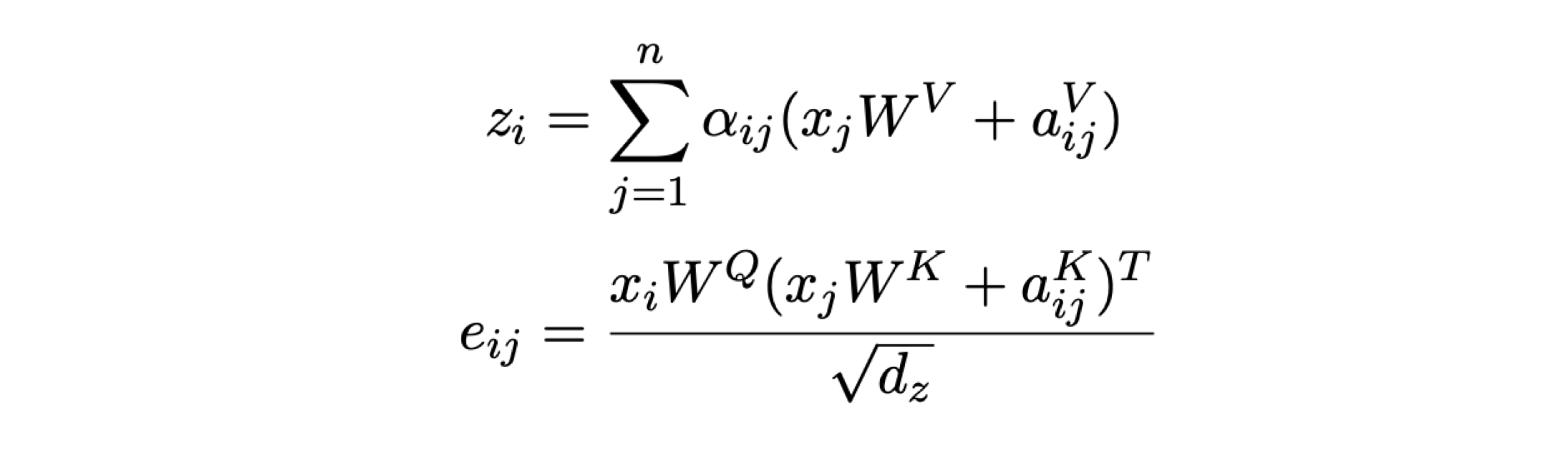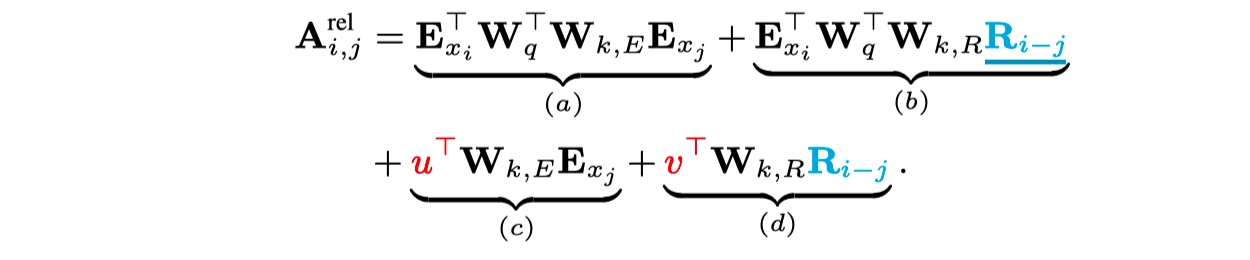Folders and files Name Name Last commit message
Last commit date
parent directory
View all files
On Layer Normalization IN The Transformer A Rchitecture Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Huishuai Zhang, Yanyan Lan, Liwei Wang, Tie-Yan Liu .
the reason of post-LN Transformer needing warm-up process in theoretically and empirically.
The Position of Layer Normalization in residual connections is significant.
$\left|\frac{\partial \tilde{\mathcal{L}}}{\partial W^{2, L}}\right|_{F} \leq \mathcal{O}(d \sqrt{\ln d})$ $\left|\frac{\partial \tilde{\mathcal{L}}}{\partial W^{2, L}}\right|_{F} \leq \mathcal{O}(d \sqrt{\frac{\ln d}{L}})$
Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View Yiping Lu, Zhuohan Li, Di He, Zhiqing Sun,Bin Dong, Tao Qin, Liwei Wang, Tie-Yan Liu .
Transformer is Ordinary Differential Equation ODE
And change Transformer architecture to FFN-Attention-FFN
Large Memory Layers with Product Keys Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou .
a network about key-value memory layer instead of FC in Transformer
It can reduce computational complexity.
A Tensorized Transformer for Language Modeling Xindian Ma, Peng Zhang, Shuai Zhang, Nan Duan, Yuexian Hou, Dawei Song, Ming Zhou .
parameters sharing + tensor decomposition
block-term tensor decomposition(BTD)
Multi-linear Attention by BTD
reduce computational complexity
Adaptive Attention Span in Transformers Sainbayar Sukhbaatar, Edouard Grave, Piotr Bojanowski, Armand Joulin .
adaptive attention span size reduce unnecessary cost.
origin Attention span $\in [t-S, t)$
In fact, diff head have diff focus. Maybe focus on near info, maybe on global info.
proposal a masking function to control attention span.
$m_{z}(x)=\min \left[\max \left[\frac{1}{R}(R+z-x), 0\right], 1\right]$ $a_{t r}=\frac{m_{z}(t-r) \exp \left(s_{t r}\right)}{\sum_{q=t-S}^{t-1} m_{z}(t-q) \exp \left(s_{t q}\right)}$
Universal Transformers Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, Łukasz Kaiser .
Recurrent Architectures -> time loop
Transition functions -> share parameters
adaptive computational time -> dynamic adjust step time
Depth-Adaptive Transformer Maha Elbayad, Jiatao Gu, Edouard Grave, Michael Auli .
depth adaptive Transformer
not enough every token run -> last layer
$$\forall n, p\left(y_{t+1} | h_{t}^{n}\right)=\operatorname{softmax}\left(W_{n} h_{t}^{n}\right)$$ disadvantages: O(N), classification sole.
origin method: dynamic calculate
Aligned Training: know 1~i-1 layers all hidden parameters
$$\mathrm{LL}{t}^{n}=\log p\left(y {t} | h_{t-1}^{n}\right), \quad \mathrm{LL}^{n}=\sum_{t=1}^{|\boldsymbol{y}|} \mathrm{LL}{t}^{n}, \quad \mathcal{L} {d e c}(\boldsymbol{x}, \boldsymbol{y})=-\frac{1}{\sum_{n} \omega_{n}} \sum_{n=1}^{N} \omega_{n} \mathrm{LL}^{n}$$
Mixed Training: i+1 copy i layer
$$\mathrm{LL}{t}=\log p\left(y {t} | h_{t-1}^{n}\right), \quad \mathrm{LL}=\sum_{t=1}^{|\boldsymbol{y}|} \mathrm{LL}{t}, \quad \mathcal{L} {\operatorname{dec}}(\boldsymbol{x}, \boldsymbol{y})=-\frac{1}{M} \sum_{m=1}^{M} \mathrm{LL}$$
Paper Method: Depth-Adaptive
Sequence-specific depth: the same sequence quit same time
likelihood-based
$$q^{*}(\boldsymbol{x}, \boldsymbol{y})=\delta\left(\arg \max _{n} \mathrm{LL}^{n}-\lambda n\right)$$
correctness-based
$$C^{n}=#\left{t\left|y_{t}=\arg \max {y} p\left(y | h {t-1}^{n}\right}, \quad q^{*}(\boldsymbol{x}, \boldsymbol{y})=\delta\left(\arg \max _{n} C^{n}-\lambda n\right)\right.\right.$$
token-specific depth
Multinomial
Poisson Binomial
likelihood-based
$$\begin{array}{l}{\kappa\left(t, t^{\prime}\right)=e^{-\frac{\left|t-t^{\prime}\right|^{2}}{\sigma}}, \text { smoothLL }{t}^{n}=\sum {t^{\prime}} \kappa\left(t, t^{\prime}\right) \mathrm{LL}{t^{\prime}}^{n}} \ {q {t}^{*}(\boldsymbol{x}, \boldsymbol{y})=\delta\left(\arg \max {n} \operatorname{smooth} \mathrm{LL} \mathrm{L} {t}^{n}-\lambda n\right)}\end{array}$$
correctness-based
$$\begin{array}{l}{C_{t}^{n}=y_{t}=\arg \max {y} p\left(y | h {t-1}^{n}\right), \operatorname{smooth} \mathrm{C}{t}^{n}=\sum {t^{\prime}} \kappa\left(t, t^{\prime}\right) C_{t}^{n}} \ {q_{t}^{*}(\boldsymbol{x}, \boldsymbol{y})=\delta\left(\arg \max {n} \operatorname{smooth} \mathrm{C} {t}^{n}-\lambda n\right)}\end{array}$$
confidence threshold
Star-Transformer Qipeng Guo, Xipeng Qiu, Pengfei Liu, Yunfan Shao, Xiangyang Xue, Zheng Zhang .
change the FFN architecture of Transformer to Star architecture
reduce the compute cost and the dataSet need.
Single Headed Attention RNN: Stop Thinking With Your Head Stephen Merity .
Paper style is like a blog.
LSTM + Att + FFN(save memory)
get completable result.
Relative position embedding
Self-Attention with Relative Position Representations Peter Shaw, Jakob Uszkoreit, Ashish Vaswani .
18 年的 NAACL(那就是 17 年底的工作),文章是一篇短文,Peter Shaw, Jakob Uszkoreit, Ashish Vaswani 看名字是发 Transformer 的那批人(想来其他人也不能在那么短时间有那么深的思考 🤔).
他们分别在 QK 乘积计算 Attention bias 的时候和 SoftMax 之后在 Value 后面两处地方加上了一个相对编码(两处参数不共享)。
为了降低复杂度,在不同 head 之间共享了参数。
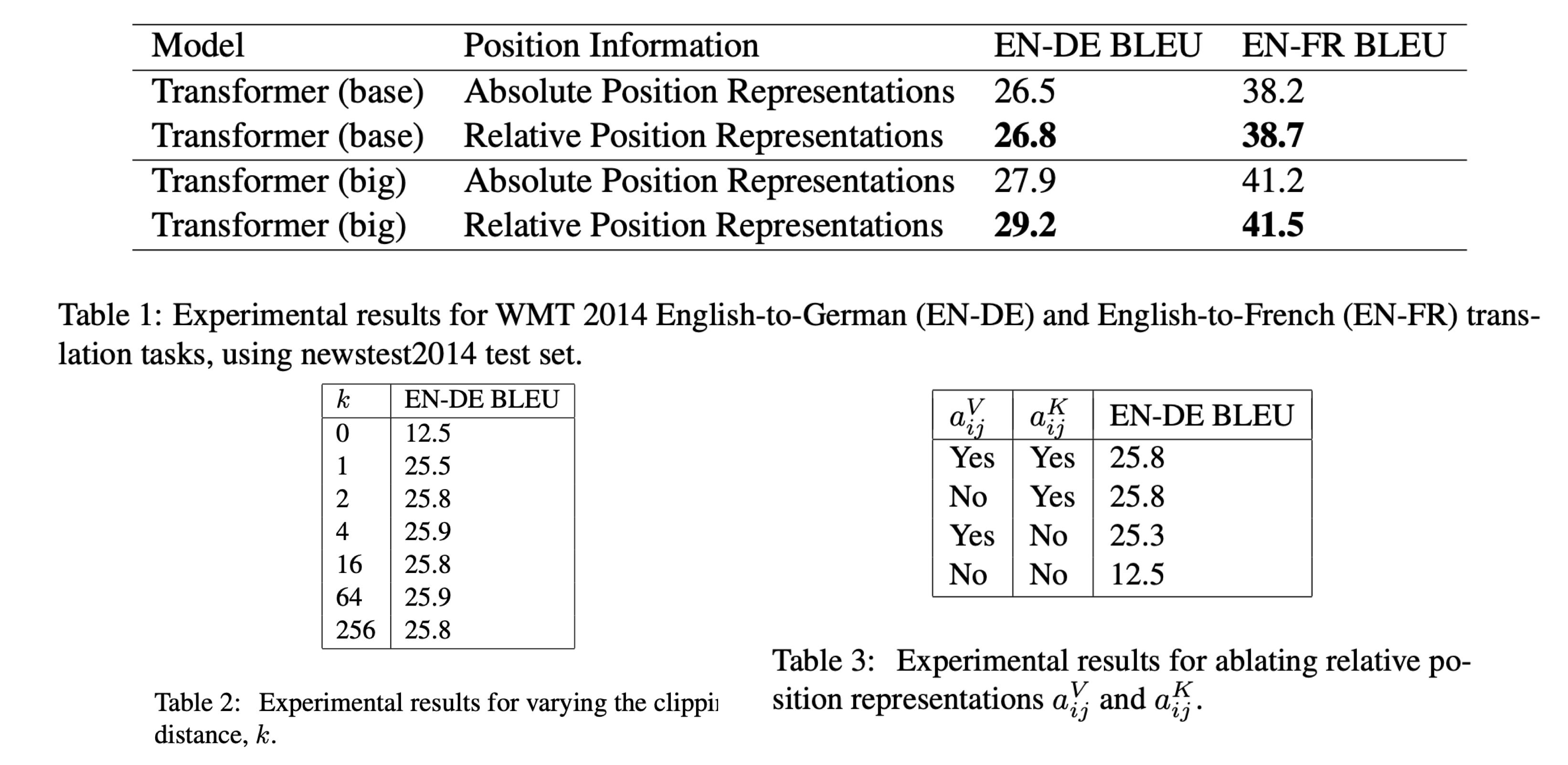
实验显示,在 WMT14 英德数据集上 base model BLEU 提升了 0.3, big model 提升了 1.3.
Ablation 实验中,改变最大位置距离 k,显示 k 从 0-4 增大的过程 performance 有明显的提升,之后再增大 k 提升不明显。
Attention bias 中的相对项提高更多的 performance, 而 SoftMax 之后再 Value 上加的那个相对项提升的性能略少。
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov .
Transformer-XL 的工作现在可以称之上开创性的了。
除却递归更新 blank 的过程,relative position embedding 也是论文的一大亮点.
可能作者在思考的过程中更多是在 recurrent 是 PE 重叠造成的偏移角度出发。
但实际上 relative 的改动对于模型获得句内细粒度层次的信息也是很有帮助的。
与 NAACL18 那篇不同的地方,Transformer-XL 舍弃了在 SoftMax 之后再叠加 Rij。
另外把 Attention Bias 中,另外两项因为引入 PE 产生的表征绝对位置信息的两项替换成不包含位置信息的一维向量(这里专门为前面 recurrent 模式设计的,感觉如果不搭配 Transformer-XL 使用的话这个改动并不一定是最合适的)。
除此之外,为了避免相对引入的巨大计算量,利用类似 AES 中的 shift 操作可以把复杂度降到线性。
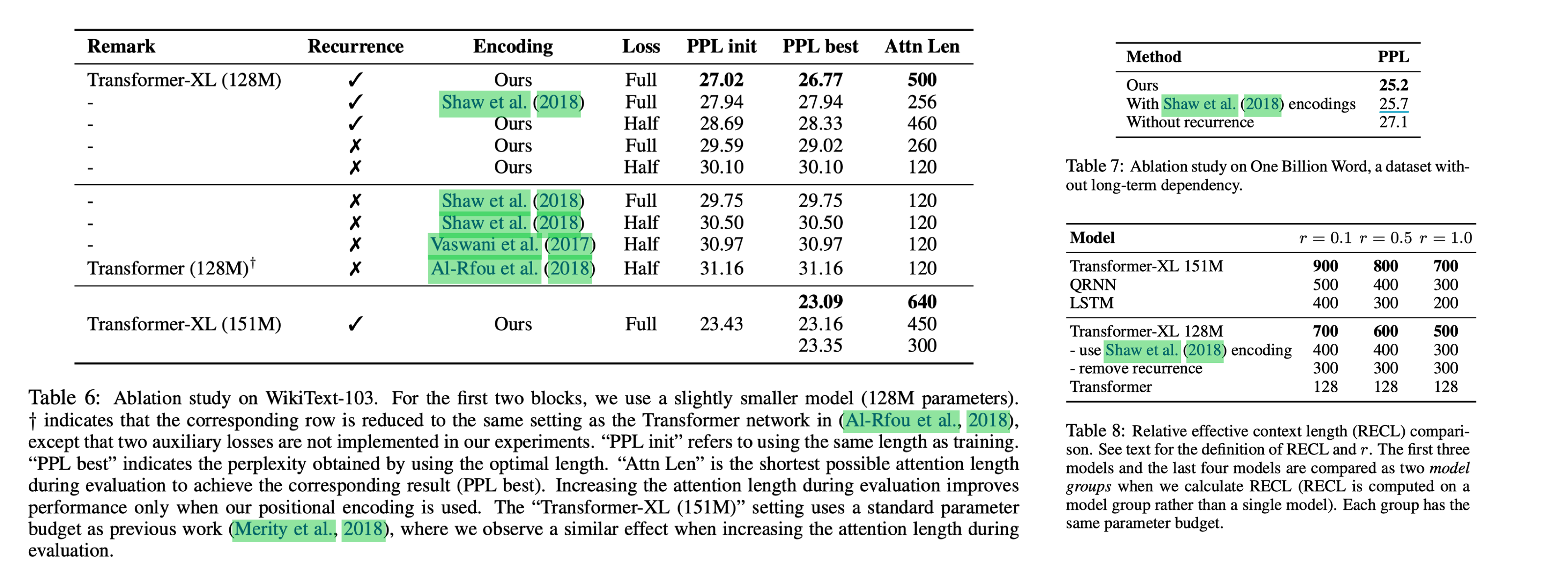
通过 Ablation 实验可以看出相对于 NAACL18 的改进能显著提升效果。
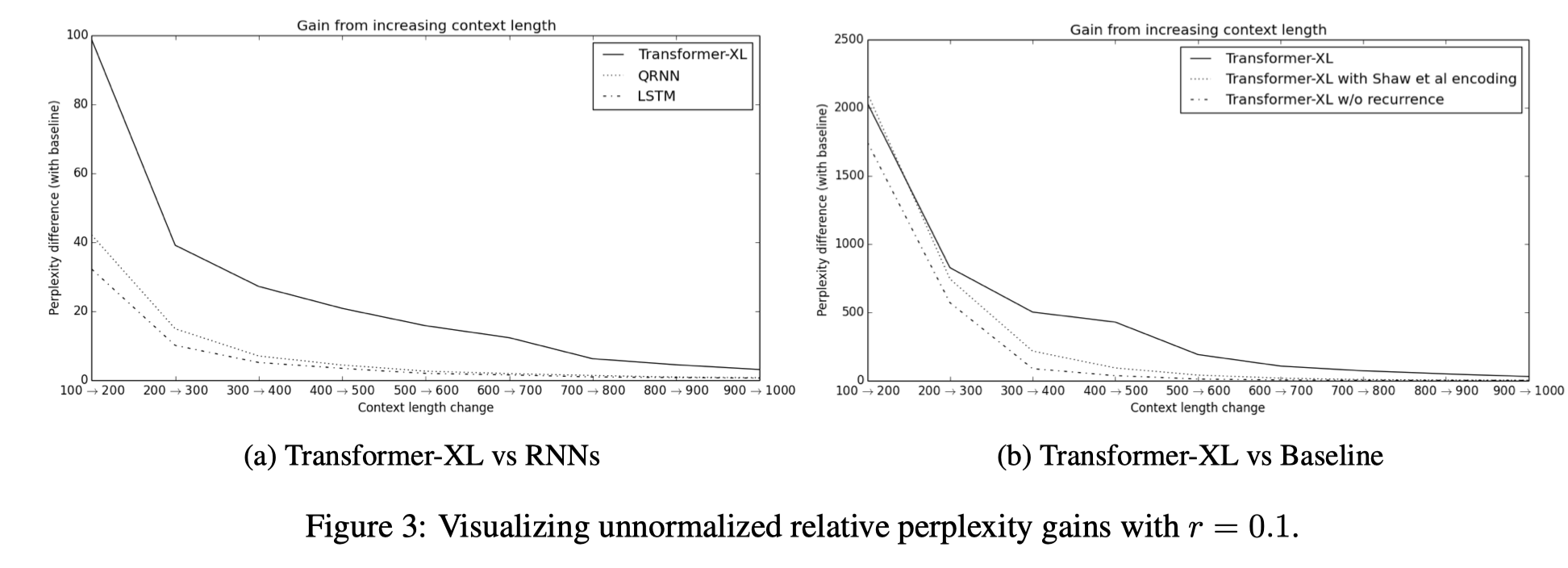
另外通过 RECL 实验也能看出 relative PE 对模型的长程能力有所帮助
RECL 是一个逼近实验,通过测量上下文长度为 c + △,相对长度为 c 时最小 loss 的变化率。
当变化率低于一个阈值的时候就说明大于长度 c 的信息对模型 performance 提升帮助不大。
Encoding word order in complex embeddings Benyou Wang, Donghao Zhao, Christina Lioma, Qiuchi Li, Peng Zhang, Jakob Grue Simonsen .
除了上面一系列从 Attention bias 出发的角度,还有 dalao 从 PE 与 WE 结合方式角度出发做的工作。
从抽象层次看,前面的方法都是在补救因为(WE+PE)乘积项造成的丢失相对位置信息。
如果 WE 和 PE 的结合方式不是加性呢。
今年 ICLR 的有一篇工作就是从这个角度出发,将 WE 于 PE 组合分解成独立的连续函数。
这样在之后的 Attention Bias 计算时也不会丢失 Position 相对信息。
为了达成这个目的,就需要找到一种变换,使得对于任意位置 pos,都有$g(pos+n) = \text{Transform}_n(g(pos))$, 为了降低难度把标准降低成找到一种线性变换 Transform。
而我们的 Embed 除了上面的性质之外应该还是有界的。
这篇文章证明在满足上述条件下,Transform 的唯一解是复数域中的$g(pos)=z_{2} z_{1}^{pos}$, 且 z1 的幅值小于 1。
(这个证明也是有、简单,reviewer 的说法就是有、优美
根据欧拉公式,可以进一步对上述式子进行化简
$g(\text { pos })=z_{2} z_{1}^{\text {pos }}=r_{2} e^{i \theta_{2}}\left(r_{1} e^{i \theta_{1}}\right)^{\text {pos }}=r_{2} r_{1}^{\text {pos }} e^{i\left(\theta_{2}+\theta_{1} \text { pos }\right)}$ 为了偷懒,把 r1 设成 1, 而$e^{ix}$的幅值等于 1,就恒满足 r1 的限定。
于是,进一步化简为 $g(\mathrm{pos})=r e^{i(\omega \mathrm{pos}+\theta)}$
这就是标标准准的虚单位圆的形式,r 为半径,$\theta$为初始幅角,$\frac{\omega}{2\pi}$ 为频率,逆时针旋转。
这个式子又可以化成$f(j, \text { pos })=g_{w e}(j) \odot g_{p e}(j, \text { pos })$ WE 与 PE 的多项式乘积,其中两者所占系数取决于学习到的系数。
于是这相当于一个自适应的调节 WE 和 PE 占比的模式。
实际上我们只需要去学习幅值 r, 频率 w,初始幅角$\theta$ (会造成参数量略微增大)
可以看出 Vanilla Transformer 中的 PE 是上式的一种特殊形式。
为了适应 Embedding 拓展到复数域,RNN,LSTM, Transformer 的计算也应该要拓展到复数域.
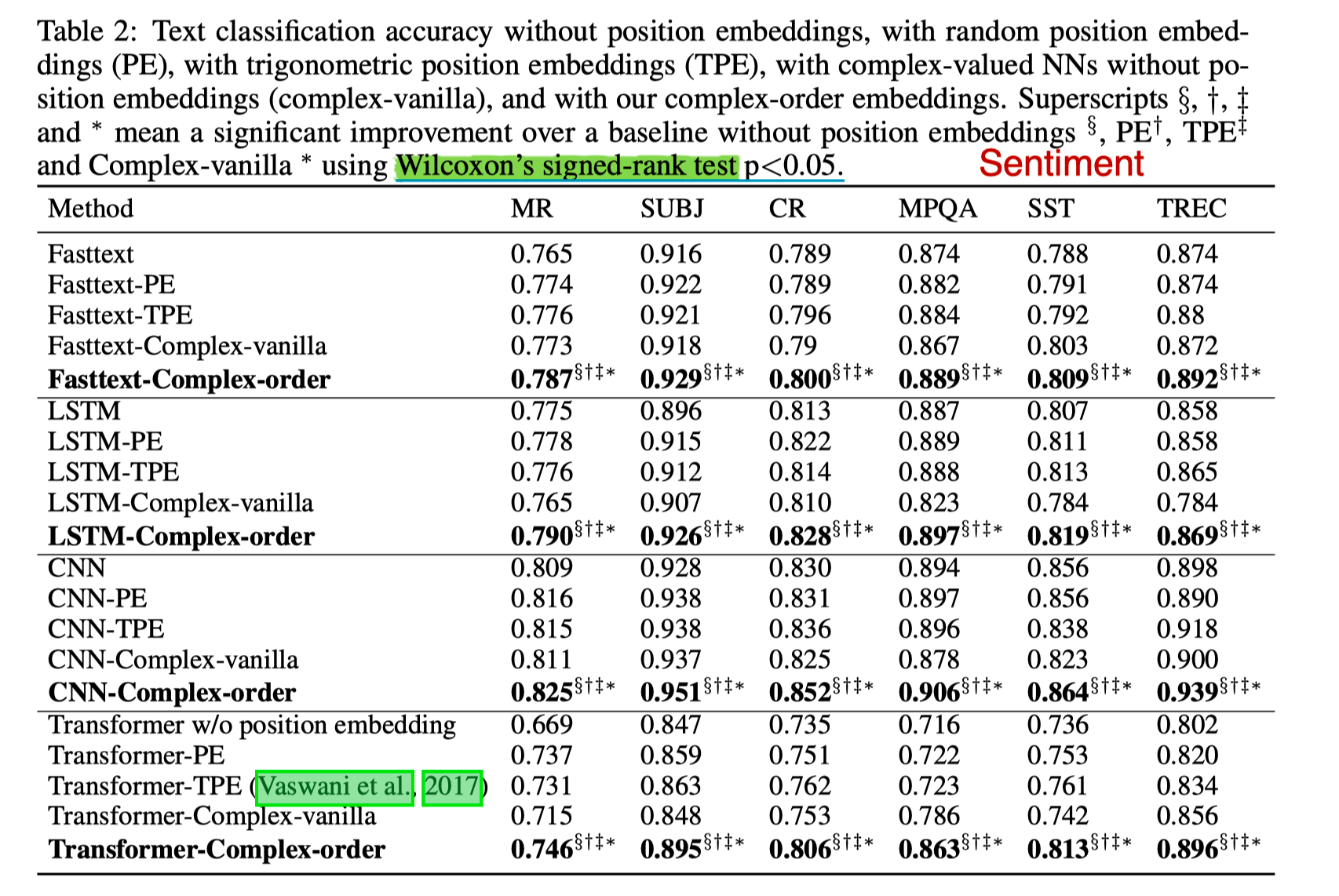
实验部分做了 Text Classification, MT, LM 三个 task。
Text Classification 选了 4 个 sentiment analysis 数据集,一个主观客观分类,一个问题分类,共六个 benchmark。
Baseline 设置 1. without PE; 2. random PE and train; 3. 三角 PE; 4. r 由 pretrain 初始化,w 随机初始化$(-\pi, \pi)$; 5. r 由 pretrain 初始化,w train;
可以看出 performance 中三角 PE 与 Train PE 几乎没什么区别,所以 Vanilla Transformer 使用 Fix 的 PE 也是有一定道理的。
Complex order 对模型有一定提升,但不是特别多。
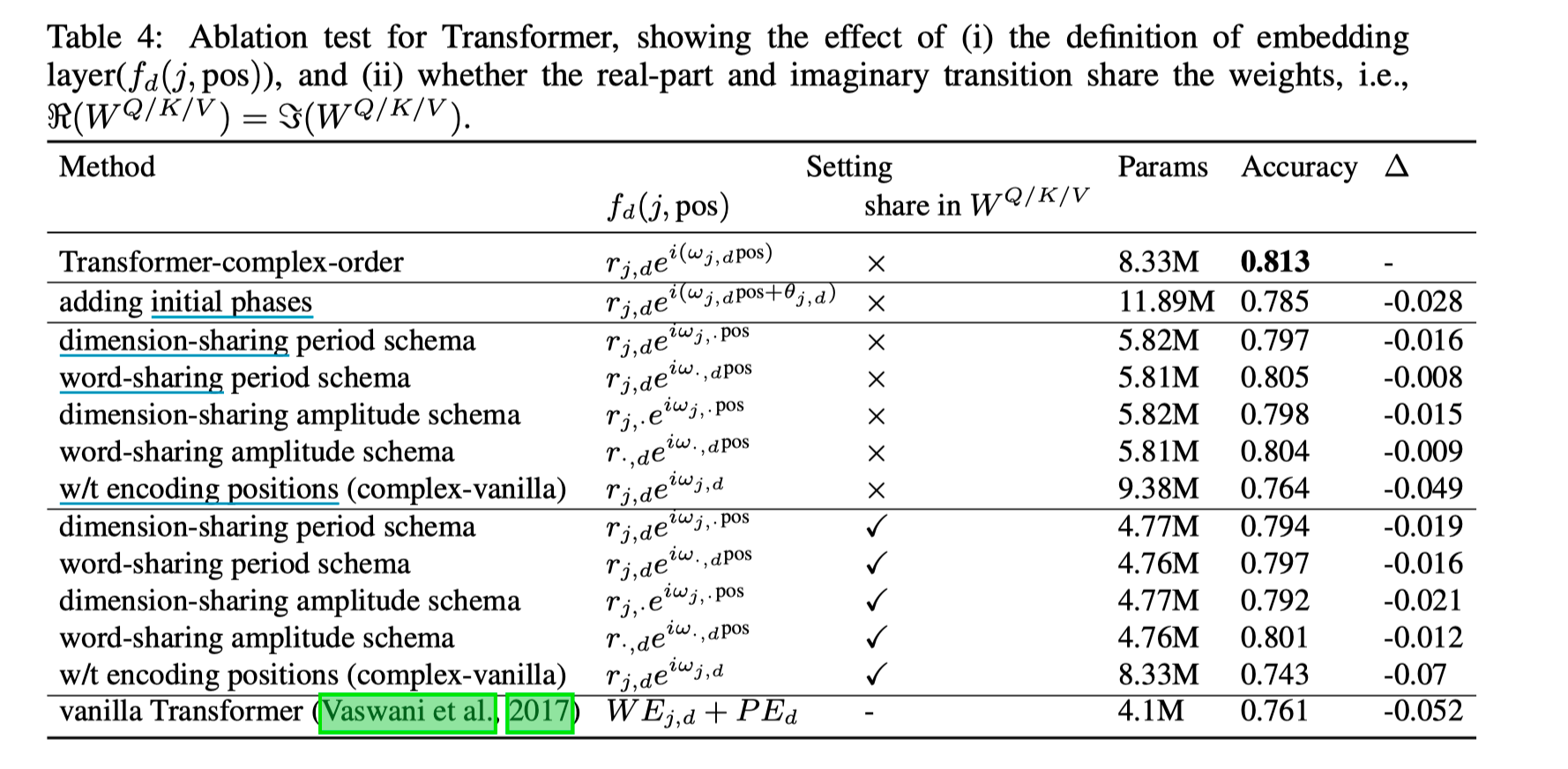
然后为了降低参数量,尝试了几种参数共享的组合
(参数量的增大主要是因为 Transformer 结构扩充到复数域,参数量增大了一倍。但参数增大与 prefermance 关联度不大,共享 W 之后性能几乎不变。
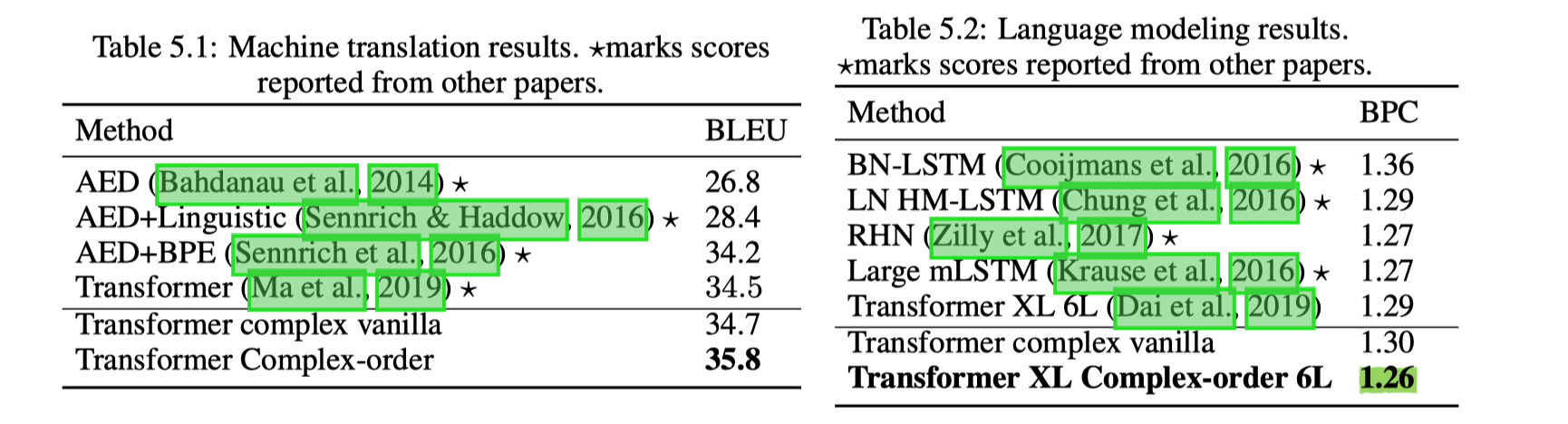
然后在 WMT16 英德和 text8 上测了在 MT 和 LM 上的性能,这两部分性能提升还是很明显的。尤其是 LM 在同等参数量下的对比试验。
(这篇的作者之前也发了几篇关于复数域上 NLP 的应用,之前模型的名字也很有意思 什么 CNM 的 很真实
You can’t perform that action at this time.