将相似的组件进行组合,并以相同的接口或者功能进行暴露,使用者不知道这到底是一个组合体还是其他个体。
+
+CompositeData
+CompositeMap
+ScrolledComposite
+Wrapper
+用来包装某个对象,做一些额外的处理,以便增加或者去掉某些功能。
+
+IsoBufferWrapper
+ResponseWrapper
+MavenWrapperDownloader
+Option, Param,Attribute
+用来表示配置信息。说实话,它和Properties的区别并不大,但由于Option通常是一个类,所以功能可以扩展的更强大一些。它通常比Config的级别更小,关注的也是单个属性的值。Param一般是作为参数存在,对象生成的速度要快一些。
+
+SpecificationOption
+SelectOption
+AlarmParam
+ModelParam
+Tuple
+元组的概念。由于Java中缺乏元组结构,我们通常会自定义这样的类。
+
+Tuple2
+Tuple3
+Aggregator
+聚合器,可以做一些聚合计算。比如分库分表中的sum,max,min等聚合函数的汇集。
+
+BigDecimalMaxAggregator
+PipelineAggregator
+TotalAggregator
+Iterator
+迭代器。可以实现Java的迭代器接口,也可以有自己的迭代方式。在数据集很大的时候,需要进行深度遍历,迭代器可以说是必备的。使用迭代器还可以在迭代过程中安全的删除某些元素。
+
+BreakIterator
+StringCharacterIterator
+Batch
+某些可以批量执行的请求或者对象。
+
+SavedObjectBatch
+BatchRequest
+Limiter
+限流器,使用漏桶算法或者令牌桶来完成平滑的限流。
+
+DefaultTimepointLimiter
+RateLimiter
+TimeBasedLimiter
+常见设计模式命名
+设计模式是名词的重灾区,这里只列出最常使用的几个。
+
+Strategy
+将抽象部分与它的实现部分分离,使它们都可以独立地变化。策略模式。相同接口,不同实现类,同一方法结果不同,实现策略不同。比如一个配置文件,是放在xml里,还是放在json文件里,都可以使用不同的provider去命名。
+
+RemoteAddressStrategy
+StrategyRegistration
+AppStrategy
+Adapter
+将一个类的接口转换为客户希望的另一个接口,Adapter模式使得原本由于接口不兼容而不能一起工作的那些类一起工作。
+
+不过,相对于传统的适配器进行api转接,如果你的某个Handler里面方法特别的多,可以使用Adapter实现一些默认的方法进行0适配。那么其他类使用的时候,只需要继承Adapter,然后重写他想要重写的方法就可以了。这也是Adapter的常见用法。
+
+ExtendedPropertiesAdapter
+ArrayObjectAdapter
+CardGridCursorAdapter
+Action,Command
+将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化,对请求排队或记录请求日志,以及支持可撤销的操作。
+
+用来表示一系列动作指令,用来实现命令模式,封装一系列动作或者功能。Action一般用在UI操作上,后端框架可以无差别的使用。
+
+在DDD的概念中,CQRS的Command的C,既为Command。
+
+DeleteAction
+BoardCommand
+Event
+表示一系列事件。一般的,在语义上,Action,Command等,来自于主动触发;Event来自于被动触发。
+
+ObservesProtectedEvent
+KeyEvent
+Delegate
+代理或者委托模式。委托模式是将一件属于委托者做的事情,交给另外一个被委托者来处理。
+
+LayoutlibDelegate
+FragmentDelegate
+Builder
+将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
+
+构建者模式的标准命名。比如StringBuilder。当然StringBuffer是个另类。这也说明了,规则是人定的,人也可以破坏。
+
+JsonBuilder
+RequestBuilder
+Template
+模板方法类的命名。定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
+
+JDBCTemplate
+Proxy
+代理模式。为其他对象提供一种代理以控制对这个对象的访问。
+
+ProxyFactory
+SlowQueryProxy
+解析类命名
+写代码要涉及到大量的字符串解析、日期解析、对象转换等。根据语义和使用场合的区别,它们也分为多种。
+
+Converter,Resolver
+转换和解析。一般用于不同对象之间的格式转换,把一类对象转换成另一类。注意它们语义上的区别,一般特别复杂的转换或者有加载过程的需求,可以使用Resolver。
+
+DataSetToListConverter
+LayoutCommandLineConverter
+InitRefResolver
+MustacheViewResolver
+Parser
+用来表示非常复杂的解析器,比如解析DSL。
+
+SQLParser
+JSONParser
+Customizer
+用来表示对某个对象进行特别的配置。由于这些配置过程特别的复杂,值得单独提取出来进行自定义设置。
+
+ContextCustomizer
+DeviceFieldCustomizer
+Formatter
+格式化类。主要用于字符串、数字或者日期的格式化处理工作。
+
+DateFormatter
+StringFormatter
+网络类命名
+网络编程的同学,永远绕不过去的几个名词。
+
+Packet
+通常用于网络编程中的数据包。
+
+DhcpPacket
+PacketBuffer
+Protocol
+同样用户网络编程中,用来表示某个协议。
+
+RedisProtocol
+HttpProtocol
+Encoder、Decoder、Codec
+编码解码器
+
+RedisEncoder
+RedisDecoder
+RedisCodec
+Request,Response
+一般用于网络请求的进和出。如果你用在非网络请求的方法上,会显得很怪异。
+
+CRUD命名
+这个就有意思多了,统一的Controller,Service,Repository,没什么好说的。但你一旦用了DDD,那就得按照DDD那一套的命名来。
+
+由于DDD不属于通用编程范畴,它的名词就不多做介绍了。
+
+其他
+Util,Helper
+都表示工具类,Util一般是无状态的,Helper以便需要创建实例才能使用。但是一般没有使用Tool作为后缀的。
+
+HttpUtil
+TestKeyFieldHelper
+CreationHelper
+Mode,Type
+看到mode这个后缀,就能猜到这个类大概率是枚举。它通常把常见的可能性都列到枚举类里面,其他地方就可以引用这个Mode。
+
+OperationMode
+BridgeMode
+ActionType
+Invoker,Invocation
+invoker是一类接口,通常会以反射或者触发的方式,执行一些具体的业务逻辑。通过抽象出invoke方法,可以在invoke执行之前对入参进行记录或者处理;在invoke执行之后对结果和异常进行处理,是AOP中常见的操作方式。
+
+MethodInvoker
+Invoker
+ConstructorInvocation
+Initializer
+如果你的应用程序,需要经过大量的初始化操作才能启动,那就需要把它独立出来,专门处理初始化动作。
+
+MultiBackgroundInitialize
+ApplicationContextInitializer
+Feture,Promise
+它们都是用在多线程之间的,进行数据传递。
+
+Feture相当于一个占位符,代表一个操作将来的结果。一般通过get可以直接阻塞得到结果,或者让它异步执行然后通过callback回调结果。
+
+但如果回调中嵌入了回调呢?如果层次很深,就是回调地狱。Java中的CompletableFuture其实就是Promise,用来解决回调地狱问题。Promise是为了让代码变得优美而存在的。
+
+Selector
+根据一系列条件,获得相应的同类资源。它比较像Factory,但只处理单项资源。
+
+X509CertSelector
+NodeSelector
+Reporter
+用来汇报某些执行结果。
+
+ExtentHtmlReporter
+MetricReporter
+Constants
+一般用于常量列表。
+
+Accessor
+封装了一系列get和set方法的类。像lombok就有Accessors注解,生成这些方法。但Accessor类一般是要通过计算来完成get和set,而不是直接操作变量。这适合比较复杂的对象存取服务。
+
+ComponentAccessor
+StompHeaderAccessor
+Generator
+生成器,一般用于生成代码,生成id等。
+
+CodeGenerator
+CipherKeyGenerator
@@ -95,17 +114,4 @@
### 绘图工具
- [draw.io](https://www.draw.io/)
-- keynote
-
-再分享我整理汇总的一些 Java 面试相关资料(亲自验证,严谨科学!别再看网上误导人的垃圾面试题!!!),助你拿到更多 offer!
-
-
-
-[点击获取更多经典必读电子书!](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247497273&idx=1&sn=b0f1e2e03cd7de3ce5d93cc8793d6d88&chksm=fa832459cdf4ad4fb046c0beb7e87ecea48f338278846679ef65238af45f0a135720e7061002&token=766333302&lang=zh_CN#rd)
-
-2023年最新Java学习路线一条龙:
-
-[](https://www.nowcoder.com/discuss/353159357007339520?sourceSSR=users)
-
-
-再给大家推荐一个学习 前后端软件开发 和准备Java 面试的公众号[【JavaEdge】](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247498257&idx=1&sn=b09d88691f9bfd715e000b69ef61227e&chksm=fa832871cdf4a1675d4491727399088ca488fa13e0a3cdf2ece3012265e5a3ef273dff540879&token=766333302&lang=zh_CN#rd)(强烈推荐!)
+- keynote
\ No newline at end of file
diff --git a/rename.md b/rename.md
new file mode 100644
index 0000000000..58e3cb0fb7
--- /dev/null
+++ b/rename.md
@@ -0,0 +1,403 @@
+管理类命名
+写代码,少不了对统一资源的管理,清晰的启动过程可以有效的组织代码。为了让程序运行起来,少不了各种资源的注册、调度,少不了公共集合资源的管理。
+
+Bootstrap,Starter
+一般作为程序启动器使用,或者作为启动器的基类。通俗来说,可以认为是main函数的入口。
+
+AbstractBootstrap
+ServerBootstrap
+MacosXApplicationStarter
+DNSTaskStarter
+Processor
+某一类功能的处理器,用来表示某个处理过程,是一系列代码片段的集合。如果你不知道一些顺序类的代码怎么命名,就可以使用它,显得高大上一些。
+
+CompoundProcessor
+BinaryComparisonProcessor
+DefaultDefaultValueProcessor
+Manager
+对有生命状态的对象进行管理,通常作为某一类资源的管理入口。
+
+AccountManager
+DevicePolicyManager
+TransactionManager
+Holder
+表示持有某个或者某类对象的引用,并可以对其进行统一管理。多见于不好回收的内存统一处理,或者一些全局集合容器的缓存。
+
+QueryHolder
+InstructionHolder
+ViewHolder
+Factory
+毫无疑问,工厂模式的命名,耳熟能详。尤其是Spring中,多不胜数。
+
+SessionFactory
+ScriptEngineFactory
+LiveCaptureFactory
+Provider
+Provider = Strategy + Factory Method。它更高级一些,把策略模式和方法工厂揉在了一块,让人用起来很顺手。Provider一般是接口或者抽象类,以便能够完成子实现。
+
+AccountFeatureProvider
+ApplicationFeatureProviderImpl
+CollatorProvider
+Registrar
+注册并管理一系列资源。
+
+ImportServiceRegistrar
+IKryoRegistrar
+PipelineOptionsRegistrar
+Engine
+一般是核心模块,用来处理一类功能。引擎是个非常高级的名词,一般的类是没有资格用它的。
+
+ScriptEngine
+DataQLScriptEngine
+C2DEngine
+Service
+某个服务。太简单,不忍举例。范围太广,不要滥用哦。
+
+IntegratorServiceImpl
+ISelectionService
+PersistenceService
+Task
+某个任务。通常是个runnable
+
+WorkflowTask
+FutureTask
+ForkJoinTask
+传播类命名
+为了完成一些统计类或者全局类的功能,有些参数需要一传到底。传播类的对象就可以通过统一封装的方式进行传递,并在合适的地方进行拷贝或者更新。
+
+Context
+如果你的程序执行,有一些变量,需要从函数执行的入口开始,一直传到大量子函数执行完毕之后。这些变量或者集合,如果以参数的形式传递,将会让代码变得冗长无比。这个时候,你就可以把变量统一塞到Context里面,以单个对象的形式进行传递。
+
+在Java中,由于ThreadLocal的存在,Context甚至可以不用在参数之间进行传递。
+
+AppContext
+ServletContext
+ApplicationContext
+Propagator
+传播,繁殖。用来将context中传递的值进行复制,添加,清除,重置,检索,恢复等动作。通常,它会提供一个叫做propagate的方法,实现真正的变量管理。
+
+TextMapPropagator
+FilePropagator
+TransactionPropagator
+回调类命名
+使用多核可以增加程序运行的效率,不可避免的引入异步化。我们需要有一定的手段,获取异步任务执行的结果,对任务执行过程中的关键点进行检查。回调类API可以通过监听、通知等形式,获取这些事件。
+
+Handler,Callback,Trigger,Listener
+callback通常是一个接口,用于响应某类消息,进行后续处理;Handler通常表示持有真正消息处理逻辑的对象,它是有状态的;tigger触发器代表某类事件的处理,属于Handler,通常不会出现在类的命名中;Listener的应用更加局限,通常在观察者模式中用来表示特定的含义。
+
+ChannelHandler
+SuccessCallback
+CronTrigger
+EventListener
+Aware
+Aware就是感知的意思,一般以该单词结尾的类,都实现了Aware接口。拿spring来说,Aware 的目的是为了让bean获取spring容器的服务。具体回调方法由子类实现,比如ApplicationContextAware。它有点回调的意思。
+
+ApplicationContextAware
+ApplicationStartupAware
+ApplicationEventPublisherAware
+监控类命名
+现在的程序都比较复杂,运行状态监控已经成为居家必备之良品。监控数据的收集往往需要侵入到程序的边边角角,如何有效的与正常业务进行区分,是非常有必要的。
+
+Metric
+表示监控数据。不要用Monitor了,比较丑。
+
+TimelineMetric
+HistogramMetric
+Metric
+Estimator
+估计,统计。用于计算某一类统计数值的计算器。
+
+ConditionalDensityEstimator
+FixedFrameRateEstimator
+NestableLoadProfileEstimator
+Accumulator
+累加器的意思。用来缓存累加的中间计算结果,并提供读取通道。
+
+AbstractAccumulator
+StatsAccumulator
+TopFrequencyAccumulator
+Tracker
+一般用于记录日志或者监控值,通常用于apm中。
+
+VelocityTracker
+RocketTracker
+MediaTracker
+内存管理类命名
+如果你的应用用到了自定义的内存管理,那么下面这些名词是绕不开的。比如Netty,就实现了自己的内存管理机制。
+
+Allocator
+与存储相关,通常表示内存分配器或者管理器。如果你得程序需要申请有规律得大块内存,allocator是你得不二选择。
+
+AbstractByteBufAllocator
+ArrayAllocator
+RecyclingIntBlockAllocator
+Chunk
+表示一块内存。如果你想要对一类存储资源进行抽象,并统一管理,可以采用它。
+
+EncryptedChunk
+ChunkFactory
+MultiChunk
+Arena
+英文是舞台、竞技场的意思。由于Linux把它用在内存管理上发扬光大,它普遍用于各种存储资源的申请、释放与管理。为不同规格的存储chunk提供舞台,好像也是非常形象的表示。
+
+关键是,这个词很美,作为后缀让类名显得很漂亮。
+
+BookingArena
+StandaloneArena
+PoolArena
+Pool
+表示池子。内存池,线程池,连接池,池池可用。
+
+ConnectionPool
+ObjectPool
+MemoryPool
+过滤检测类命名
+程序收到的事件和信息是非常多的,有些是合法的,有些需要过滤扔掉。根据不同的使用范围和功能性差别,过滤操作也有多种形式。你会在框架类代码中发现大量这样的名词。
+
+Pipeline,Chain
+一般用在责任链模式中。Netty,Spring MVC,Tomcat等都有大量应用。通过将某个处理过程加入到责任链的某个位置中,就可以接收前面处理过程的结果,强制添加或者改变某些功能。就像Linux的管道操作一样,最终构造出想要的结果。
+
+Pipeline
+ChildPipeline
+DefaultResourceTransformerChain
+FilterChain
+Filter
+过滤器,用来筛选某些满足条件的数据集,或者在满足某些条件的时候执行一部分逻辑。如果和责任链连接起来,则通常能够实现多级的过滤。
+
+FilenameFilter
+AfterFirstEventTimeFilter
+ScanFilter
+Interceptor
+拦截器,其实和Filter差不多。不过在Tomcat中,Interceptor可以拿到controller对象,但filter不行。拦截器是被包裹在过滤器中。
+
+HttpRequestInterceptor
+Evaluator
+英文里是评估器的意思。可用于判断某些条件是否成立,一般内部方法evaluate会返回bool类型。比如你传递进去一个非常复杂的对象,或者字符串,进行正确与否的判断。
+
+ScriptEvaluator
+SubtractionExpressionEvaluator
+StreamEvaluator
+Detector
+探测器。用来管理一系列探测性事件,并在发生的时候能够进行捕获和响应。比如Android的手势检测,温度检测等。
+
+FileHandlerReloadingDetector
+TransformGestureDetector
+ScaleGestureDetector
+结构类命名
+除了基本的数据结构,如数组、链表、队列、栈等,其他更高一层的常见抽象类,能够大量减少大家的交流,并能封装常见的变化。
+
+Cache
+这个没啥好说的,就是缓存。大块的缓存。常见的缓存算法有LRU、LFU、FIFO等。
+
+LoadingCache
+EhCacheCache
+Buffer
+buffer是缓冲,不同于缓存,它一般用在数据写入阶段。
+
+ByteBuffer
+RingBuffer
+DirectByteBuffer
+Composite
+将相似的组件进行组合,并以相同的接口或者功能进行暴露,使用者不知道这到底是一个组合体还是其他个体。
+
+CompositeData
+CompositeMap
+ScrolledComposite
+Wrapper
+用来包装某个对象,做一些额外的处理,以便增加或者去掉某些功能。
+
+IsoBufferWrapper
+ResponseWrapper
+MavenWrapperDownloader
+Option, Param,Attribute
+用来表示配置信息。说实话,它和Properties的区别并不大,但由于Option通常是一个类,所以功能可以扩展的更强大一些。它通常比Config的级别更小,关注的也是单个属性的值。Param一般是作为参数存在,对象生成的速度要快一些。
+
+SpecificationOption
+SelectOption
+AlarmParam
+ModelParam
+Tuple
+元组的概念。由于Java中缺乏元组结构,我们通常会自定义这样的类。
+
+Tuple2
+Tuple3
+Aggregator
+聚合器,可以做一些聚合计算。比如分库分表中的sum,max,min等聚合函数的汇集。
+
+BigDecimalMaxAggregator
+PipelineAggregator
+TotalAggregator
+Iterator
+迭代器。可以实现Java的迭代器接口,也可以有自己的迭代方式。在数据集很大的时候,需要进行深度遍历,迭代器可以说是必备的。使用迭代器还可以在迭代过程中安全的删除某些元素。
+
+BreakIterator
+StringCharacterIterator
+Batch
+某些可以批量执行的请求或者对象。
+
+SavedObjectBatch
+BatchRequest
+Limiter
+限流器,使用漏桶算法或者令牌桶来完成平滑的限流。
+
+DefaultTimepointLimiter
+RateLimiter
+TimeBasedLimiter
+常见设计模式命名
+设计模式是名词的重灾区,这里只列出最常使用的几个。
+
+Strategy
+将抽象部分与它的实现部分分离,使它们都可以独立地变化。策略模式。相同接口,不同实现类,同一方法结果不同,实现策略不同。比如一个配置文件,是放在xml里,还是放在json文件里,都可以使用不同的provider去命名。
+
+RemoteAddressStrategy
+StrategyRegistration
+AppStrategy
+Adapter
+将一个类的接口转换为客户希望的另一个接口,Adapter模式使得原本由于接口不兼容而不能一起工作的那些类一起工作。
+
+不过,相对于传统的适配器进行api转接,如果你的某个Handler里面方法特别的多,可以使用Adapter实现一些默认的方法进行0适配。那么其他类使用的时候,只需要继承Adapter,然后重写他想要重写的方法就可以了。这也是Adapter的常见用法。
+
+ExtendedPropertiesAdapter
+ArrayObjectAdapter
+CardGridCursorAdapter
+Action,Command
+将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化,对请求排队或记录请求日志,以及支持可撤销的操作。
+
+用来表示一系列动作指令,用来实现命令模式,封装一系列动作或者功能。Action一般用在UI操作上,后端框架可以无差别的使用。
+
+在DDD的概念中,CQRS的Command的C,既为Command。
+
+DeleteAction
+BoardCommand
+Event
+表示一系列事件。一般的,在语义上,Action,Command等,来自于主动触发;Event来自于被动触发。
+
+ObservesProtectedEvent
+KeyEvent
+Delegate
+代理或者委托模式。委托模式是将一件属于委托者做的事情,交给另外一个被委托者来处理。
+
+LayoutlibDelegate
+FragmentDelegate
+Builder
+将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
+
+构建者模式的标准命名。比如StringBuilder。当然StringBuffer是个另类。这也说明了,规则是人定的,人也可以破坏。
+
+JsonBuilder
+RequestBuilder
+Template
+模板方法类的命名。定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
+
+JDBCTemplate
+Proxy
+代理模式。为其他对象提供一种代理以控制对这个对象的访问。
+
+ProxyFactory
+SlowQueryProxy
+解析类命名
+写代码要涉及到大量的字符串解析、日期解析、对象转换等。根据语义和使用场合的区别,它们也分为多种。
+
+Converter,Resolver
+转换和解析。一般用于不同对象之间的格式转换,把一类对象转换成另一类。注意它们语义上的区别,一般特别复杂的转换或者有加载过程的需求,可以使用Resolver。
+
+DataSetToListConverter
+LayoutCommandLineConverter
+InitRefResolver
+MustacheViewResolver
+Parser
+用来表示非常复杂的解析器,比如解析DSL。
+
+SQLParser
+JSONParser
+Customizer
+用来表示对某个对象进行特别的配置。由于这些配置过程特别的复杂,值得单独提取出来进行自定义设置。
+
+ContextCustomizer
+DeviceFieldCustomizer
+Formatter
+格式化类。主要用于字符串、数字或者日期的格式化处理工作。
+
+DateFormatter
+StringFormatter
+网络类命名
+网络编程的同学,永远绕不过去的几个名词。
+
+Packet
+通常用于网络编程中的数据包。
+
+DhcpPacket
+PacketBuffer
+Protocol
+同样用户网络编程中,用来表示某个协议。
+
+RedisProtocol
+HttpProtocol
+Encoder、Decoder、Codec
+编码解码器
+
+RedisEncoder
+RedisDecoder
+RedisCodec
+Request,Response
+一般用于网络请求的进和出。如果你用在非网络请求的方法上,会显得很怪异。
+
+CRUD命名
+这个就有意思多了,统一的Controller,Service,Repository,没什么好说的。但你一旦用了DDD,那就得按照DDD那一套的命名来。
+
+由于DDD不属于通用编程范畴,它的名词就不多做介绍了。
+
+其他
+Util,Helper
+都表示工具类,Util一般是无状态的,Helper以便需要创建实例才能使用。但是一般没有使用Tool作为后缀的。
+
+HttpUtil
+TestKeyFieldHelper
+CreationHelper
+Mode,Type
+看到mode这个后缀,就能猜到这个类大概率是枚举。它通常把常见的可能性都列到枚举类里面,其他地方就可以引用这个Mode。
+
+OperationMode
+BridgeMode
+ActionType
+Invoker,Invocation
+invoker是一类接口,通常会以反射或者触发的方式,执行一些具体的业务逻辑。通过抽象出invoke方法,可以在invoke执行之前对入参进行记录或者处理;在invoke执行之后对结果和异常进行处理,是AOP中常见的操作方式。
+
+MethodInvoker
+Invoker
+ConstructorInvocation
+Initializer
+如果你的应用程序,需要经过大量的初始化操作才能启动,那就需要把它独立出来,专门处理初始化动作。
+
+MultiBackgroundInitialize
+ApplicationContextInitializer
+Feture,Promise
+它们都是用在多线程之间的,进行数据传递。
+
+Feture相当于一个占位符,代表一个操作将来的结果。一般通过get可以直接阻塞得到结果,或者让它异步执行然后通过callback回调结果。
+
+但如果回调中嵌入了回调呢?如果层次很深,就是回调地狱。Java中的CompletableFuture其实就是Promise,用来解决回调地狱问题。Promise是为了让代码变得优美而存在的。
+
+Selector
+根据一系列条件,获得相应的同类资源。它比较像Factory,但只处理单项资源。
+
+X509CertSelector
+NodeSelector
+Reporter
+用来汇报某些执行结果。
+
+ExtentHtmlReporter
+MetricReporter
+Constants
+一般用于常量列表。
+
+Accessor
+封装了一系列get和set方法的类。像lombok就有Accessors注解,生成这些方法。但Accessor类一般是要通过计算来完成get和set,而不是直接操作变量。这适合比较复杂的对象存取服务。
+
+ComponentAccessor
+StompHeaderAccessor
+Generator
+生成器,一般用于生成代码,生成id等。
+
+CodeGenerator
+CipherKeyGenerator